实验内容与要求
1.Spark基本知识总结
2.Spark的操作实践:
2.1 Spark的安装部署
2.2 Scala语言编程实践
2.3 基于Spark shell的WordCount实践
2.4 基于IDEA+Maven的Spark编程实践
2.5 pySpark实践
1. Spark基本知识的总结
- Spark借鉴了MapReduce计算框架的优点,解决了MapReduce存在的局限性,支持多种语言编程,支持多种部署方式,并能够很好地融入Hadoop中,完成更多的功能
- Spark的运行架构:
- Driver:是运行application的main函数,可以创建和关闭Sparkcontex
- Sparkcontex:驱动应用,负责与ClusterManager通信,进行资源申请、任务分配等
- ClusterManager:负责申请和管理资源
- Worker:可以运行application的节点,负责执行计算任务
- Executor:某个application运行在worker节点上的一个进程,负责运行组成 Spark
应用的任务,为RDD提供内存式存储
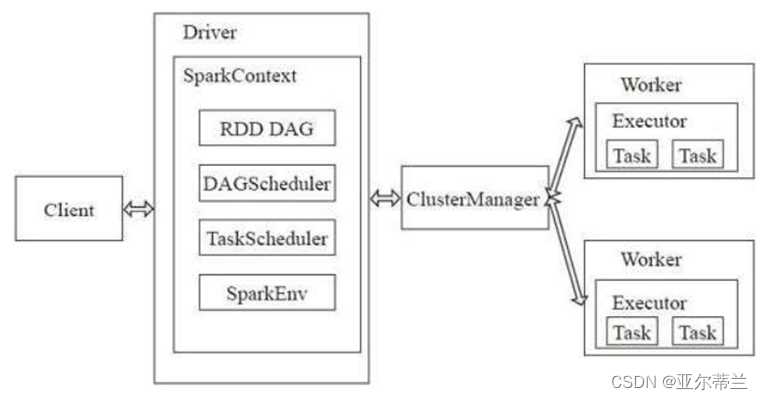
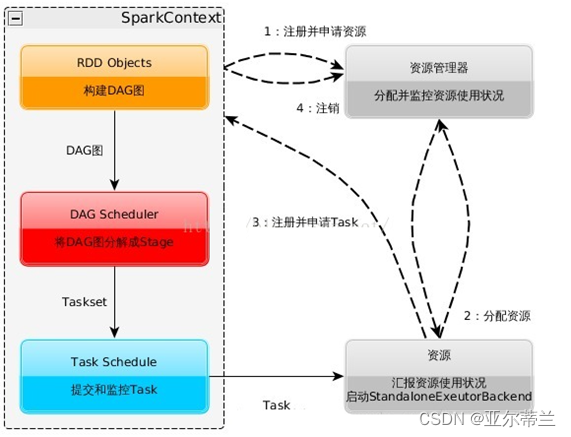
Spark的运行过程: 启动SparkContext,SparkContext向资源管理器申请运行资源,Executor向SparkContext申请Task,SparkContext将应用程序分发给Executor,SparkContext构建DAG图(有向无环图),分解并将Task发送给Executor运行
RDD:弹性分布式数据集
- 是spark中最基本的数据处理模型,是对spark中一个只读数据集合的逻辑描述,但不包括数据集合的具体数据,且只能通过来自HDFS、Hbase等数据源的数据进行创建或对其他RDD进行计算得到
