1 http和https
首先明白http就是个协议。
http设计两个对象,客户端和服务端。
服务端会随时准备着,不会主动发起数据。只有在客户端发起请求的时候,服务端再回响应。
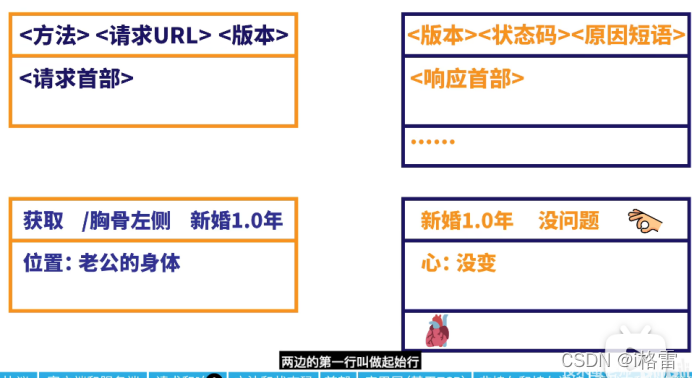
我们平时上网就是为了获取网上的资源,要获取网上的资源就需要进行通信。也就是客户端和服务端进行网络通信,客户端就需要发送请求报文,服务端收到请求以后就回送响应报文。
Http规定了请求报文和响应报文的格式。
如果把网络通信按照TCP/IP模型划分
最顶2层的是应用层和传输层
http协议默认是80端口
传输层协议是来配合应用层定义传输数据的方式。需要在传输层里面选择协议。传输层里面最出名的两个协议是TCP和UDP。绝大部分http都用的是TCP。因为它的3次握手很可靠。
如果用UDP,即使服务器响应了,接收到的网页很可能会缺斤少两。
http是一次一个请求。随着互联网的发展,一次一个请求很难满足实际需求。而且每次都要进行一次TCP连接。
因此在http1.1中,默认连接为持久连接。服务端返回消息,客户端可以继续发送下一个请求。如果没有需要发送的了,客户端最后发送Connection:close首部给服务器,这样就会关闭。
如果大量用户访问同一台服务器,而服务器又把他们的信息全部记录下来,这样服务器肯定是要崩溃的。所以服务器不会把每个状态都记录下来。
这就是HTTP的无状态。
但是目前很多网站都是有用户登录功能的,如果是无状态的话,用户登陆了一次,第二次访问又需要输入信息登录,很麻烦。为了保持登陆状态,就有了cookie这项技术。
这项技术需要在http请求首部字段(header)加上cookie信息。这样就能实现保持登陆状态了。从而实现状态管理。
Http:请求和响应的报文都是明文的,大家都能看懂。
为了给http增加安全性,给http加了一个s。
就是给http使用TLS/SSL加密安全协议。
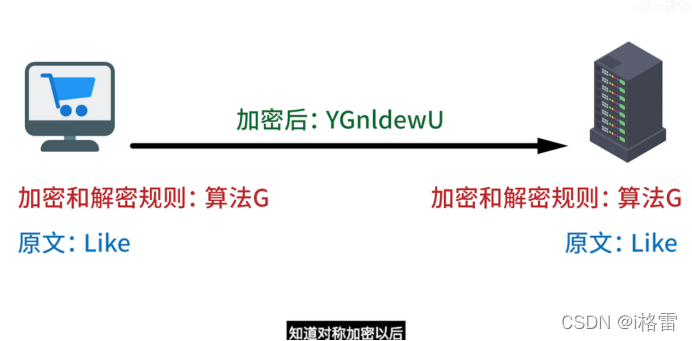
1.对称加密:
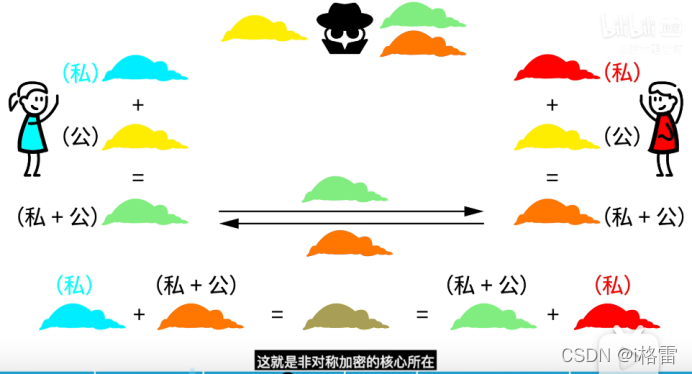
2.非对称加密:用两个密钥进行加密和解密。公钥和私钥
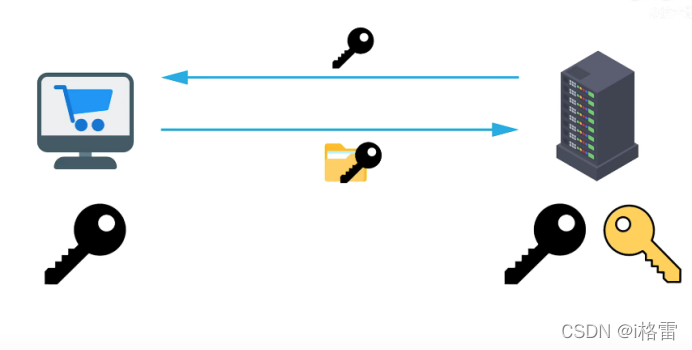
TSL:运用了对称和非对称加密

http:
1.http有三个版本
(1)http1.0:无状态、短连接
(2)http1.1:可以记录状态 --大多数浏览器默认支持
(3)http2.0:可以支持长连接。协议头:connection:keep-alive
2.cookie:
(1)最早的http1.0,提供cookie机制,但是没有session
(2)Cookie:在一定时间内,存储用户的连接信息。如用户名、登陆时间...不敏感信息
(3)Cookie出身:http自带机制。Session不是。
(4)Cookie存储:存储在客户端(浏览器)中----以key-value存储。不安全。
3.Session
(1)会话:在一次会话交流中产生的数据。不是http、浏览器自带。
(2)作用:一定时间内,存储用户的连接信息
(3)Session存储:在服务器中,一般为临时session---会话结束(浏览器关闭)session被干掉
4.go语言操作cookie:
(1)设置:context.SetCookie(“name”,”testcookie”,60*60,””,””,false,true)
(2)获取:cookievalue , _ := context.Cookie(“name”)
5.go操作session
(1)gin不支持操作session,需要安装相关的插件:go get github.com/gin-contrib/sessions
