机器学习预测股票收益(一)之随机森林模型
前言
本文将使用Python整理1927-2020年所有美国上市公司股票数据。根据历史收益以及交易量,使用随机森林,支持向量机以及神经网络等机器学习方法预测股票收益。最优结果构建的资产组合能获得年均超20%的收益率。
一、导入库和数据
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn import metrics
import matplotlib.pyplot as plt
from pprint import pprint
import statsmodels.api as sm
from stargazer.stargazer import Stargazer
file2 = "crsp_msf_all.csv"
data = pd.read_csv(file2,parse_dates=["date"], index_col="date")

数据来自CRSP数据库,可以看出数据集包含了各种股票数据,本文中只用到股票代码(PERMNO)、收益(RET)、交易量(VOL)。
二、处理数据以及计算特征变量
vol = data["VOL"]
ret = data[["PERMNO","RET","VOL"]]
ret = ret.replace('C',np.nan).replace('B',np.nan)
ret = ret.dropna()
ret ["RET"]= ret["RET"].astype(float)
predictorsname = ["R0","R1","R2","R3","R4","R5","R6","R7","R8","R9","R10","R11","R12",
"R13","R14","R15","R16","R17","R18","R19","R20","R21","R22","R23","R24"]
#计算历史收益
for i in range(25):
data[predictorsname[i]]= data.groupby('PERMNO')['RET'].shift(i+1)
data["R-1"] = data.groupby('PERMNO')['RET'].shift(-1)
predictorsname.append("VOL")
obs = data[predictorsname]
obs["PERMNO"] = data["PERMNO"]
obs["RET"] = data["RET"]
obs["R-1"] = data["R-1"]
obs = obs[["PERMNO","VOL","R-1","RET","R0","R1","R2","R3","R4","R5","R6","R7","R8","R9","R10","R11","R12",
"R13","R14","R15","R16","R17","R18","R19","R20","R21","R22","R23","R24"]]
obs = obs.replace('C',np.nan).replace('B',np.nan)
obs = obs.dropna()
##归一化处理
def regularit(df):
newDataFrame = pd.DataFrame(index=df.index)
columns = df.columns.tolist()
for c in columns:
d = df[c]
MAX = d.max()
MIN = d.min()
newDataFrame[c] = ((d - MIN) / (MAX - MIN)).tolist()
return newDataFrame
df = obs[predictorsname].astype(float)
new_df = regularit(df)
obs[predictorsname] = new_df
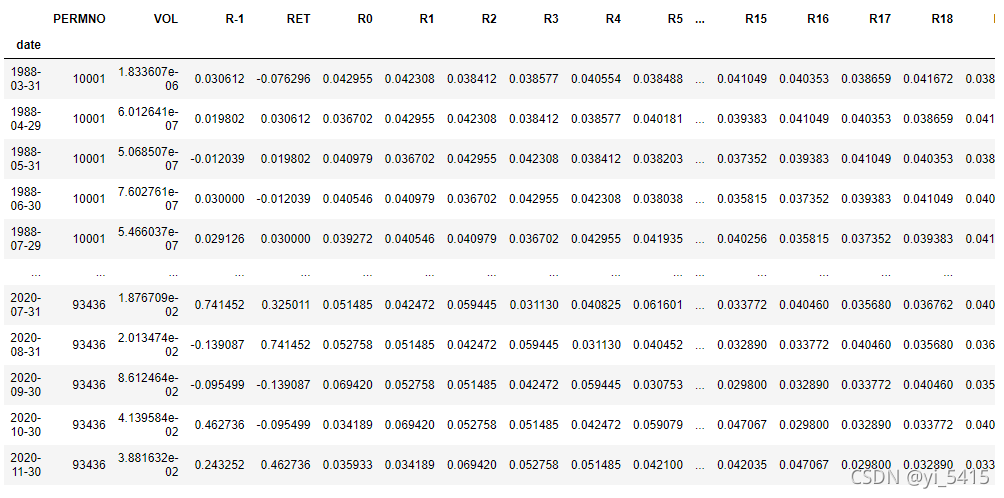
获得交易量和过去两年的每月收益。
datasort = data.sort_values(by = 'date')
months = datasort.index.drop_duplicates()
pydate_array = months.to_pydatetime()
months_array = np.vectorize(lambda s: s.strftime('%Y-%m-%d'))(pydate_array )
months_series = pd.Series(months_array)
months_series
三、使用随机森林回归预测股票收益
1.构建训练集和测试集
参考
Tree-Based Conditional Portfolio Sorts: The Relation Between Past and Future Stock Returns (Moritz and Zimmermann 2016)
循环构建训练集和测试集,使用过去五年的数据作为训练集,预测未来一年的收益。每一年循环进行,重新训练模型。
result_rfr = pd.DataFrame()
f_importance = pd.DataFrame()
perform = pd.DataFrame()
T = 1070
for t in range(1,T,12):
start= months_series[t-1]
end = months_series[t-1+72]
split = months_series[t-1+60]
predictor = obs[start:end]
permno = predictor.loc[:,"PERMNO"]
X = predictor[predictorsname].fillna(0)
y = predictor["R-1"].fillna(0)
permno_test = permno[split:]
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
rfr = RandomForestRegressor(random_state = 44,max_depth = 70,max_features = 'sqrt',min_samples_leaf = 4,min_samples_split=2,n_estimators=200)
model = rfr.fit(X_train, y_train)
i = int((t-1)/12)
feature_importance = rfr.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * (feature_importance / feature_importance.max())
fi = pd.DataFrame(feature_importance)
fi = pd.DataFrame(fi.values.T,columns = predictorsname,index = [i])
f_importance = f_importance.append(fi)
y_pre_rfr = rfr.predict(X_test)
y_pre_rfr = pd.Series(y_pre_rfr,name = "pre",index = y_test.index)
pre_data_rfr = pd.concat([permno_test,y_test, y_pre_rfr], axis=1)
result_rfr = result_rfr.append(pre_data_rfr)
mse_rfr = metrics.mean_squared_error(y_test, y_pre_rfr)
mse_rfr = pd.Series( ('%.4f' % mse_rfr),name = "mse_rfr",index =[i])
mae_rfr = metrics.mean_absolute_error(y_test, y_pre_rfr)
mae_rfr = pd.Series( ('%.4f' % mae_rfr),name = "mae_rfr",index =[i])
R2_rfr = metrics.r2_score(y_test,y_pre_rfr)
R2_rfr = pd.Series( ('%.4f' % R2_rfr),name = "R2_rfr",index =[i])
perform_data = pd.concat([mse_rfr,mae_rfr ,R2_rfr],axis = 1)
perform = perform.append(perform_data)
特征变量重要性分析
f_importance_avg = 100.0 * (f_importance_avg / f_importance_avg.max())
print(f_importance_avg)
sorted_idx = np.argsort(f_importance_avg)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.barh(pos, f_importance_avg[sorted_idx], align='center')
plt.yticks(pos,X.columns[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()