- 主要属性:数据的分区列表、计算每个分区的函数、与其他RDD之间的依赖、优先位置列表、分区策略等
- 两类操作:
转换操作:由一个RDD经过操作得到一个新的RDD,并记录相关转换信息,惰性(不立即执行),当碰到动作操作时,才会一起执行所有转换操作,因此可以减少保存中间结果产生的I/O开销
动作操作:用于向Driver进程返回结果或写入结果文件中,当碰到动作操作时,Spark会建立RDD有向无环图DAG,并分解DAG将具体的任务发送给不同的Executor执行
2. Spark的操作实践
2.1 Spark的安装部署实践
配置文件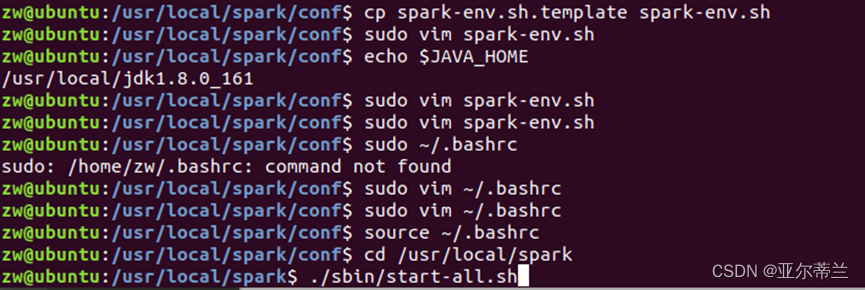
修改spark-env.sh文件内容如下:
修改bashrc文件内容如下:
启动spark,使用jps命令检查是否启动成功
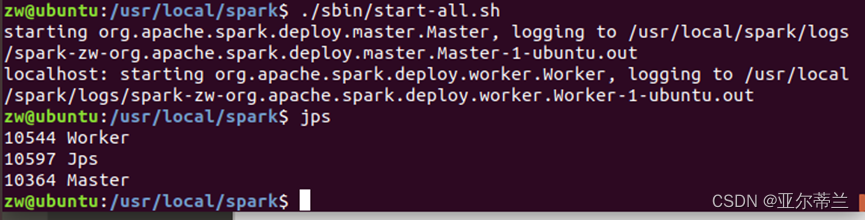
