更新流程↓
Task 1: 简介和词向量Word Vectors
Task 2: 词向量和词义Word Senses
Task 3: 子词模型Subword Models
Task 4: Contextual Word Embeddings
Task 5: 大作业
日本人综艺感从昭和时代开始就这么强了吗?
今日份的舒适
常见餐桌礼仪
文章目录
1. ELMo
Allen实验室认为好的词表征应该同时兼顾两个问题:一是单词在语义和语法上的复杂特点;二是随着语言环境的改变,这些用法也应该随之变化。
为此,Allen实验室提出了deep contextualized word representation(深度情景化词表征)。这种算法的特点是每个词的表征都是整个输入语句的函数。
具体做法:
- 现在大语料上以 language model为目标训练处 Bi-LSTM模型,利用它产生词语的表征 (pre-trained biLM模型)。ELMo因此得名embedding from language model。
- 为了应用在下游NLP任务中,一般先利用下游任务的语料库(此时,忽略掉label)进行 language model的微调(fine tuning),这种微调相当于一种domain transfer。
- 然后才是利用label的信息进行supervised learning。
ELMo表征是“深”的,就是说它们是biLM的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层的LSTM的状态可以捕捉词语意义中和语境相关的那方面的特征(比如可以用来做语义的消歧),而低层的LSTM可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,在下游的NLP任务中会体现优势。

1.1. Bidirectional language models
ELMo顾名思义是从Language Models得来的embeddings,确切的说是来自于Bidirectional language models。具体可以表示为:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . , t k − 1 ) 和 p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p(t_1,t_2,...,t_N)=\prod_{k=1}^{N}p(t_k|t_1,t_2,...,t_{k-1})和p(t_1,t_2,...,t_N)=\prod_{k=1}^{N}p(t_k|t_{k+1},t_{k+2},...,t_N)p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)和p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)
这里( t 1 , t 2 , . . . , t N ) (t_1,t_2,...,t_N)(t1,t2,...,tN)的是一系列的tokens,作为语言模型可能有不同的表达方法,最经典的方法是利用多层的LSTM,ELMo的语言模型也采取了这种方式。所以这个Bidirectional LM由stacked bidirectional LSTM来表示。
假设输入是t o k e n tokentoken的表示x k L M x_k^{LM}xkLM。在每一个位置k kk,每一层LSTM上都输出相应的context-dependent的表征h ⃗ k , j L M \vec{h}_{k,j}^{LM}hk,jLM,j = 1 , 2 , . . . , L j=1,2,...,Lj=1,2,...,L,j jj代表LSTM的某层layer。例如顶层的LSTM的输出可以表示为:h ⃗ k , j L M \vec{h}_{k,j}^{LM}hk,jLM,通过Softmax层来预测下一个token t k + 1 t_{k+1}tk+1。
最开始两个概率的对数极大似然估计Loglikehood表达如下:
L o g l i k e h o o d = ∑ k = 1 N ( l o g p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ ⃗ L S T M , Θ s ) + l o g p ( t k ∣ t k + 1 , . . . , t N ; Θ x , Θ ← L S T M , Θ s ) ) Loglikehood=\sum_{k=1}^{N}(log\, p(t_k|t_1,...,t_{k-1};\Theta_x,\vec{\Theta}_{LSTM},\Theta_s)+log\,p(t_k|t_{k+1},...,t_N;\Theta_x,\overleftarrow{\Theta}_{LSTM},\Theta_s))Loglikehood=k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,...,tN;Θx,ΘLSTM,Θs))
这里的Θ x Θ_xΘx代表token embedding, Θ s Θ_sΘs代表softmax layer的参数。
1.2. ELMo
对于每一个token,一个L LL层的biLM要计算出共2 L + 1 2L+12L+1个表征:
R k = { x k L M , h ⃗ k , j L M , h ← k , j L M j = 1 , . . . , L h k , j L M j = 0 , . . . , L R_k=\left\{\begin{matrix} x_k^{LM},\vec{h}_{k,j}^{LM},\overleftarrow{h}_{k,j}^{LM}&j=1,...,L\\ \\ h_{k,j}^{LM}&j=0,...,L \end{matrix}\right.Rk=⎩⎪⎨⎪⎧xkLM,hk,jLM,hk,jLMhk,jLMj=1,...,Lj=0,...,L 这里h k , j L M h_{k,j}^{LM}hk,jLM是简写,当j = 0 j=0j=0时,代表token层。j > 0 j>0j>0时,同时包括两个方向的h i d d e n hiddenhidden表征。
在下游的任务中, ELMo把所有层的R压缩在一起形成一个单独的vector。(在最简单的情况下,可以只保留最后一层的h k , j L M h_{k,j}^{LM}hk,jLM。) E L M o k t a s k = E ( R k ; Θ t a s k ) = γ t a s k ∑ j = 0 L s j t a s k h k , j L M ( 1 ) ELMo_k^{task}=E(R_k;Θ^{task})=\gamma^{task}\sum_{j=0}^{L}s_j^{task}h_{k,j}^{LM}\; \; \; (1)ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtaskhk,jLM(1)
具体来讲如何使用ElMo产生的表征呢?对于一个supervised NLP任务,可以分以下三步:
- 产生pre-trained biLM模型。模型由两层bi-LSTM组成,之间用residual connection连接起来。
- 在任务语料上(注意是语料,忽略label)fine tuning上一步得到的biLM模型。可以把这一步看为biLM的domain transfer。
- 利用ELMo的word embedding来对任务进行训练。通常的做法是把它们作为输入加到已有的模型中,一般能够明显的提高原模型的表现。
2.GPT
GPT的核心思想是先通过无标签的文本去训练生成语言模型,再根据具体的NLP任务(如文本蕴涵、QA、文本分类等),来通过有标签的数据对模型进行fine-tuning。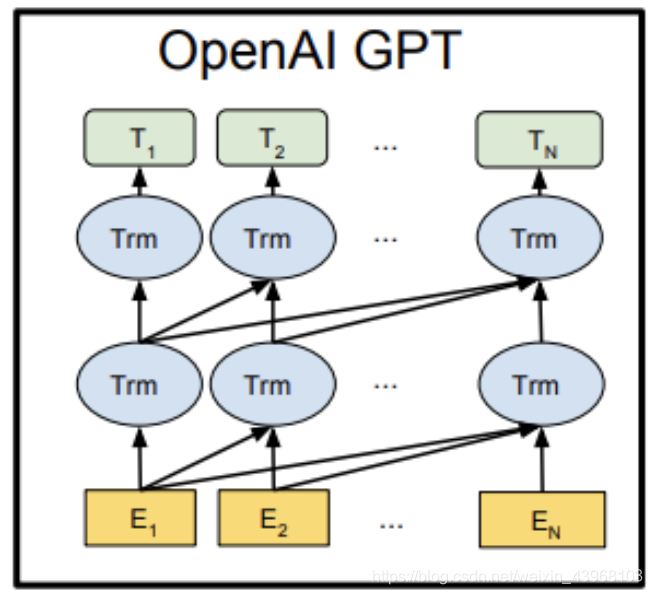
具体来说,在这篇论文中提出了半监督的方法,即结合了无监督的预训练和有监督的fine-tuning。论文采用两阶段训练。首先,在未标记数据集上训练语言模型来学习神经网络模型的初始参数。随后,使用相应NLP任务中的有标签的数据地将这些参数微调,来适应当前任务。
模型的结构是使用了多层的单向Transformer结构(《Attention is All you need》提出)。下图是GPT语言模型的结构:
2.1. 无监督的预训练
对于无标签的文本U = { u 1 , u 2 , . . . , u n } U=\{u_1,u_2,...,u_n\}U={u1,u2,...,un},最大化语言模型的极大似然函数:L 1 ( u ) = ∑ l o g P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(u)=\sum log \;P(u_i|u_{i-k},...,u_{i-1};\Theta)L1(u)=∑logP(ui∣ui−k,...,ui−1;Θ) 这里的k kk是文本上下文窗口的大小。
