目录
1、需求描述 3
2、环境介绍 3
3、数据来源描述 4
4、数据上传及上传结果查看 4
5、数据处理过程描述 4
1.Pyspark交互式编程 4
2.编写独立应用程序实现数据去重 7
3.编写独立应用程序实现求平均值问题 10
6、经验总结 12
参考文献 14
1、需求描述
本次操作实验为RDD编程初级综合实践,其中包含pyspark交互式编程、编写独立应用程序实现数据去重、编写独立应用程序实现求平均值问题等三大RDD编程实验。
本次旨在熟悉Spark的RDD基本操作及键值对操作,熟悉使用RDD编程解决实际具体问题的方法。Spark 的核心是建立在统一的抽象弹性分布式数据集RDD之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。RDD是Spark最为核心的概念,它是一个只读的、可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,可在多次计算间重用。Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作,从而实现各种复杂的应用。
本次实验将对 RDD 的基本用法做简单实编程训。
2、环境介绍
本次实验基于Win 10系统下VirtualBox安装的Ubuntu虚拟机的spark操作实验。VirtualBox 是一款开源虚拟机软件。VirtualBox 是由德国 Innotek 公司开发,由Sun Microsystems公司出品的软件,它不仅具有丰富的特色,而且性能也很优异。它简单易用,可虚拟的系统包括Windows、Linux、Solaris、甚至Android等操作系统。具体实验配置如下所示:
操作系统:Windows 10
虚拟机系统:Ubuntu16.04
Spark版本:2.4.0
Python版本:3.8
Mysql版本:5.7
3、数据来源描述
本次操作实验需要使用部分数据作为数据来源,可选用吉立建老师所发文件夹中的“data.txt”、“Algorithm.txt”、“Database.txt”、“Python.txt”、“A.txt”、“B.txt”等数据集,或者亦可到教程官网的“下载专区”的“数据集”中下载实验所需的数据集,该数据集包含了某大学计算机系的成绩。
得到数据集后,传输到Ubuntu虚拟机系统中作为本次实验的数据来源。根据给定的实验数据,我们需要在pyspark中通过编程来计算本次实验内容,本次实验包括pyspark交互式编程、编写独立应用程序实现数据去重、编写独立应用程序实现求平均值问题等RDD编程等实验。
4、数据上传及上传结果查看
为了在Ubuntu虚拟机系统中获取所需的数据集,我们可选用以下方法。
方法一:通过邮件发送,将所需数据集打包成zip文件发送到邮箱保存,然后在Ubuntu虚拟机中登录邮箱下载获取。
方法二:通过Filezilla新建站点,实现PC机与虚拟机之间的通讯。
方法三:安装虚拟机增强工具插件,安装完毕后可将文件以拖拽的方式保存入虚拟机系统中。
5、数据处理过程描述
1.Pyspark交互式编程
请到教材官网的“下载专区”的“数据集”中下载chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1) 该系总共有多少学生;
答:265人
(2) 该系共开设了多少门课程;
答:8门
(3) Tom同学的总成绩平均分是多少;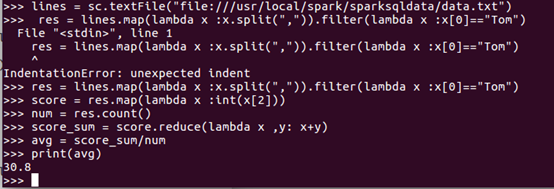
答:Tom同学的平均分为30.8分
(4) 求每名同学的选修的课程门数;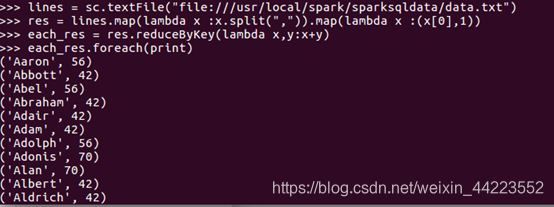
答:共265行
(5) 该系DataBase课程共有多少人选修;
答:为1764人
(6) 各门课程的平均分是多少;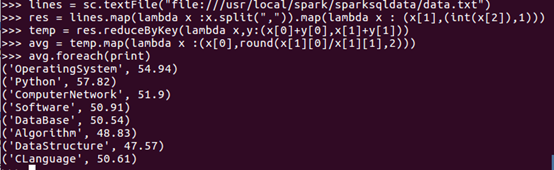
答:如图所示
(7)使用累加器计算共有多少人选了DataBase这门课。
答:共有1764人
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