2.2 Scala语言编程
新建变量与变量的操作: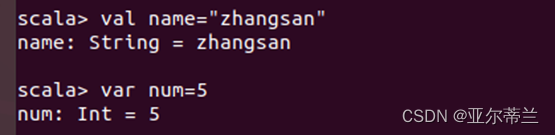
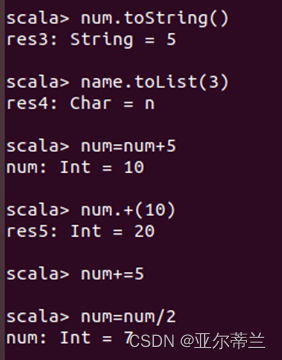
2.3 基于Spark shell的WordCount实践
启动spark shell:
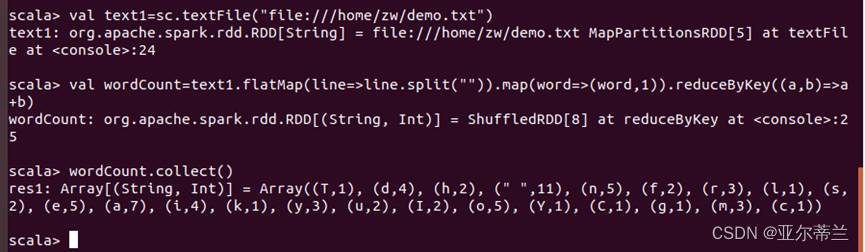
flatMap中split带空格,才能统计单词数:
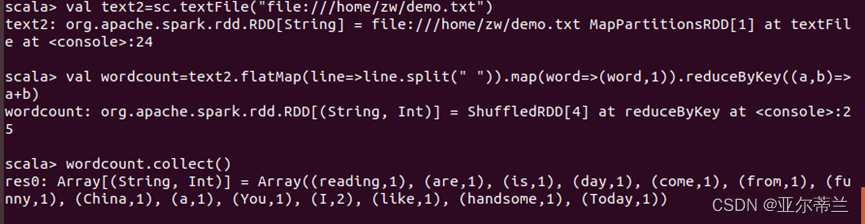
向Hadoop上传文件
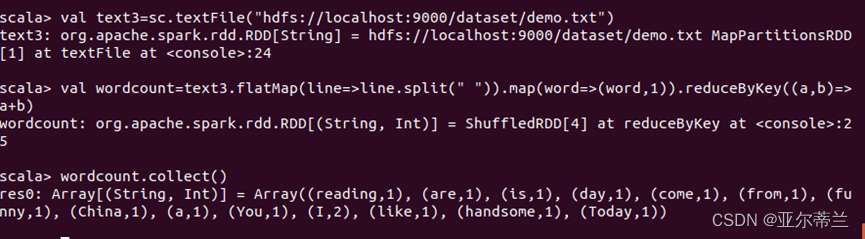
从Hadoop读取数据
2.4基于IDEA+Maven的Spark编程实践
1. 安装scala:
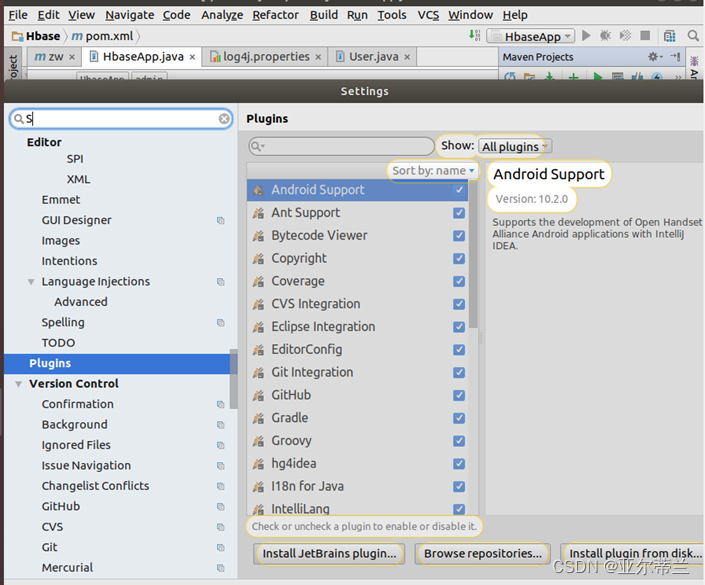
