我们已经理解了神经网络是如何诞生的,也了解了怎样的算法才是一个优秀的算法,现在我们需要借助深度学习框架(Deep learning framework)来帮助我们实现神经网络算法。在本门课程中,我们所使用的深度学习框架是PyTorch,也就是Torch库的Python版本。之前我们已经仔细地介绍了PyTorch中的基本数据结构Tensor以及自动求梯度工具autograd,相信你已经对PyTorch有了一定的了解。在今天的课程中,我们将更深入地理解PyTorch库的构成以及PyTorch框架的设计理念,为之后熟练使用PyTorch打下基础。

1 PyTorch的优势
对于已经选择了这门课的你,应该早就把PyTorch的优势烂熟于心了。就如同每一个学习Python的人在Python课程的第一堂课会听到的内容一样,无数的资料、课程都在说着相似的话:PyTorch简单易用、上手容易、语法清晰……这些虽然是事实,但却无法加深你对PyTorch或深度学习的理解。在这一节,我们将从深度学习模型的判别框架来看待,为什么PyTorch是一个优秀的深度学习框架。
我们在上一节中说过,一个好的深度学习模型,应该是预测结果优秀、计算速度超快、并且能够服务于业务(即实际生产环境)的。巧合的是,PyTorch框架正是基于这样目标建立的。
一个神经网络算法的结果如何才能优秀呢?如果在机器学习中,我们是通过模型选择、调整参数、特征工程等事项来提升算法的效果,那在神经网络中,我们能够做的其实只有两件事:
1)加大数据规模
2)调整神经网络的架构,也就是调整网络上的神经元个数、网络的层数、信息在网络之间传递的方式。
对于第一点,PyTorch的优势是毫无疑问的。PyTorch由Facebook AI研究实验室研发。在2019年,FB每天都需要支持400万亿次深度学习算法预测,并且这个数据还在持续上涨,因此PyTorch天生被设计成非常适合进行巨量数据运算,并且可以支持分布式计算、还可以无缝衔接到NVIDIA的GPU上来运行。除此之外,PyTorch的运行方式有意被设计成更快速、更稳定的方式,这使得它运行效率非常高、速度很快,这一点你在使用PyTorch进行编程的时候就能够感受到。为高速运行巨量数据下的神经网络而生,PyTorch即保证了神经网络结果优秀,又权衡了计算速度。
而第二点,则是深度学习整个学科的灵魂操作。我们耳熟能详的RNN、CNN、LSTM等算法,其实都是在原始神经网络上进行了神经元、链接、或信息传递方式的改变而诞生的。因此,一个优秀的深度学习框架,必须具备非常高的灵活性和可调试性,才有可能不断推进深度学习算法的研究。(同时,一个优秀的深度学习算法工程师,必须具备灵活调用任何可用网络结构的能力,才可能搭建出适应实际工业场景的神经网络)。幸运的是,PyTorch框架的创始团队在建立PyTorch时的目标,就是建立最灵活的框架来表达深度学习算法,这为PyTorch能够最大程度释放神经网络算法的潜力、放大深度学习的本质优势、实现更好的算法效果提供了基础。
同时,为了能够让算法调试变得更加容易,PyTorch在设计之初就支持eager model(类似于在jupyternotebook的运行方式,可以每写几行代码就运行,并且返回相应的结果,通常在研究原型时使用),而tensorflow等框架在最初是不支持eager model,只支持graph-based model(一次性写完全部的代码,编译后上传服务器进行全部运行,这种类型的代码更加适合部署到生产环境中)。现在的PyTorch使用JIT编辑器,使得代码能够在eager和graph model之间自由转换,tensorflow也在1.7版本之后补充了这个功能。
最难得的是,PyTorchAPI简化程度很高,代码确实简单易懂。在编程的世界里,封装越底层就越灵活(如C++就比Python更加灵活),但越底层的框架往往就越复杂,需要的代码量也越多。PyTorch建设团队在构筑PyTorch项目时,一直遵守“简单胜于复杂”的原则。为了让PyTorch尽量简单,他们参考了大量NumPy以及Python的基本语法,让PyTorch可以无缝衔接到Python中,在保留灵活性的同时,最高程度地简化了API,继承了Python的大部分语法风格。对于熟练使用Python的人来说,使用PyTorch库通常轻而易举。
除此之外,PyTorch十分重视从研发算法到工业应用的过程。在PyTorch的官网头图上,甚至能够直接看到from research to production(从研发到生产)的字样。他们甚至完整地定义了算法部署到实际环境中需要达到的数个要求,并在2019年QCon会议的演讲中详细地说明了PyTorch团队是如何围绕”从研发到生产“这个目标设计了PyTorch的部署模块JIT。
总结一下, PyTorch的优势可以概括为以下几点:
- 天生支持巨量数据和巨大神经网络的高速运算
- 灵活性高,足以释放神经网络的潜力,并且在保留灵活性的同时,又有Python语法简单易学的优势
- 支持研究环境与生产环境无缝切换,调试成本很低
作为深度学习框架,PyTorch可以说具备几乎所有产出优质深度学习算法的条件。现在,PyTorch社区及围绕PyTorch的生态还在建设中,这可以说是它唯一的弱势了。作为一门深度学习入门课程,我们非常推荐你选择PyTorch作为你的第一个深度学习框架。但它是否会成为你的最后一个深度学习框架,将交由学完课程的你来决定。
2 PyTorch库的基本架构
虽然PyTorch库在建设时拥有许多先进的理念,但在库的规划整理这一点上,它却与大部分编程库一样,显得有些潦草。任何编程库都不是在一个完美的企划下被设计出来的,而是在实际应用中不断被探索出来的,这就导致大部分编程库的体系是混乱的——即初学者完全不知道应该从哪里开始学习,典型的代表就是matplotlib, NumPy这些明明很有用,但是官网写得不知所云的库。
PyTorch官网在深度学习领域常常受到赞扬,许多人认为PyTorch官网写得简单明了,容易上手。但如果是学过sklearn课堂的小伙伴,就会知道sklearn官网是多么规范、多么易学:
再看看PyTorch官网这令人窒息的,按字母表顺序排列的类的列表:

文档写得好?其实全是同行的衬托,反正比tf写得好一点点。
在开始学习PyTorch之前,我们对PyTorch的核心模块进行了梳理。现在PyTorch中的模块主要分为两大类:原生Torch库下,用于构建灵活神经网络的模块,以及成熟AI领域中,用以辅助具体行业应用的模块。
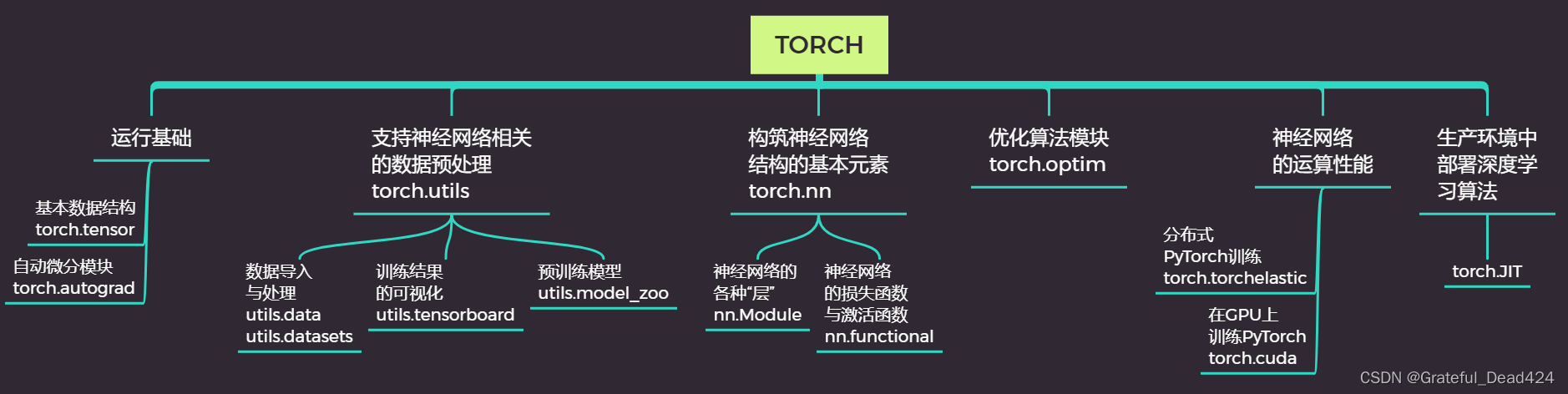

两大模块的层次是并列的,当我们导入库的时候,我们是这样做:
import torch
import torchvision实际上在我们对PyTorch进行安装的时候,我们也是同时安装了torch和torchvision等模块。 当我们需要优化算法时,我们运行的是:
from torch import optim看出库的层次区别了吗?在我们课程的前几周,我们会集中在Torch模块中,帮助大家熟悉PyTorch的基本操作,并培养从0建立起自定义神经网络的能力。在课程后续的篇章中,我们将会涉入成熟AI领域的许多库中,对成熟算法和先进的神经网络架构进行讲解。为了构建强大的神经网络,我们会交叉使用两个模块的内容。在我们学习的过程中,我们或许会用到不在这两张架构图上的库,后续我们会继续补充和修缮这两张架构图。
了解了这么多内容后,你终于可以开始学习神经网络了。PyTorch代码虽然简单,但运行一行简单的代码却需要丰富的基础知识。从下一节课开始我们从0学习神经网络,并逐渐让你掌握PyTorch中的代码。