针对爬虫出现403问题:
可采用两种方法
1、加上header
2、配置代理IP
具体参考博客 https://blog.csdn.net/u011808673/article/details/80609221
更多爬虫比较专业的伪装:https://www.cnblogs.com/junrong624/p/5533655.html (突破更多爬虫壁垒)
———————————————————分割线———————————————————
发现有很多的图片无法下载,好像就是图片本身就不能访问(403Forbidden),这个问题需要解决一下
参考了这份博客: https://blog.csdn.net/wzcyy2121/article/details/79800626
发现可能是自己的header条件不完整,那就再添加吧。
3、根据正确访问header,添加其他表头项
然后就去查看自己网页JS加载正常的是有个Referer,其他就没有了,
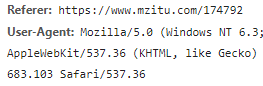
而访问不了的呢,发现他的header还少了个Referer
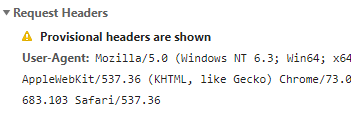
添加 req.add_header("Referer",'https://i.meizitu.net/')#添加个Referer就ok啦!棒!
然后访问一定次数后就又卡了 发现这个USER-Agent模拟浏览器还是得随机 不然访问一定次数后,他会把你的爬虫拉黑。
最后,总结一下 最好设置随机USER-Agent、随机代理IP、添加表头其他信息如Referer,确保完整的访问
版权声明:本文为lamusique原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。