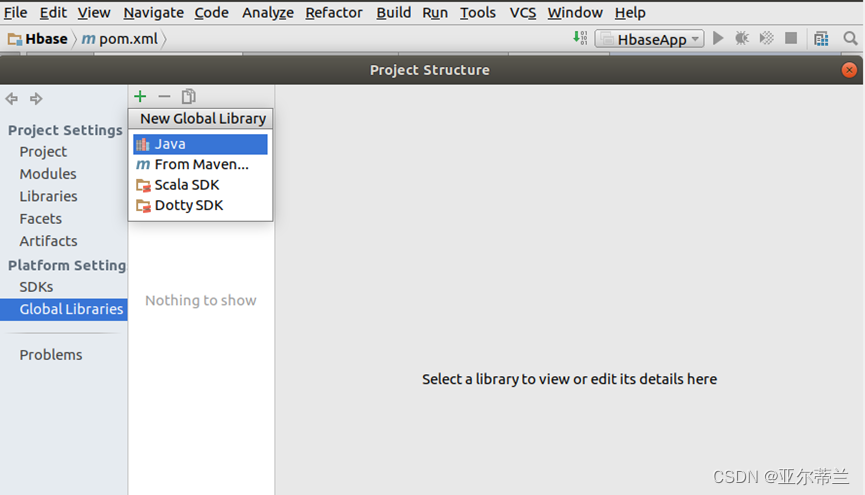
问题:Sacla SDK 文件导入失败: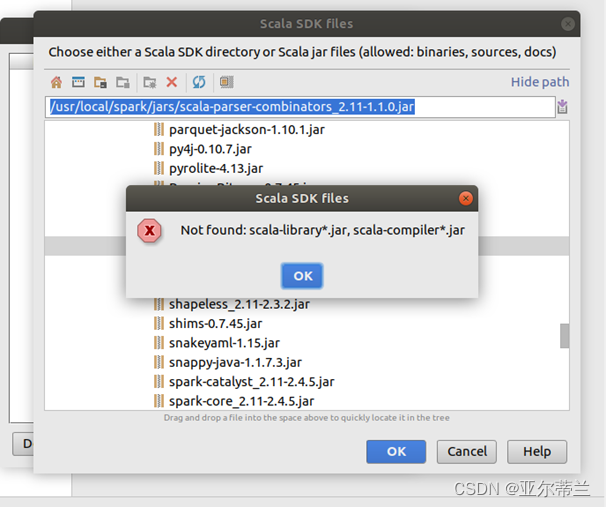
解决办法:选择jar所在的文件夹而不是jar文件:
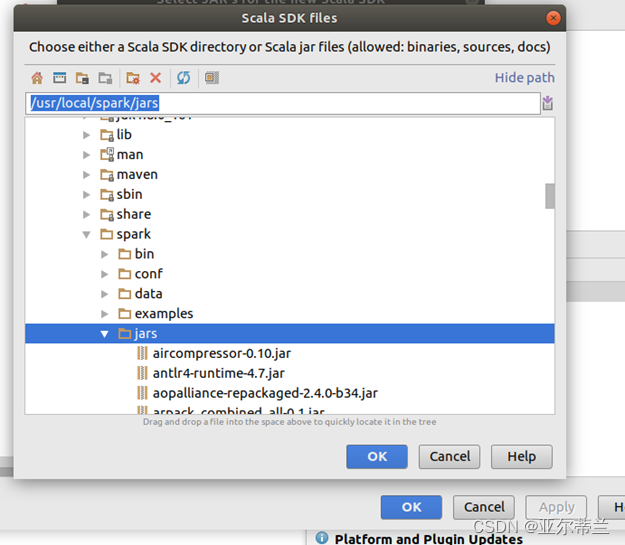
2. 基于Scala的spark程序
问题:hadoop 及 sacal 相关jar包无法导入,projects标签错误
解决办法:右侧maven项目先运行clean 程序,再运行install程序,最后点击reimport 即可: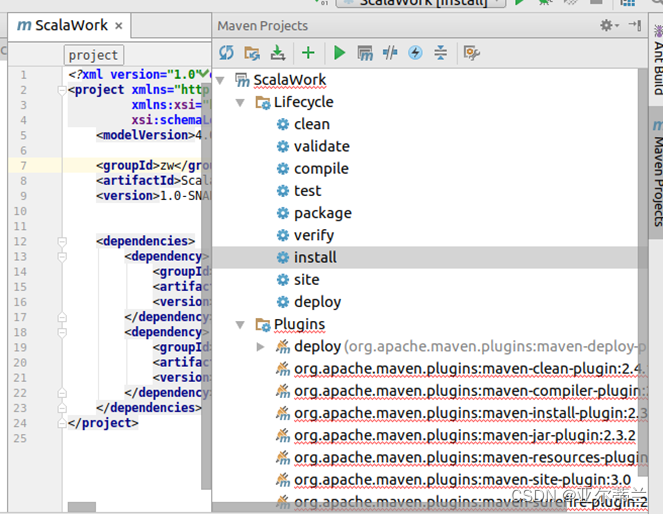
问题:创建的maven 项目没有src文件夹
解决办法:设置maven目录为本地安装的maven目录,点击reimport,再点击download resource: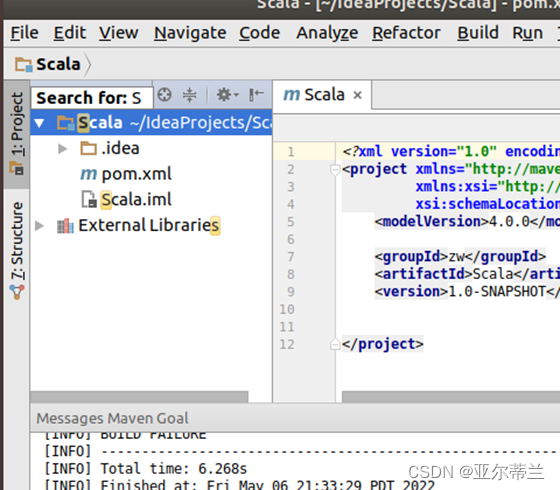
