1,提交的离线任务完成之后,在一段时间后web端没有显示或者说自动消失:
原因分析:
https://blog.csdn.net/u013076044/article/details/104740792
是需要开启historyserver
2,Flink读取hdfs的(hive分区)文件,目前已知有三种方式:
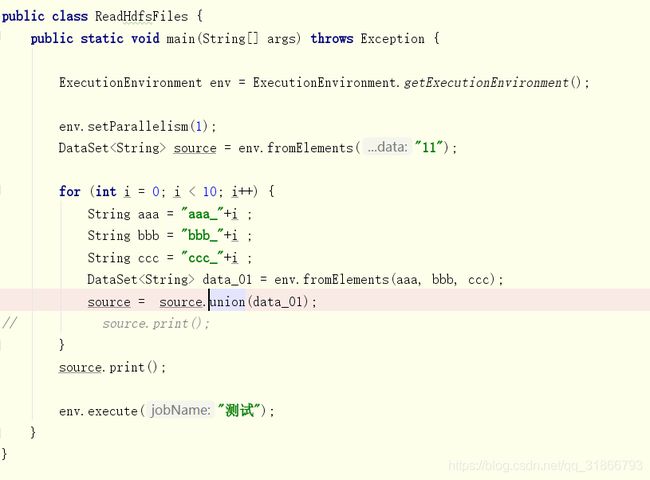
通过循环union方式,本地可以执行,集群提交报错
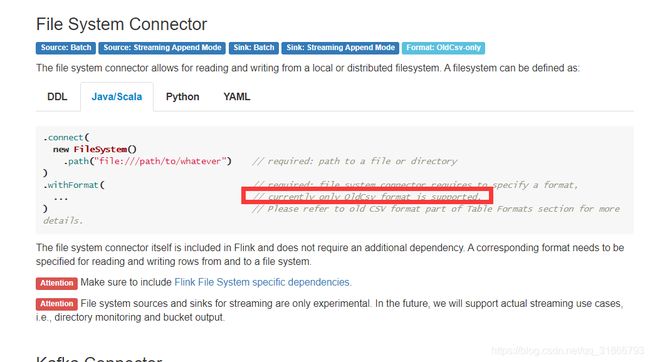
通过官方API,可是只支持csv文件格式,可以读取hdfs上的文件:
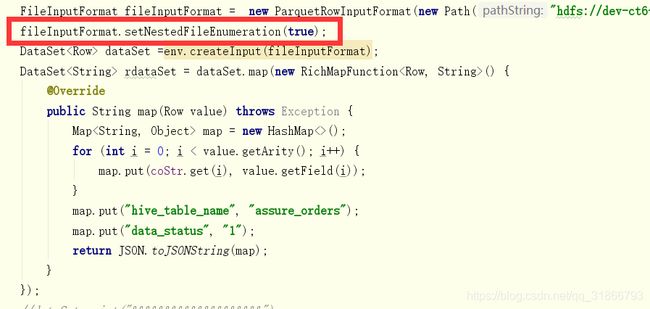
不在官方API的方式,正在测试….