论文中使用的是多层Transformer的decoder的语言模型,input为词嵌入以及单词token的位置信息;再对transformer_block的输出向量做softmax,output为词的概念分布。具体公式如下:
h 0 = U W e + W p H l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) ∀ i ∈ [ i , n ] P ( u ) = s o f t m a x ( h n W e T ) \begin{matrix}h_0=UW_e+W_p\\H_l=transformer\_block(h_{l-1})\forall i\in[i,n]\\ P(u)=softmax(h_nW_e^T)\end{matrix}h0=UWe+WpHl=transformer_block(hl−1)∀i∈[i,n]P(u)=softmax(hnWeT) 这里U = { u i − k , . . . , u i − 1 } U=\{u_{i-k},...,u_{i-1}\}U={ui−k,...,ui−1}表示u i u_iui的上下文,W e W_eWe是词向量矩阵,W p W_pWp是位置向量矩阵。
2.2. 有监督的fine-tuning
在对模型预训练之后,采用有监督的目标任务对模型参数微调。假设一个有标签的数据集,假设每一条数据为一个单词序列x 1 , . . . , x m x_{1}, . . . , x_{m}x1,...,xm以及相应的标签y yy,通过之前预训练的模型获得输出向量h l m h_{l}^{m}hlm,再送入线性输出层,来预测标签y yy
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,...,x^m)=softmax(h_l^mW_y)P(y∣x1,...,xm)=softmax(hlmWy) Loss函数为:L 2 ( C ) = ∑ x , y l o g P ( y ∣ x 1 , . . . , x m ) L_2(C)=\sum_{x,y} log\;P(y|x^1,...,x^m)L2(C)=x,y∑logP(y∣x1,...,xm) 最后,将两阶段的目标函数通过超参λ \lambdaλ相加训练整个模型:L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(C)=L_2(C)+\lambda L_1(C)L3(C)=L2(C)+λL1(C)
2.3. 具体任务的模型微调
对于文本分类,只需要在预训练模型上微调。对于QA任务或者文本蕴含,因为预训练模型是在连续序列上训练,需要做一些调整,修改输入结构,将输入转化为有序序列输入
文本蕴含 :将前提p pp和假设h hh序列拼接,中间用($)符号来分隔两个序列。
文本相似度:分别将两个序列输入,通过模型输出两个序列的特征向量,再逐元素相加输入线性层。
问答和常识推理:给定上下文文本z zz,问题q qq,一组可能的候选答案 { a k } \{a_k\}{ak},将上下文文本、问题以及每个候选答案拼接起来,得到这样一个序列[ z ; q ; [z;q;[z;q; $ ; a k ] ;a_k];ak],再将该序列输入预训练模型,经softmax层得到候选答案的概率分布。
3. BERT
Bert(原文)是谷歌的大动作,公司AI团队新发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT采用了Transformer Encoder的模型来作为语言模型,Transformer模型来自于经典论文《Attention is all you need》, 完全抛弃了RNN/CNN等结构,而完全采用Attention机制来进行input-output之间关系的计算,如下图中左半边部分所示: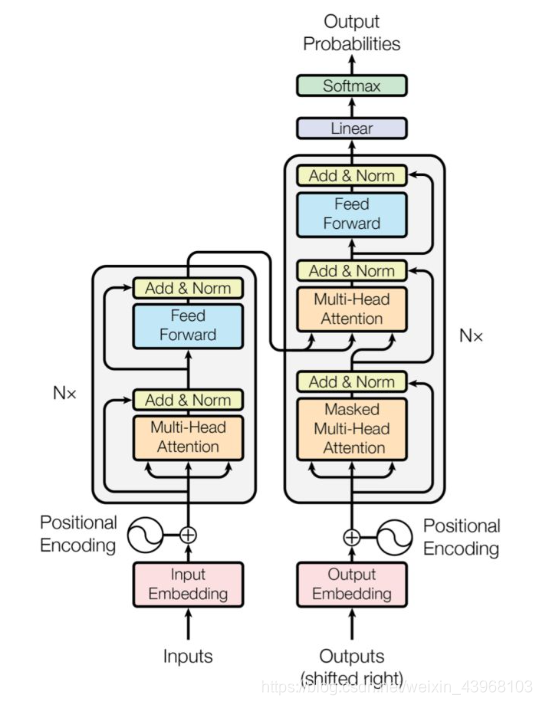
Bert模型结构如下: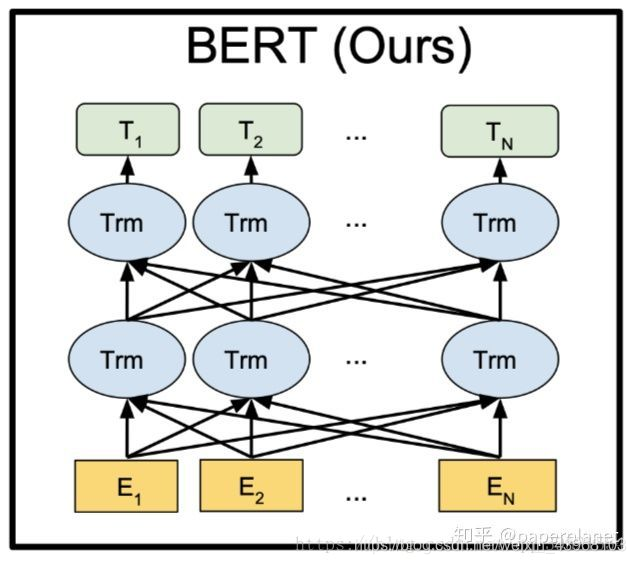
BERT模型与OpenAI GPT的区别就在于采用了Transformer Encoder,也就是每个时刻的Attention计算都能够得到全部时刻的输入,而OpenAI GPT采用了Transformer Decoder,每个时刻的Attention计算只能依赖于该时刻前的所有时刻的输入,因为OpenAI GPT是采用了单向语言模型。