问题:scala文件无法正常创建: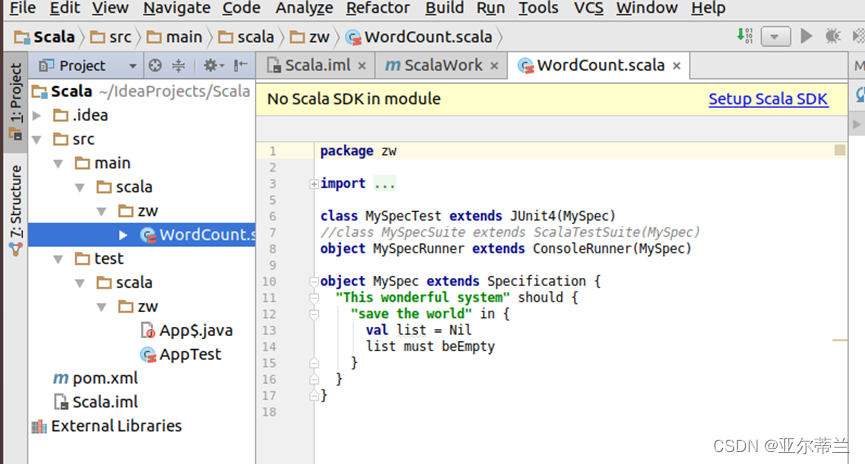
解决办法:重新创建项目配置ScalaSDK: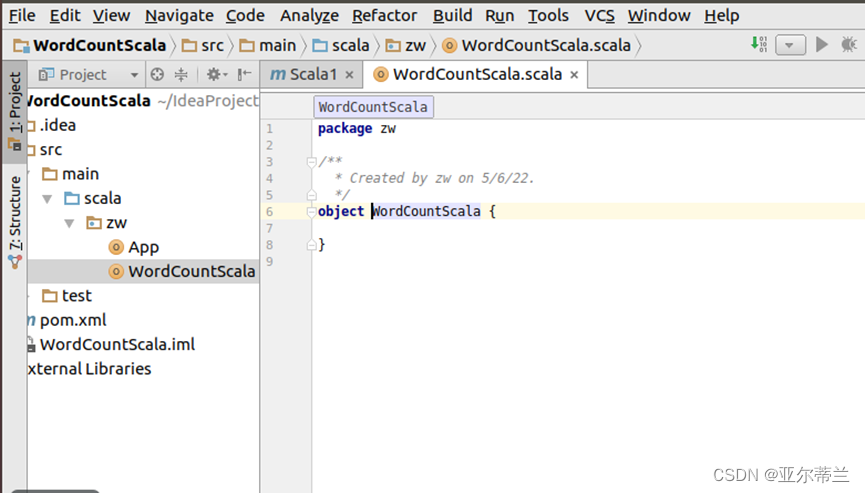
代码: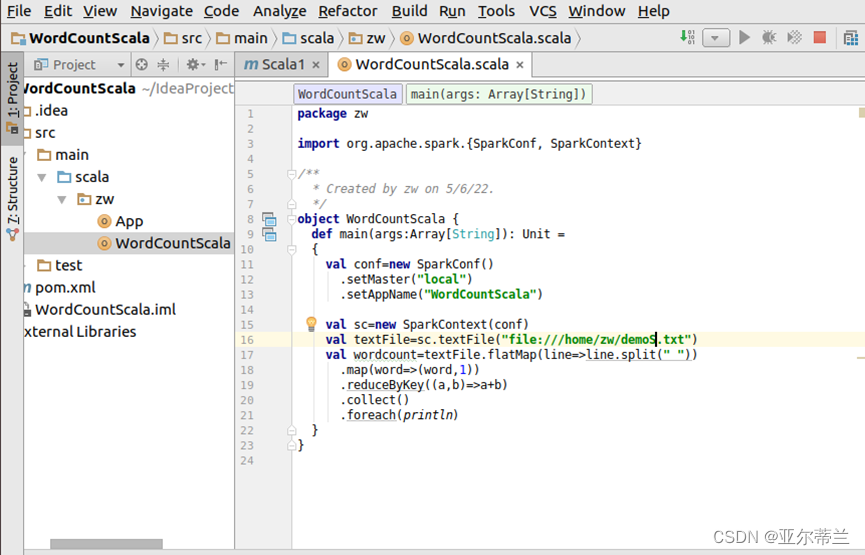
打包运行: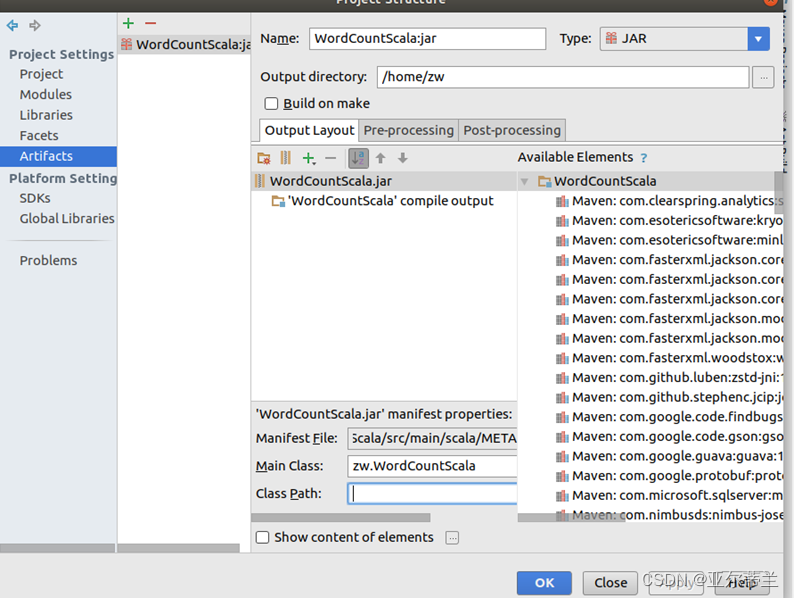
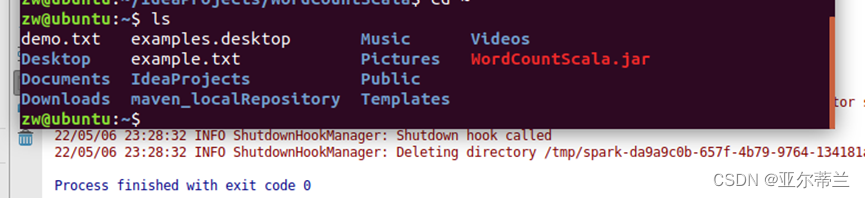
提交jar包运行:
运行结果: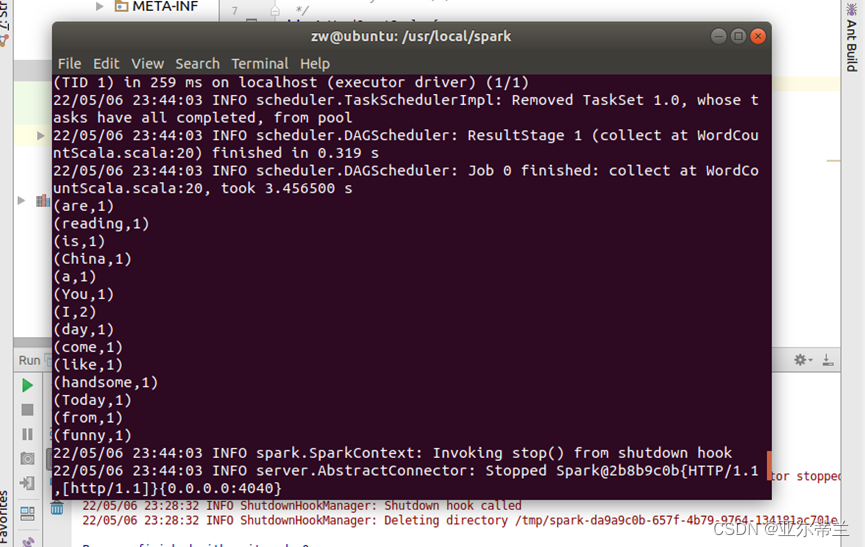
3. 基于java的spark程序:
代码: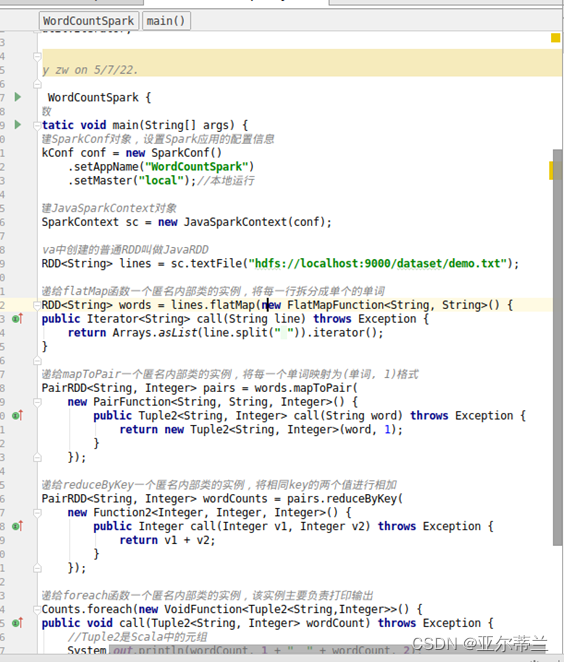