参考:
背景:使用flink批作业 读取存在hdfs上的日志 需要迭代读取目录下所有文件的内容
使用的方法:
Configuration conf = new Configuration();
conf.setBoolean("recursive.file.enumeration", true);
DataSetin = env.readTextFile(urlWithDate).withParameters(conf);
但是由于日志数量比较大 出现akka链接超时问题
无法正常提交job
相关社区issue:
https://issues.apache.org/jira/browse/FLINK-3964
后来改用如下方法读取日志,成功解决:
FileInputFormat fileInputFormat = new TextInputFormat(new Path(urlWithDate));
fileInputFormat.setNestedFileEnumeration(true);
DataSetdataSet = env.readFile(fileInputFormat, urlWithDate);
1
2
3
相关mail-list参考:
http://mail-archives.apache.org/mod_mbox/flink-user/201701.mbox/
参考代码:
packagecom.zhisheng.sql.blink.stream.example;
importorg.apache.flink.api.common.typeinfo.Types;
importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
importorg.apache.flink.table.api.EnvironmentSettings;
importorg.apache.flink.table.api.Table;
importorg.apache.flink.table.api.java.StreamTableEnvironment;
importorg.apache.flink.table.descriptors.FileSystem;
importorg.apache.flink.table.descriptors.OldCsv;
importorg.apache.flink.table.descriptors.Schema;
importorg.apache.flink.types.Row;
/**
* Desc: Blink Stream Table Job
* Created by zhisheng on 2019/11/3下午1:14
* blog:http://www.54tianzhisheng.cn/
* 微信公众号:zhisheng
*/
public classTableExampleWordCount {public static voidmain(String[] args)throwsException {
StreamExecutionEnvironment blinkStreamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
blinkStreamEnv.setParallelism(1);
EnvironmentSettings blinkStreamSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment blinkStreamTableEnv = StreamTableEnvironment.create(blinkStreamEnv, blinkStreamSettings);
String path = TableExampleWordCount.class.getClassLoader().getResource("words.txt").getPath();
blinkStreamTableEnv
.connect(newFileSystem().path(path))
.withFormat(newOldCsv().field("word", Types.STRING).lineDelimiter("\n"))
.withSchema(newSchema().field("word", Types.STRING))
.inAppendMode()
.registerTableSource("FlieSourceTable");
Table wordWithCount = blinkStreamTableEnv.scan("FlieSourceTable")
.groupBy("word")
.select("word,count(word) as _count");
blinkStreamTableEnv.toRetractStream(wordWithCount, Row.class).print();//打印结果中的 true 和 false,可能会有点疑问,为啥会多出一个字段。
//Sink 做的事情是先删除再插入,false 表示删除上一条数据,true 表示插入该条数据blinkStreamTableEnv.execute("Blink Stream SQL Job");
}
}
任务提交到yarn集群无法运行
出现错误:
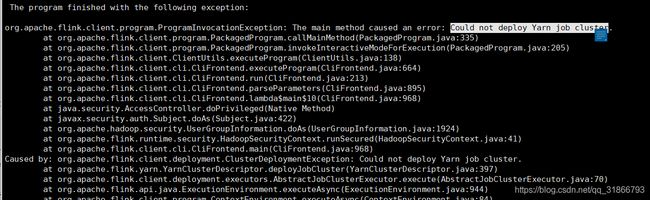
具体描述就是提交到任务到yarn之后,yarn一直处于等待状态,(jobManager)打印一堆日志之后然后出现上述报错
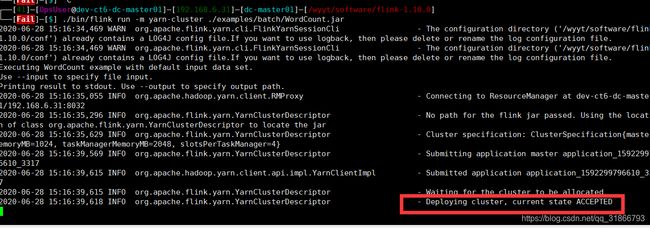
解决方案:
由于之前是部署的standalone高可用,导致可能是端口冲突,重置配置文件,去除无用的配置,就可以了 在yarn提交任务的时候 flink集群不用启动
本地代码提交的时候遇到问题:
Cannot support file system for 'hdfs' via Hadoop, because Hadoop is not in the classpath, or some classes are missing from the classpath.
