Netflix开源组件熔断器Hystrix介绍
文档地址:
https://github.com/Netflix/Hysrtix
https://github.com/Netflix/Hystrix/wiki
什么是Hystrix?
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统中,许多依赖不可避免的会调用失败,超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,提高分布式系统的弹性
分布式项目中,有数十个依赖关系,每个依赖关系在某些时候不可避免地失败 。一般是某个服务异常引起的,相当于“保险丝”,当某个异常条件被触发,直接熔断整个服务,不是等到此服务超时,避免引起服务雪崩
熔断器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控,,某个异常条件被触发,直接熔断整个服务。,向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出吊牌用方法无法处理的异常,就保证了服务调用方的线程不会被长时间占用,避免故障在分布式系统中蔓延,乃至雪崩
为了解决某个微服务的调用响应时间过长或者不可用进而占用越来越多的系统资源引起雪崩效应就需要进行服务熔断和服务降级处理。
提供了熔断、隔离、Fallback、cache、监控等功能
如何实现容错机制,或者说熔断后怎么处理?
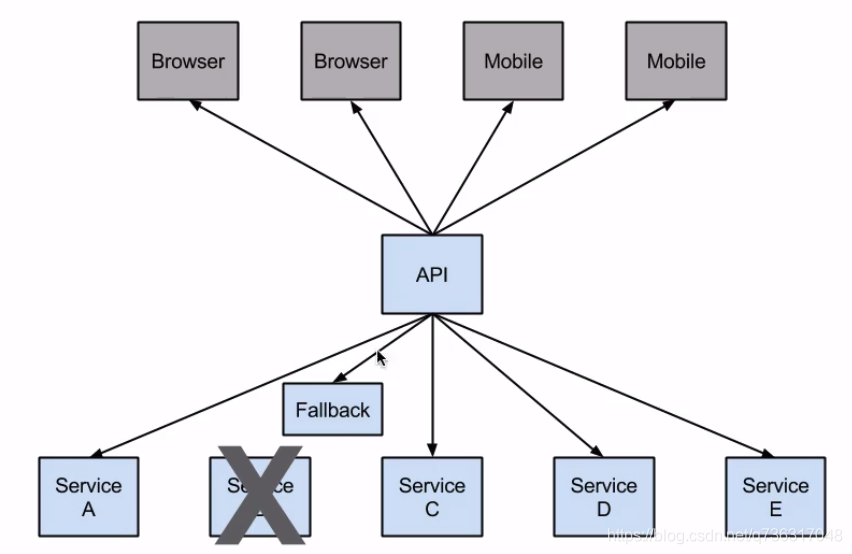
原有微服务,传统方法将传播一个异常,这会导致整个系统崩溃,随着服务数量增加,问题更加负载。将使用Hystrix情况下的Fallback方法功能。定义一个回退方法。方法具有与回调服务相同的返回类型,回退方法将返回一些值
兜底数据
为什么要用?
在一个分布式系统里,一个服务依赖多个服务,可能存在某个服务因为网络超时和峰值异常等关系调用失败
如何保证一个依赖出问题的情况下,不会导致整体服务失败,通过Hystrix就可以解决
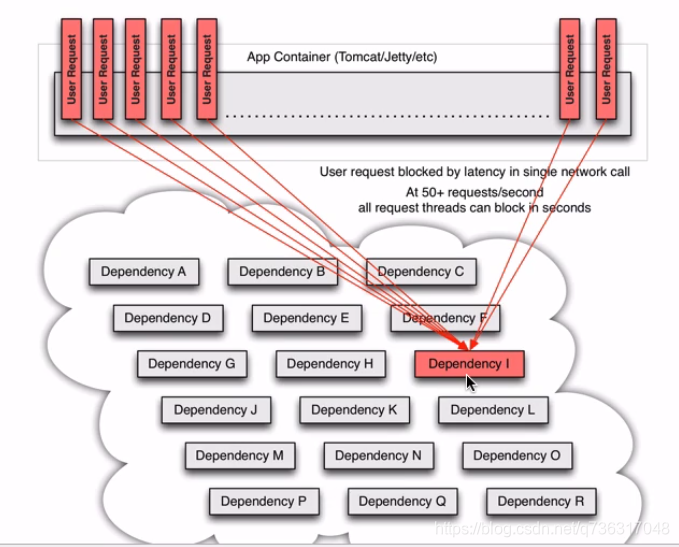
官方演示图
正常用户请求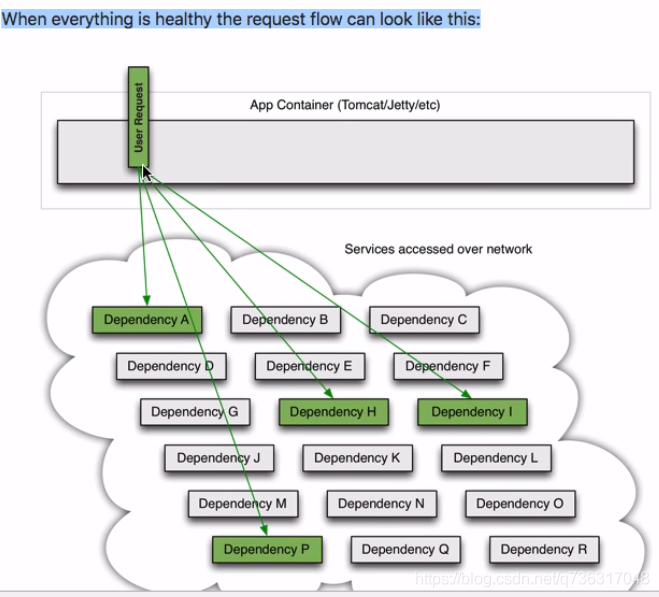
突然某一个服务有问题,或者调用时间很长
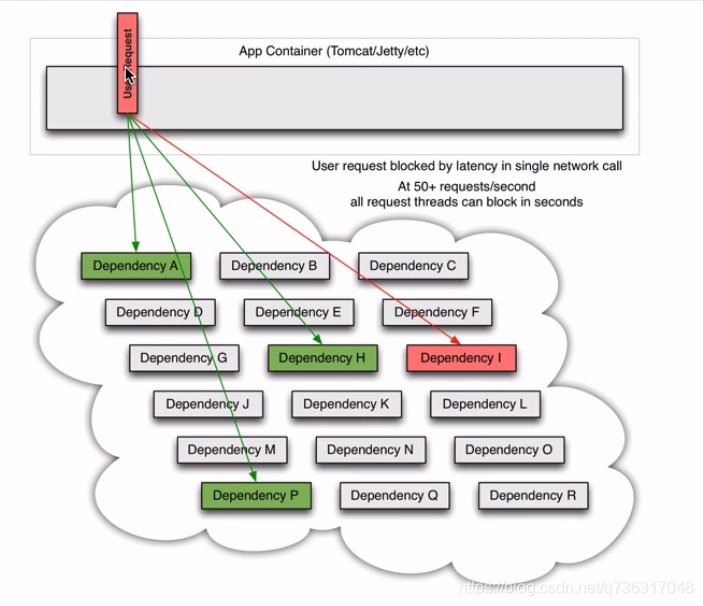
后续比如有50个请求,都阻塞在这里
假如有一万个或一千个都阻塞在这里,整个程序就都挂掉了。如果调取服务超时1秒就断掉,其它服务就不再调取了,等过一会再调取试一下,如果能正常响应就调用,如果还是超时就继续不调取
务就不再调取了,等过一会再调取试一下,如果能正常响应就调用,如果还是超时就继续不调取