实验答案参考步骤如下:
准备工作:
首先安装 pip install findspark
进入cd /usr/local/spark/mycode/remdup 文件夹
创建文件A,B.txt
(1) 假设当前目录为/usr/local/spark/mycode/remdup,在当前目录下新建一个remdup.py文件
进入cd /usr/local/spark/mycode/remdup 创建remdup.py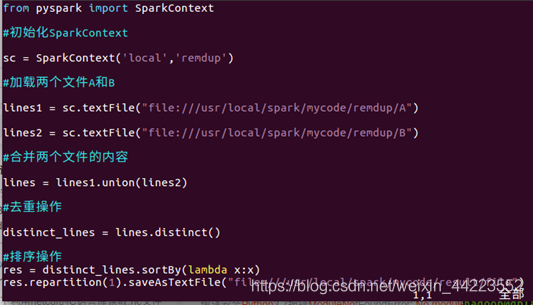
(2) 最后在目录/usr/local/spark/mycode/remdup下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告);
输入spark-submit remdup.py 生成文件
(3)在目录/usr/local/spark/mycode/remdup/result下即可得到结果文件part-00000。
cat part-00000 _SUCESS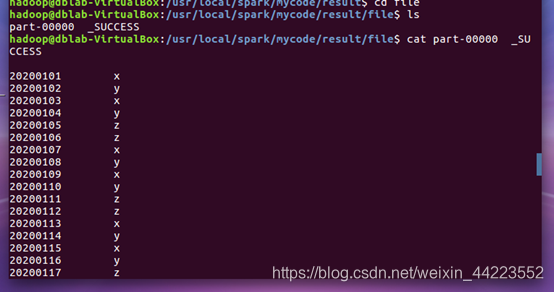
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
实验答案参考步骤如下:
准备工作:
进入cd usr/local/spark/mycode/avgscore 文件夹
创建文件Algorithm.txt, Database.txt, Python.txt
(1) 假设当前目录为/usr/local/spark/mycode/avgscore,在当前目录下新建一个avgscore.py;
进入文件 cd usr/local/spark/mycode/avgscore
创建文件 vim avgscore.py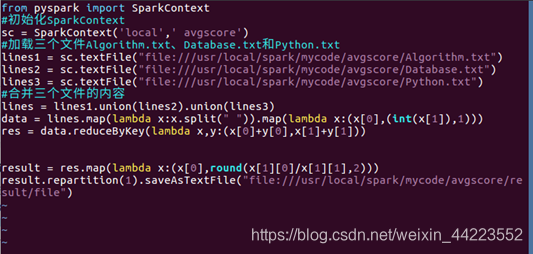
(2)最后在目录/usr/local/spark/mycode/avgscore下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告)。
输入spark-submit remdup.py 生成文件
(3)在目录/usr/local/spark/mycode/avgscore/result下即可得到结果文件part-00000。
运行结果 cat part-000000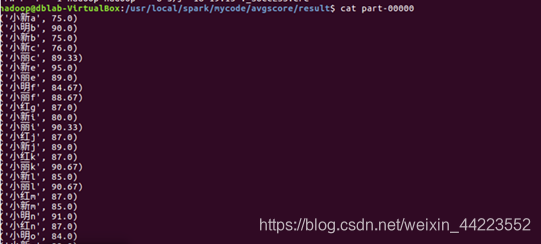
6、经验总结
经过这次的实验,对spark与rdd的有了更深层次的理解,首先要说Spark并不是一种解决问题的框架,而是这个框架的具体实现,而文中提出的新框架的名字叫做RDD弹性分布式数据集,RDD是分布式内存的一个抽象概念,是一种高度受限的内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象。它主要特点就是弹性和容错性。RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。RDD可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。
在spark中,你编写的代码会被spark转义为graph分发给work处理,因此要特别注意你写的代码被翻译之后会变成啥样。并且在翻译为graph时,因为要把任务分发出去,因此其中所有变量都必须是可以序列化的,因此就不能嵌套使用rdd等spark数据结构(如rdd的map方法中引用了外部rdd变量则会导致无法生成graph,程序在启动时就会马上报错),正确的使用方式应该是调用api如:union,join,group等。
此外,Spark 的核心是建立在统一的抽象弹性分布式数据集RDD之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
参考文献
[1] 林子雨《大数据技术原理与应用》2017.2[M]
[2]王家林等著. Scala语言基础与开发实战[M].北京:机械工程出版社,2016. [3]高彦杰.Spark大数据处理[M].北京:机械工业出版社,2014.