解决方案:代码导入 flink-shaded-hadoop-2-uber-2.6.5-10.0.jar
正常集群lib目录下会有这个jar包的。
集群不能执行SQL任务
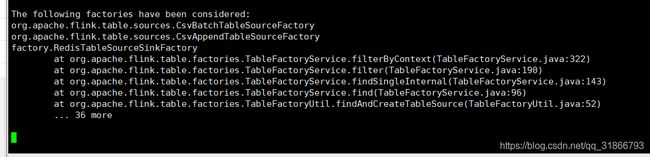
代码pom文件加入配置:
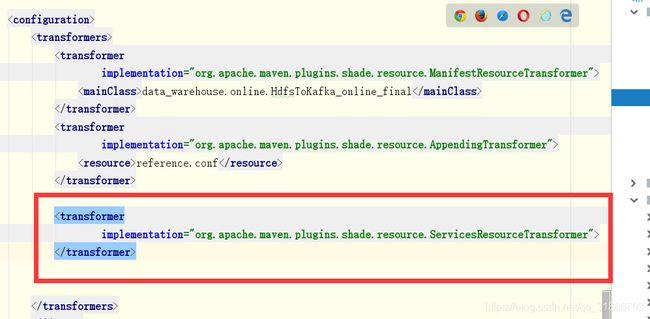
运行代码遇到:
org.codehaus.jackson.map.ObjectMapper.writerWithDefaultPrettyPrinter()Lorg/codehaus/jackson/map/ObjectWriter;
后来发现是依赖冲突,具体解决方案:
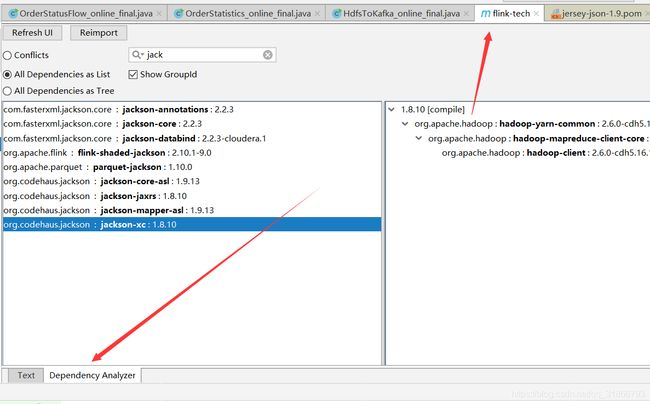
如果有红色就是冲突了,点击进去
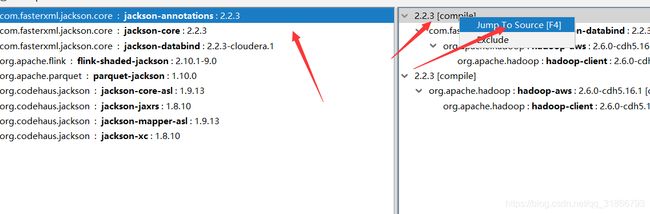
复制:

去对应的包解决掉 排除:

不支持将group by写入kafka
莫名其妙的本地找不到class,pom依赖被provide了。
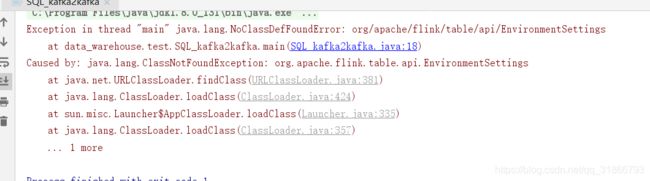
解决方案:
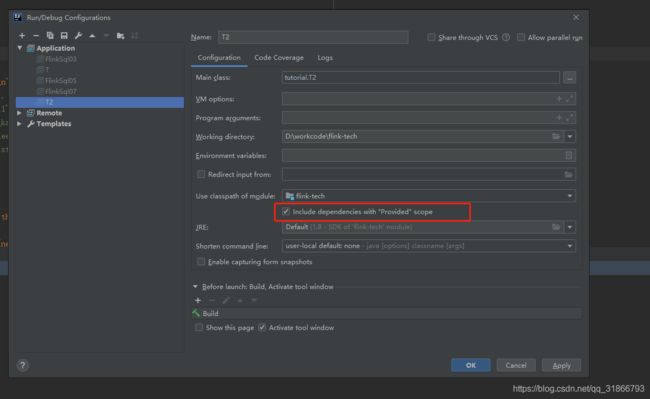
消费kafka发现数据消费的不对,因为消费kafka是指定的时间戳消费,必须要精确到毫秒,当时写入的是秒,所以还以为是代码业务问题。
Caused by: java.lang.OutOfMemoryError: Metaspace
后查证是 jvm Metaspace 大小受限制,默认是96M,设置为512M,在配置文件中设置 taskmanager.memory.jvm-metaspace.size: 512mb
尽量提交到集群的包小一点。
TTL状态过期:
@Overridepublic voidopen(Configuration parameters)throwsException {super.open(parameters);
ValueStateDescriptorvalueStateDescriptor =newValueStateDescriptor<>("lastUserLogin", TypeInformation.of(newTypeHint() {
}));//设置ttl 设置7天状态自动过期
// StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(7))
// .newBuilder(Time.seconds(60))
// .cleanupIncrementally(10, false)
// .build();
//
// valueStateDescriptor.enableTimeToLive(ttlConfig);valueState= getRuntimeContext().getState(valueStateDescriptor);
}