(2)session是需要存储在容器里面的,为此存在redis里
(3)设置:
初始化session容器(redis):
store, _ := redis.NewStore(10,”tcp”,”192.168.30.132:6379”,””,[]byte(“bj38”))
使用容器:
store.Use(sessions.Sessions(“mysession”,store))
调用session,设置session数据
s := Sessions.Default(context)
s.Set(“itcast”,”valuexxx”)
S.Save()
(4)获取:
v := s.Get(“itcast”)
fmt.println(v.(string))//设置断言
http协议:应用层面向对象协议,规定了浏览器(客户端)和服务器交互通信的规则。客户端与服务端通信传输的内容称为报文。
http协议是纯文本的,无状态的
Referer是HTTP请求头的一部分。表示请求是从哪里的链接过来的
作用:防盗链
什么情况下不会产生Referer:
当一个请求不是由链接触发产生的,就不会产生Referer。
直接在浏览器输入某个资源的url时,这种情况不会产生Referer。因为这是一个凭空产生的HTTP请求,并不是从一个地方链接过来的。
在防盗链设置中,允许Referer为空和不允许为空有什么区别:
允许Referer为空,意味着你允许浏览器直接访问视频链接的url,此时Referer就为空。
后端代码中怎么获取Referer:
request.META.get(“HTTP_REFERER”)
fetch和XHR(XMLHttpRequest)的区别:浏览器向服务器发送请求返回的数据
XMLHttpRequest是ajax的底层实现原理
第二:从实际上的数据应用来说httP
在前面客户端和应用服务器建立TCP连接之后,就需要用http协议来传送数据了,HTTP协议简单来说,还是请求,确认,连接。
总体就是C发送一个HTTP请求给S,S收到了这个http请求,然后返回给Chttp响应,然后C的中间件或者说浏览器把这些数据渲染成为了网页,展示在用户面前。
第一:发送一个http请求给S,这个请求包括请求头和请求内容:
request header:
包括了,1.请求的方法是POST/GET,请求的URL,http协议版本2.请求的数据,和编码方式3是否有cookie和cooies,是否缓存等。
post和get请求方式的区别是,get把请求内容放在URL后面,但是URL长度有限制。而post是以表单的形势,适合要输入密码之类的,因为不在URL中显示,所以比较安全。
request body:
即请求的内容.
第二:S收到了http请求,然后根据请求头,返回http响应。
response header:包括了1.cookies或者sessions2.状态吗3.内容大小等
response body:
即响应的内容,包括,JS什么的。
第三,C收到了以后,就由浏览器完成一系列的渲染,包括执行JS脚本等。
这就是我所理解的webTCP,HTTP基础知识,待续。。。。。
TCP是底层通讯协议,定义的是数据传输和连接方式的规范
HTTP是应用层协议,定义的是传输数据的内容的规范
HTTP协议中的数据是利用TCP协议传输的,所以支持HTTP也就一定支持TCP
HTTP支持的是www服务
而TCP/IP是协议
它是Internet国际互联网络的基础。TCP/IP是网络中使用的基本的通信协议。
TCP/IP实际上是一组协议,它包括上百个各种功能的协议,如:远程登录、文件传输和电子邮件等,而TCP协议和IP协议是保证数据完整传输的两个基本的重要协议。通常说TCP/IP是Internet协议族,而不单单是TCP和IP。