Mysql索引是为了让数据库高效获取数据的数据结构,相当于书本的目录。
mysun存储引擎,索引文件和数据文件单独存储,innodb存储引擎,会把数据和索引存到一个文件。mysql优先把索引加载到内存中。
索引的数据结构有以下几种
1、Hash表
- 利用Hash来存放数据,数据就是存放在内存里了,直接根据索引读取数据,内存空间有限。
- hash本身只能等值查询,根据一个索引找到一个数据,无法进行范围查询。
- 数据散列不均匀,浪费空间
- hash冲突拉链法越拉越长会降低性能。
2、二叉树搜索树
二叉搜索树和红黑树都会因为树的高度越来越高而导致效率变慢。
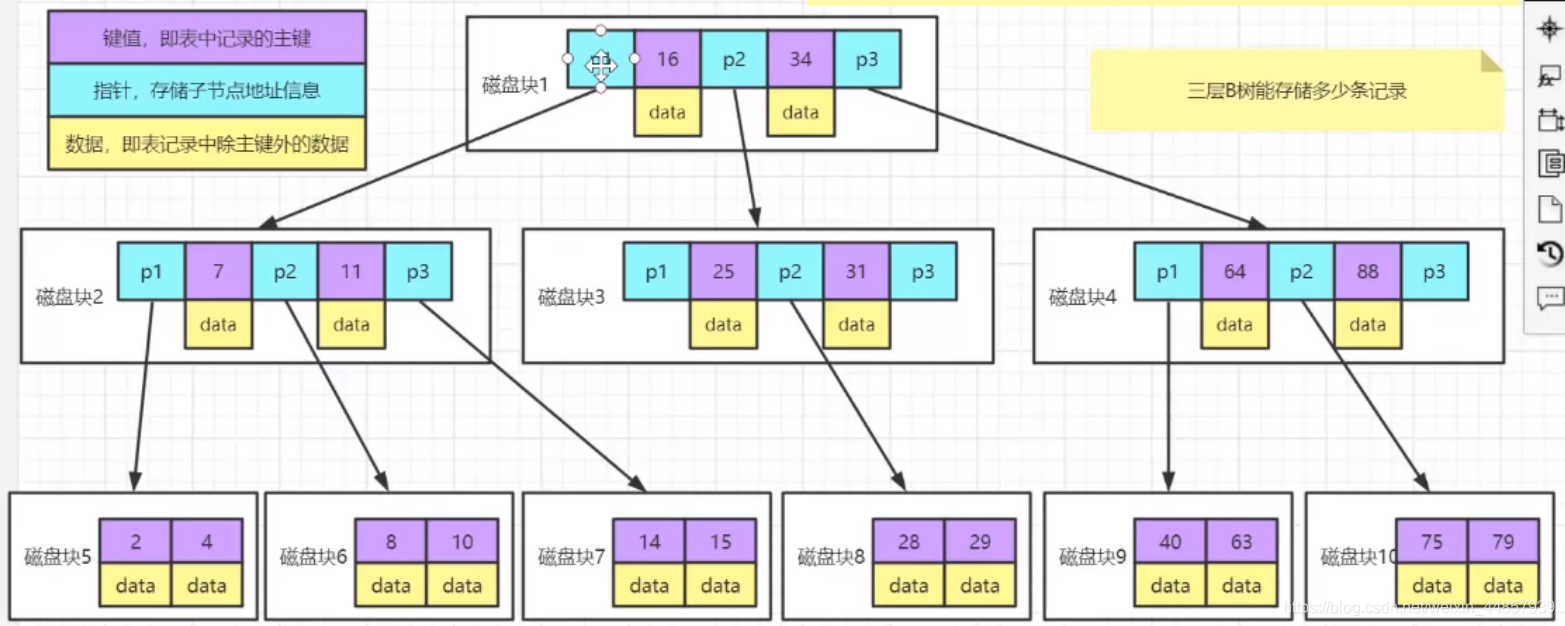
3、B树,B+的非叶子结点存储数据和子节点的指针,叶子结点只存储数据。
4、B+树(mysql使用B+树作为索引),B+树的非叶子结点都只是指针,指向子节点,只有叶子节点才会存储数据。同一级的兄弟节点(page)使用链表的形式存储,每个节点都是一个page,一个page占16KB,如果这个page是非叶子结点,其可以存1000个子节点的地址,如果这个page是叶子结点,其可以存大约200条行数据。B+树比B树更高效就是因为B+树的非叶子结点不存储数据,非叶子结点就可以保存更多的指针,即非叶子结点可以有更多的子节点,B+树就更加的矮胖,IO次数就越少。
使用索引查找过程:
查找主键key为1的数据
- 首先从磁盘加载根节点
- 根据key为1找到子节点的位置
- 访问磁盘,io,加载子节点
- 访问磁盘,io,加载子节点
- 直到加载到叶子结点,在这个page里遍历数据,找到主键为1的行数据。
可以看到如果树越矮胖,加载非叶子结点的次数越少。
常用的存储引擎有innodb,mysun.
操作系统将磁盘和内存划分为页,一页4kb,磁盘和内存交换数据是以页为单位交换数据的,每次访问磁盘,必须是页的整数倍。innodb存储引擎每次读取16kb
磁盘读写的两种方式:
- 顺序读写
- 随机读写
磁盘读写有一个最少内容的限制,即使我们只需要这个簇上的一个字节的内容,我们也要含着泪把一整个簇上的内容读完。而红黑树只有左右两个子节点,不能完全填满一个簇,B+树可以有多个节点,读取的内容不会白读,可以都放入B+树。
数据库设计的时候 B+ 树有多少个分支都是按照磁盘一个簇上最多能放多少节点设计的
聚簇索引
非聚簇索引(辅助索引)
索引里面存什么?
- key,行数据的某一列的值,一般使用自增主键,多表也不重复。
- (指针)表地址,这条数据所在表的地址。
- 指针,偏移量,这行数据,在这张表中的偏移量。
索引是K-V结构,K里面放行数据的唯一标识,V里面放表地址和偏移量。但是这样索引文件会非常大,加载索引文件会很慢,而且很费内存。所以数据库直接这样存索引不合适。数据仓库可以使用这种方式。
mysql不需要把所有的索引加载到内存,只需要加载根节点,索引的val也不保存表地址和偏移量,val直接保存完整的行数据。索引文件和数据文件一起保存。