2.查看预测结果
result_rfr.to_csv("result_rfr_rolling")
result_rfr
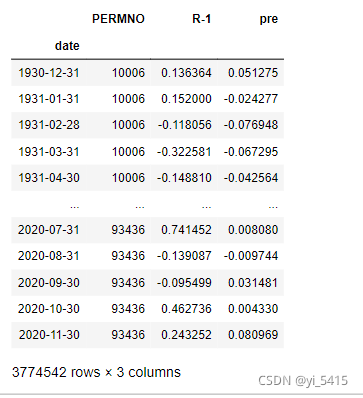
四、根据预测结果构建long-short投资组合
1.定义投资组合函数
根据预测结果给股票排序,买入排名前10%的股票,卖出排名后10%的股票。
def long_short(result):
result["R-1"] = result["R-1"].astype(float)
result = result*100
result_shift = result.groupby('PERMNO')['R-1',"pre"].shift(-1)
real_ret = pd.DataFrame(result_shift["R-1"])
real_ret["PERMNO"] = result["PERMNO"]
real_ret = real_ret.pivot_table(real_ret,index=[u'date',u'PERMNO'])
pf_ret = real_ret.unstack(level=-1)
pf_ret.columns = pf_ret.columns.droplevel()
pre_ret = pd.DataFrame(result_shift["pre"])
pre_ret["PERMNO"] = result["PERMNO"]
pre_ret = pre_ret.pivot_table(pre_ret,index=[u'date',u'PERMNO'])
pre_pf_ret = pre_ret.unstack(level=-1)
pre_pf_ret.columns = pre_pf_ret.columns.droplevel()
ranks = pre_pf_ret.rank(axis=1, method="min")
stock_num = ranks.shape[1] - ranks.isna().sum(axis=1)
ranks = ranks.div(stock_num,axis=0)
long = ranks > 0.9
long = long*pf_ret
long = long.sum(axis=1).div(stock_num,axis=0)*10
long.name = "long"
dflong = long.to_frame()
short = ranks < 0.1
short = short*pf_ret
short = short.sum(axis=1).div(stock_num,axis=0)*10
short.name = "short"
dfshort = short.to_frame()
pf = long-short
pf.name = "pf"
strategy = pd.concat([pf,dflong ,dfshort],axis = 1)
return strategy
2.定义绩效分析函数
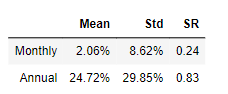
def analyze_performance(monthly_xrets):
# monthly performance
avg = monthly_xrets.mean()
sd = monthly_xrets.std()
sr = avg / sd
# annualized performance
avg_ann = avg * 12
sd_ann = sd * np.sqrt(12)
sr_ann = avg_ann / sd_ann
# format in percent
avg, avg_ann = str(round(avg , 2)) + "%", str(round(avg_ann, 2)) + "%"
sd, sd_ann = str(round(sd , 2)) + "%", str(round(sd_ann , 2)) + "%"
# create output
stats = pd.DataFrame([[avg, sd, round(sr, 2)],
[avg_ann, sd_ann, round(sr_ann, 2)]],
columns=["Mean", "Std", "SR"],
index=["Monthly", "Annual"])
return stats
五、引入Fama-French Factor
file2 = "F-F_Research_Data_Factors.csv"
factors = pd.read_csv(file2,parse_dates=["date"], index_col="date")
factors = factors.dropna()
factors.rename(columns={'Mom':'UMD'},inplace=True)
factors.index = pd.date_range('1927-01-31','2021-05-31',freq='M')
pfactors = factors["1971-01-30":"2020-12-31"] ##################
pfactors.index = pf.index
Mkt = pfactors["Mkt-RF"].add(pfactors["RF"],axis = 0)
Mkt.name = "Mkt"
Mkt = Mkt.to_frame()
figure = pfactors[["RF"]]
figure["Mkt"]= Mkt
figure["long"]= dflong
figure["short"]= dfshort
figure = figure/100 +1
value = figure.cumprod()
lgvalue = np.log(value)
value

