python爬取图片并下载
代码涉及的相关网站链接,仅供参考
import urllib3
from bs4 import BeautifulSoup
# 获取模拟头
def getHeader():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
return headers
# 下载图片
def downloadImg(fileName,url):
http=urllib3.PoolManager()
res=http.request("GET", url)
data = res.data
img_file=open(fileName,"wb+")
img_file.write(data)
img_file.close()
# 爬取图片链接
def testBS():
# 爬取页面
targetFolder="C:/Users/weiyongjian/Desktop/image/"
url = "https://www.51miz.com/so-sucai/134026.html"
method = "GET"
headers=getHeader()
print(headers)
http = urllib3.PoolManager()
res = http.request(method, url, headers=headers)
html = res.data
# 清洗数据
bb = BeautifulSoup(html, "html.parser")
imags = bb.find_all("img")
i = 0
# 下载图片
for img in imags:
img_url =img.get("data-original")
i += 1
downloadImg(targetFolder+f"img{i}.jpg", img_url)
if __name__ == "__main__":
testBS()
如图所示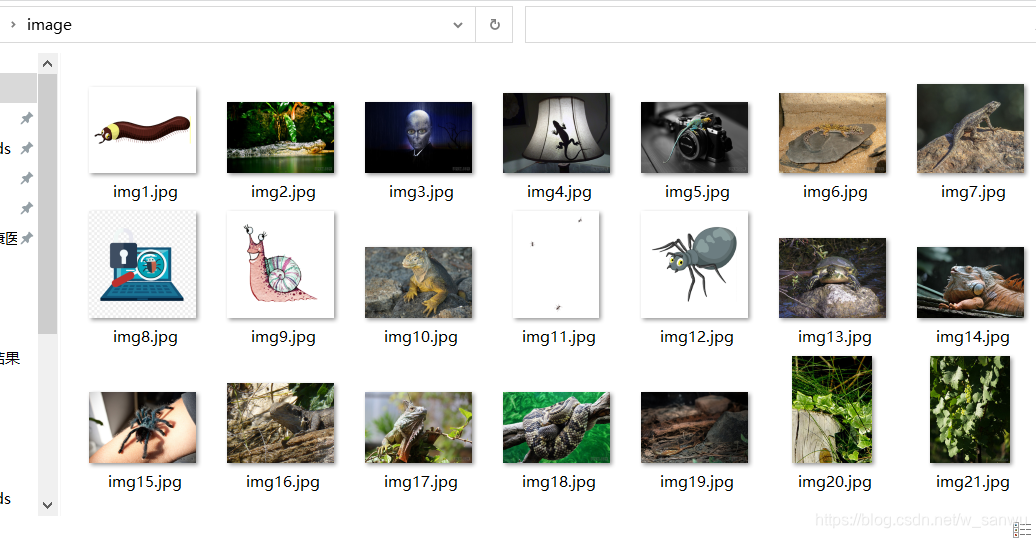
版权声明:本文为w_sanwu原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。