运行结果: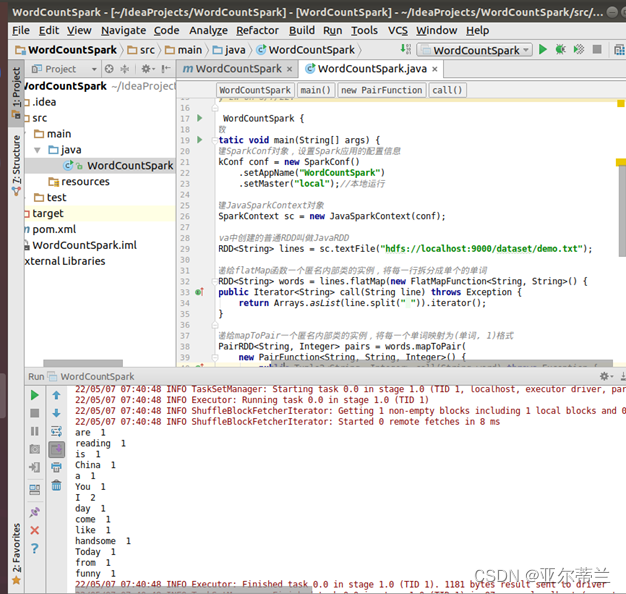
4. Spark与hbase的整合:
Hbase运行失败
问题:找不到表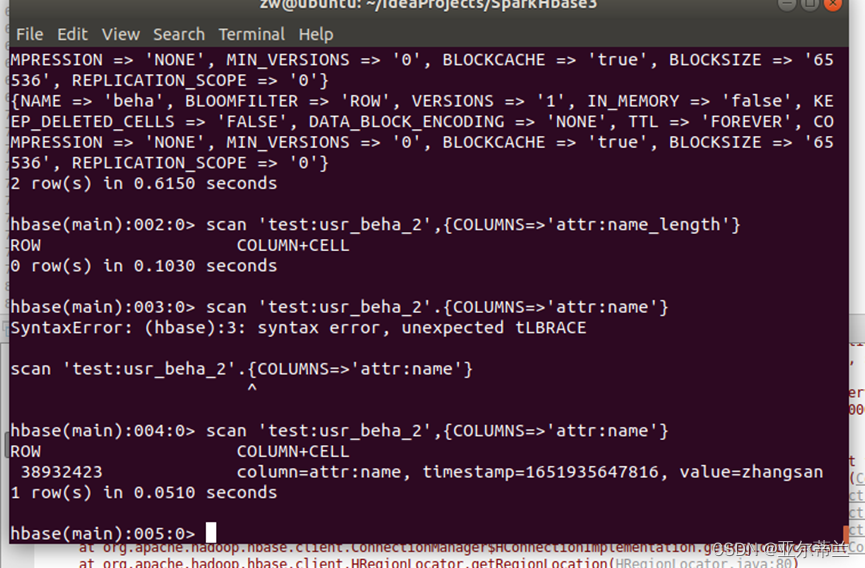
解决办法:在默认命名空间下创建表 usr_beha_test,列族为attr,beha,列name在列族attr下,在name下新建值zhangsan
在hbase代码中修改相关表的名字,重新运行程序: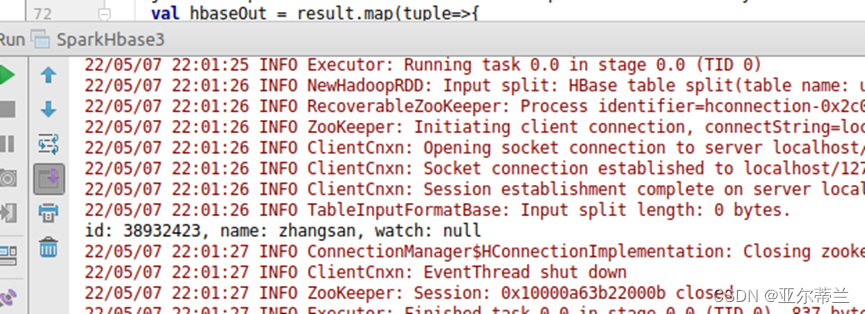
在hbase中查看运行结果:产生列name_length并添加值8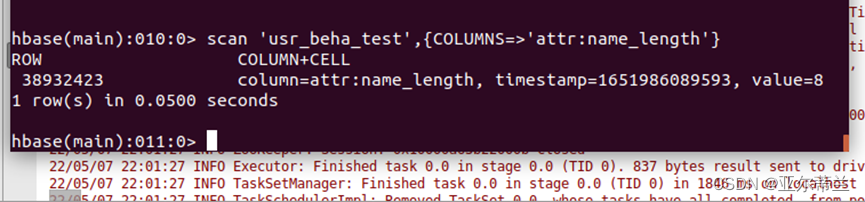
5. 广播变量
demo.txt文件内容如下: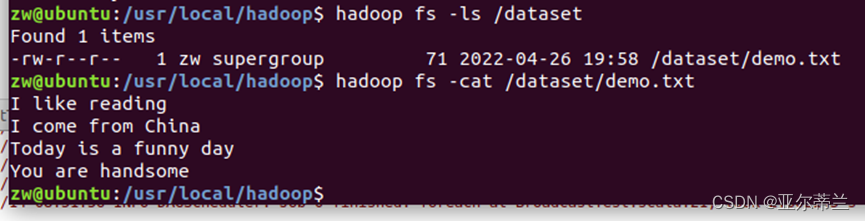