上图展示了从1971年开始分别投资1$ 在无风险组合,市场组合,winner组合以及loser组合,并持有到2020年是各投资组合的价值。
lgvalue.plot()
plt.ylabel("log($ value of investment)")
plt.legend(["risk-free,end value=$9.10", "market, end value=$187.81","long, end value=$1,391,449.90", "short, end value=$3.26"])

六、投资组合表现
1.超额收益表现
pf_xret = pf - pfactors.loc[:,"RF"]
pf_xret = pf_xret.rename("pf excess return")
analyze_performance(pf_xret)
2.多因子回归
def time_series_regressions(y, x):
# 1-factor market model
x_1 = x.loc[:,"Mkt-RF"]
model_1 = sm.OLS(y, sm.add_constant(x_1), missing="drop").fit()
# Fama-French 3-factor model
x_2 = x.loc[:,["Mkt-RF", "SMB", "HML"]]
model_2 = sm.OLS(y, sm.add_constant(x_2), missing="drop").fit()
# FF 3-factor model augmented with UMD
x_3 = x.loc[:,["Mkt-RF", "SMB", "HML", "UMD"]]
model_3 = sm.OLS(y, sm.add_constant(x_3), missing="drop").fit()
return [model_1, model_2, model_3]
def regression_results(pf_xret,pfactors):
import statsmodels.api as sm
# run the regressions
models = time_series_regressions(pf_xret, pfactors)
alphas = [round(model.params.loc["const"] * 12, 2) for model in models]
SR = pf_xret.mean()/pf_xret.std()
IR = [round(model.params.loc["const"] /(np.sqrt(model.ssr/len(pf_xret))), 2) for model in models]
#ir = alpha/np.sqrt(ssr / len(erets) * 12)#注意开根号 年化
ssr = [round(np.sqrt(model.ssr), 2) for model in models]
# present regression results
stargazer = Stargazer(models)
stargazer.add_line("Annualized Alpha ", alphas)
stargazer.add_line("IR ", IR)
stargazer.covariate_order(["const", "Mkt-RF", "SMB", "HML","UMD"])
return stargazer
regression_results(pf_xret,pfactors)

总结
随机森林结果构建的资产组合能获得年均超20%的收益率,但是收益波动较大,因此sharp ratio 并不高。
版权声明:本文为weixin_47174968原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。