目錄
第一節 Series和DataFrame的排序
1.1 Series排序
Series由兩部分組成 values 和 index
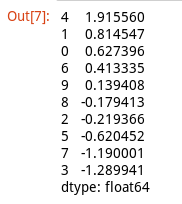
s1 = Series(np.random.randn(10))
// 根據values值從小到大排序
s2 = s1.sort_values()
// 降序排序
s2 = s1.sort_values(ascending = False)
s2.sort_index()
1.2 DataFrame排序
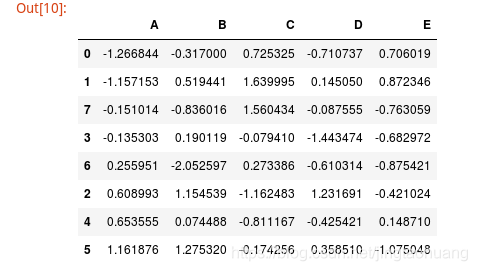
df1 = DataFrame(np.random.randn(40).reshape(8,5), columns = ['A', 'B', 'C', 'D', 'E'])
// 按A的值進行排序
df1.sort_values('A')
df1.sort_index()
第二節 重命名DataFrame的index
2.1 csv文件的使用
// 生成一個測試用的csv文件
df2 = DataFrame(np.random.randn(20).reshape(5, 4), columns = ['BJ', 'SH', 'GZ','XT'])
df2.to_csv('test.csv')
// 處理並保存
csv_input = './test.csv'
pd.read_csv(csv_input).head()[["BJ", "SH", "GZ"]].sort_values('SH', ascending = False).to_csv('test2.csv')
2.2 重命名
df2 = DataFrame(np.arange(20).reshape(5, 4), index = ['A', 'B', 'C', 'D', 'E'], columns = ['BJ', 'SH', 'GZ','XT'])
// 批量講index 和 columns 改成小寫
df2.rename(index = str.lower, columns = str.lower)
// 通過字典進行改名
df2.rename(index = {'a' : 'AA'}, columns = {'bj' : 'beijing'})
第三節 DataFrame的merge操作
df1 = DataFrame({'key' : ['X', 'Y', 'Z'], 'DataSet_1' : [1, 2, 3]})
df2 = DataFrame({'key' : ['X', 'B', 'C'], 'DataSet_2' : [4, 5, 6]})
pd.merge(df1, df2)

版权声明:本文为jingtaohuang原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。