代码及运行结果: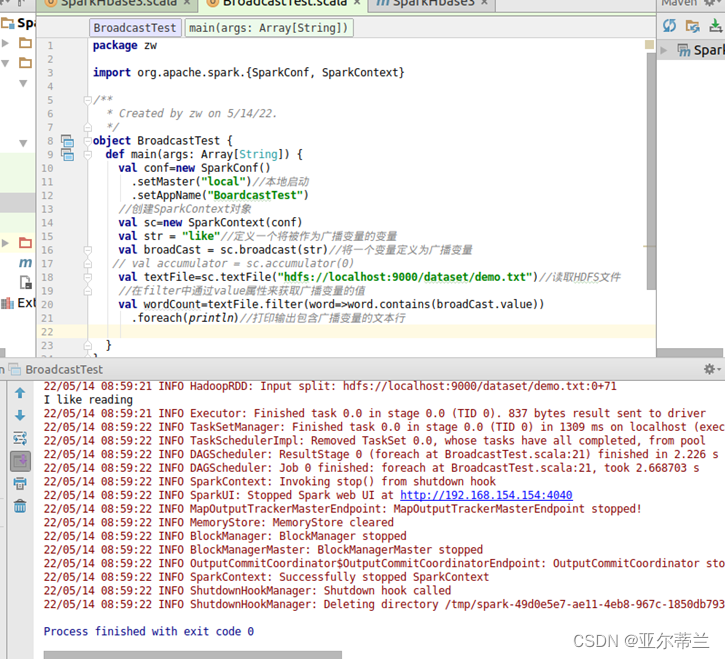
累加器: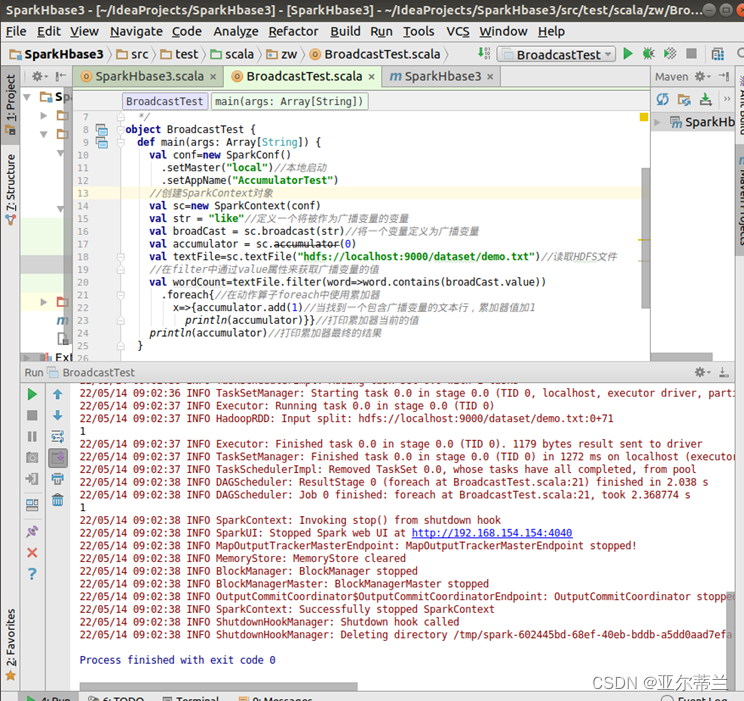
2.5 pySpark实践
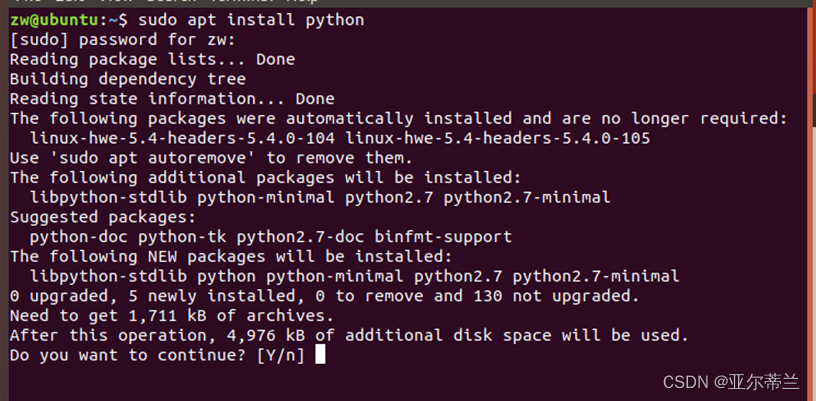
问题:无法在线安装Python: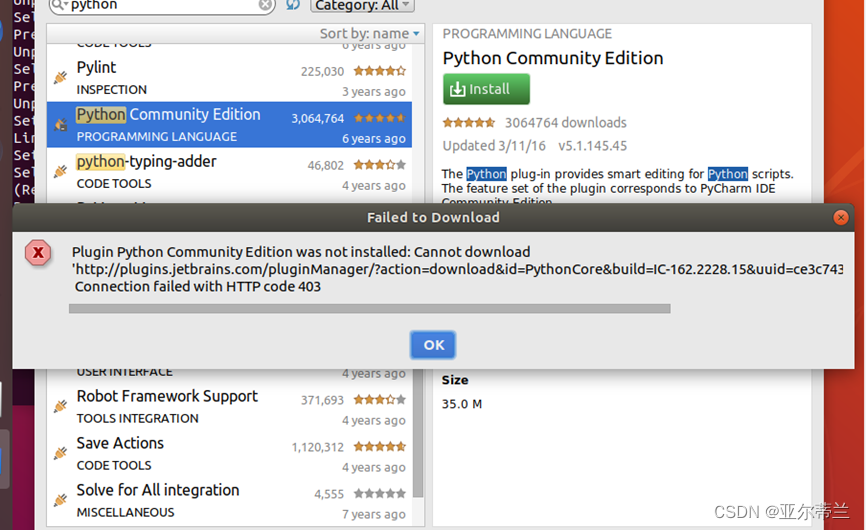
解决方法:到官网下载安装包离线安装
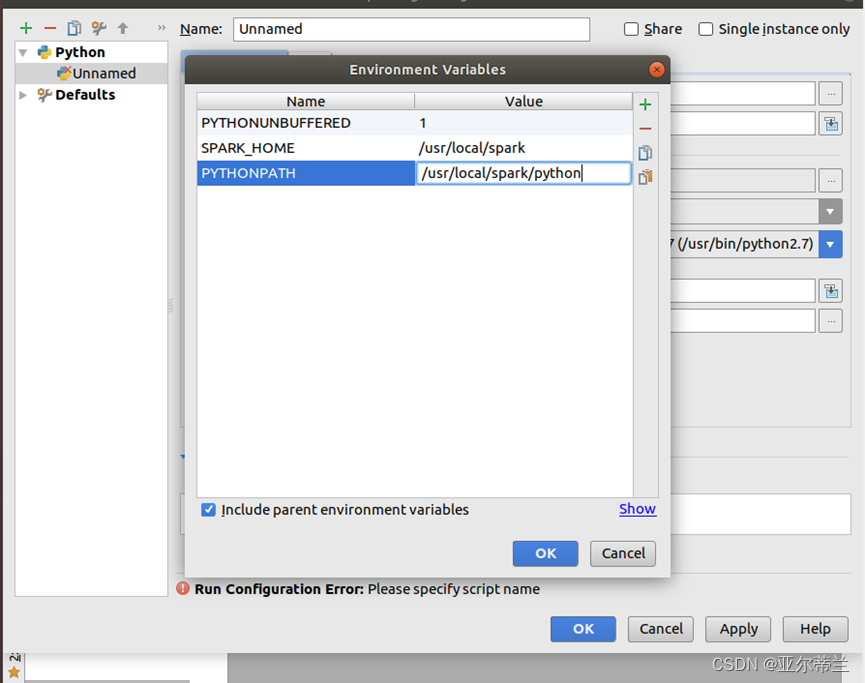
进行相关配置: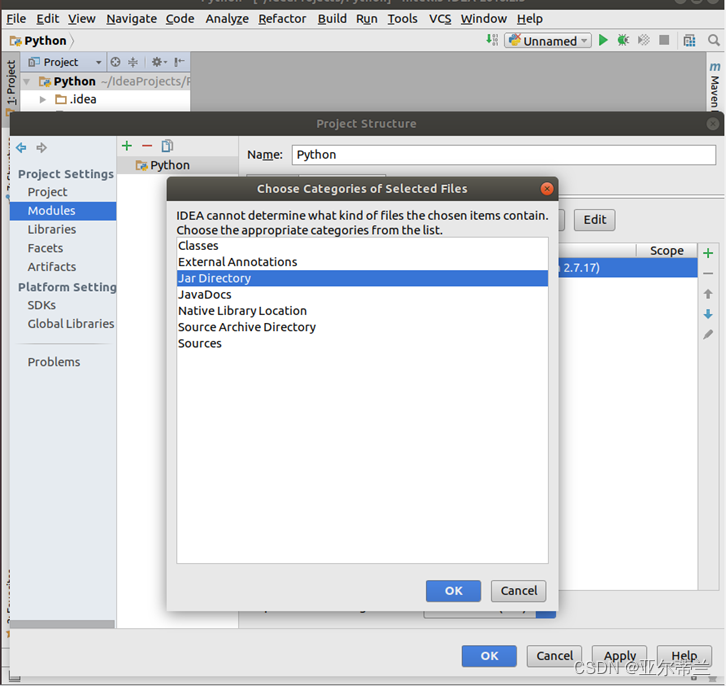
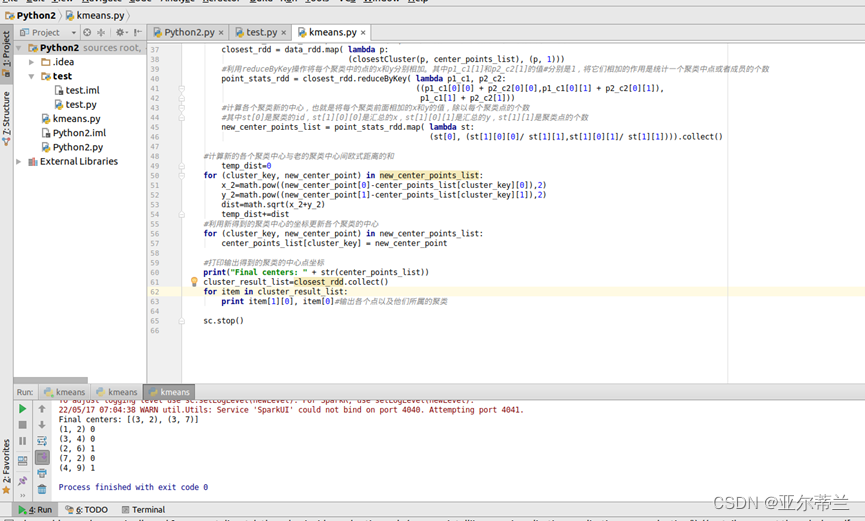
实验代码及运行结果: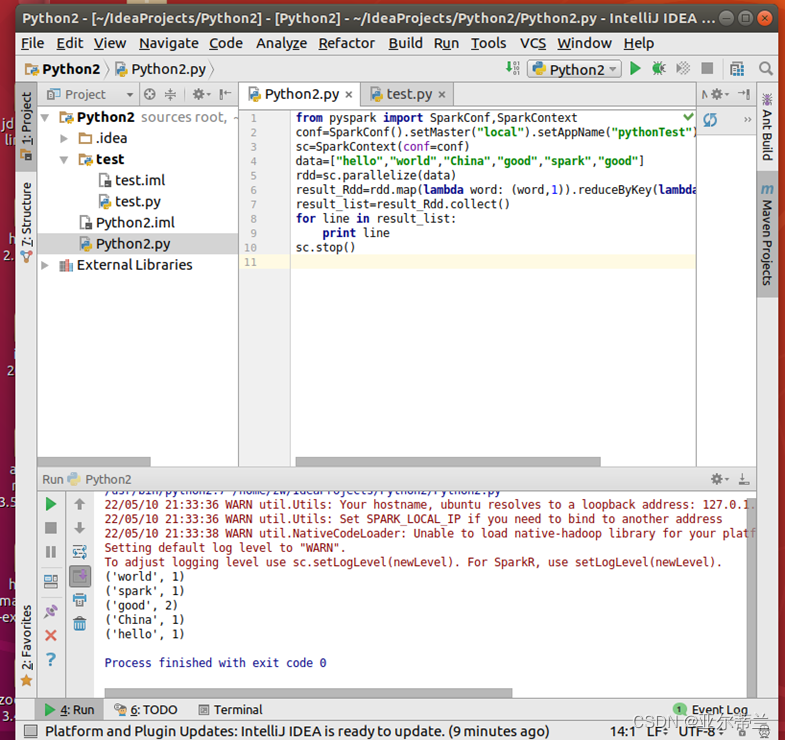
Kmeans 算法: