软硬件配置:Ubuntu + Tesla m40 24GB + cuda10.2 + anaconda
源码下载:https://github.com/ultralytics/yolov5
训练过程:YOLOv5训练自己的数据集之详细过程篇
1、ValueError: setting an array element with a sequence.
WARNING: data/images/000442.jpg: [Errno 2] No such file or directory: 'data/images/000442.jpg'
解决:
Ubuntu图片格式jpg和JPG严格区分,将train.txt、val.txt、test.txt中图片路径改成对应的图片格式路径。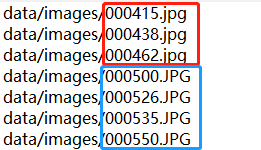
2、Process finished with exit code 134 (interrupted by signal 6: SIGABRT)
0%| | 0/54 [00:00<?, ?it/s]terminate called after throwing an instance of 'std::runtime_error' what(): NCCL Error 1: unhandled cuda error
解决:
服务器配置了两块显卡:Tesla是计算卡不可显示,NVS用来显示不可计算
using CUDA device0 _CudaDeviceProperties(name='Tesla M40 24GB', total_memory=22945MB)
device1 _CudaDeviceProperties(name='NVS 510', total_memory=1997MB)
train中有并行计算,识别到两个显卡进行了并行计算,但是只有一个显卡可用于计算
将并行计算部分注释掉
# DP mode
if cuda and rank == -1 and torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
3、BrokenPipeError: [Errno 32] Broken pipe
Traceback (most recent call last):
File "F:\FH\FxH\Go\code\yolov5_venv\lib\multiprocessing\popen_spawn_win32.py", line 89, in __init__
reduction.dump(process_obj, to_child)
File "F:\FH\FxH\Go\code\yolov5_venv\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
解决:
该问题的产生是由于windows下多线程的问题,和DataLoader类有关
因为同时在debug两个项目,简单粗暴地终止debug
4、RuntimeError:Trying to create tensor with negative dimension -1601340342: [-1601340342]
Traceback (most recent call last):
File "F:/ZYY/chess/yolov5/yolov5-2-2/train.py", line 468, in <module>
train(hyp, opt, device, tb_writer)
File "F:/ZYY/chess/yolov5/yolov5-2-2/train.py", line 331, in train
save_dir=log_dir)
File "F:\ZYY\chess\yolov5\yolov5-2-2\test.py", line 113, in test
output = non_max_suppression(inf_out, conf_thres=conf_thres, iou_thres=iou_thres, merge=merge)
File "F:\ZYY\chess\yolov5\yolov5-2-2\utils\general.py", line 652, in non_max_suppression
i = torch.ops.torchvision.nms(boxes, scores, iou_thres)
解决:
negative dimension表示数组越界。根据Trackback定位到utils/general.py中non_max_suppression函数红框区域。boxes的shape是8 * 661674 * 4。8表示batch_size, 661674表示候选框的个数,4是4个坐标参数。
计算一下:img_size = 640,经过8倍、16倍、32倍下采样的特征图是80 * 80、40 * 40、20 * 20
三张特征图生成的候选框:20 * 20 + 40 * 40 + 80 * 80 = 8400
multi label机制:8400 * 81 = 680400
解决:
由于我们的数据集不存在同一区域有多个类别的情况,可以考虑删掉multi label。也可以用多个数组存储候选框参数。
去除multi label添加best class only
去除红框部分代码,增加黄框部分代码
5、RuntimeError: CUDA error: no kernel image is available for execution on the device
/home/nju307/anaconda3/envs/yolov5/lib/python3.7/site-packages/torch/cuda/__init__.py:104: UserWarning:
GeForce RTX 3090 with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70 sm_75.
If you want to use the GeForce RTX 3090 GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
Using CUDA device0 _CudaDeviceProperties(name='GeForce RTX 3090', total_memory=24268MB)
device1 _CudaDeviceProperties(name='GeForce RTX 3090', total_memory=24268MB)
device2 _CudaDeviceProperties(name='GeForce RTX 3090', total_memory=24268MB)
device3 _CudaDeviceProperties(name='GeForce RTX 3090', total_memory=24268MB)
解决:
实验室新入新的服务器,显卡是 GeForce RTX 3090 * 4 (不是来炫耀的哈哈哈哈 (σ゚∀゚)σ)
报错信息显示显卡3090的CUDA计算能力和pytorch版本不匹配
安装适用于GeForce RTX 3090显卡的pytorch
卸载当前版本的pytorch, 重新安装匹配版本
pip uninstall torch
pip uninstall torchvision
pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
成功!
--------------------------------------- to be continued…