目录
1. 项目背景
网购已经成为人们生活不可或缺的一部分,本次项目基于淘宝app平台数据,通过相关指标对用户行为进行分析,从而探索用户相关行为模式。
提出问题
1.日PV有多少
2.日UV有多少
3.付费率情况如何
4.复购率是多少
5.漏斗流失情况如何
6.用户价值情况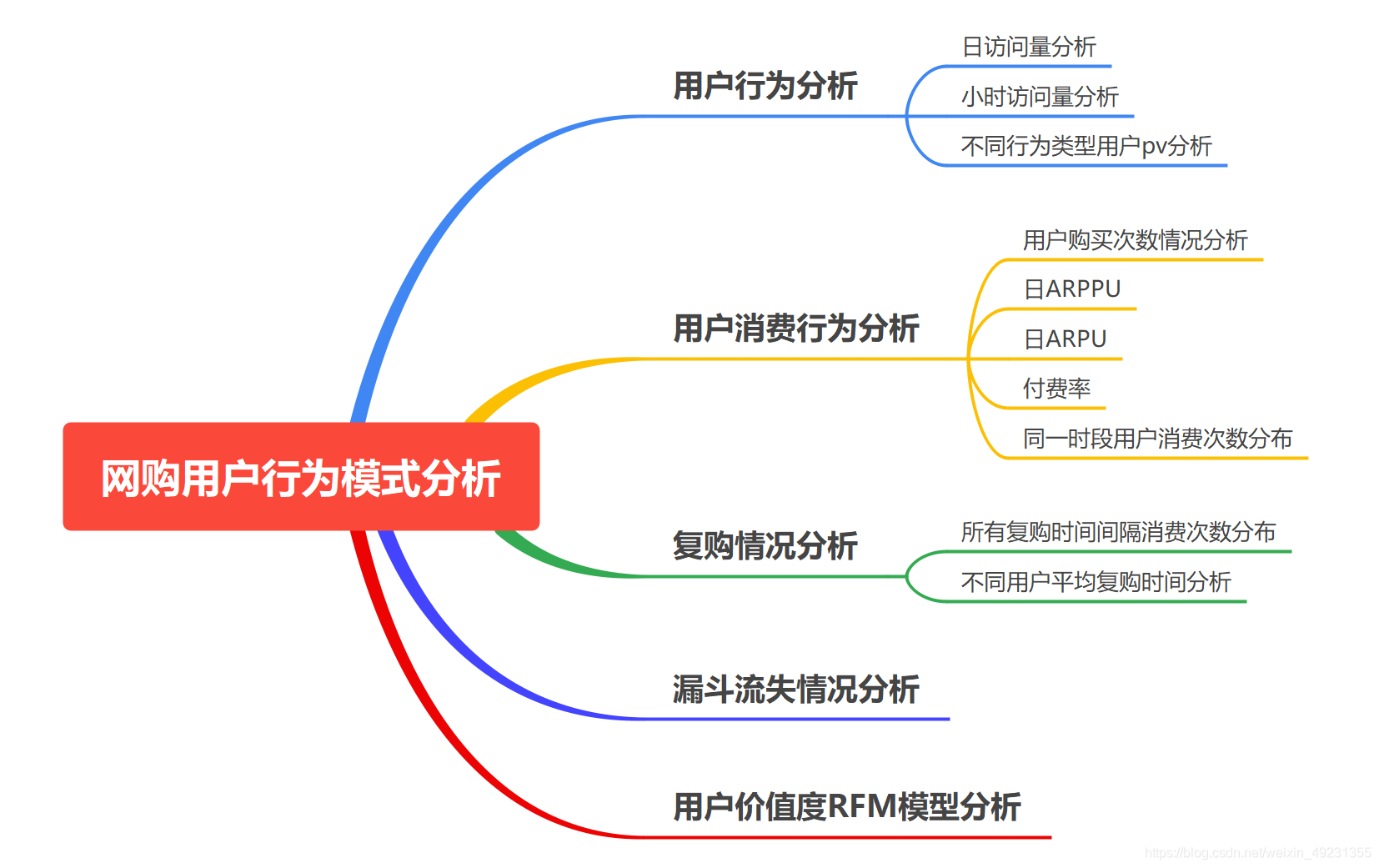
漏斗流失分析
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点 各阶段用户转化率情况的重要分析模型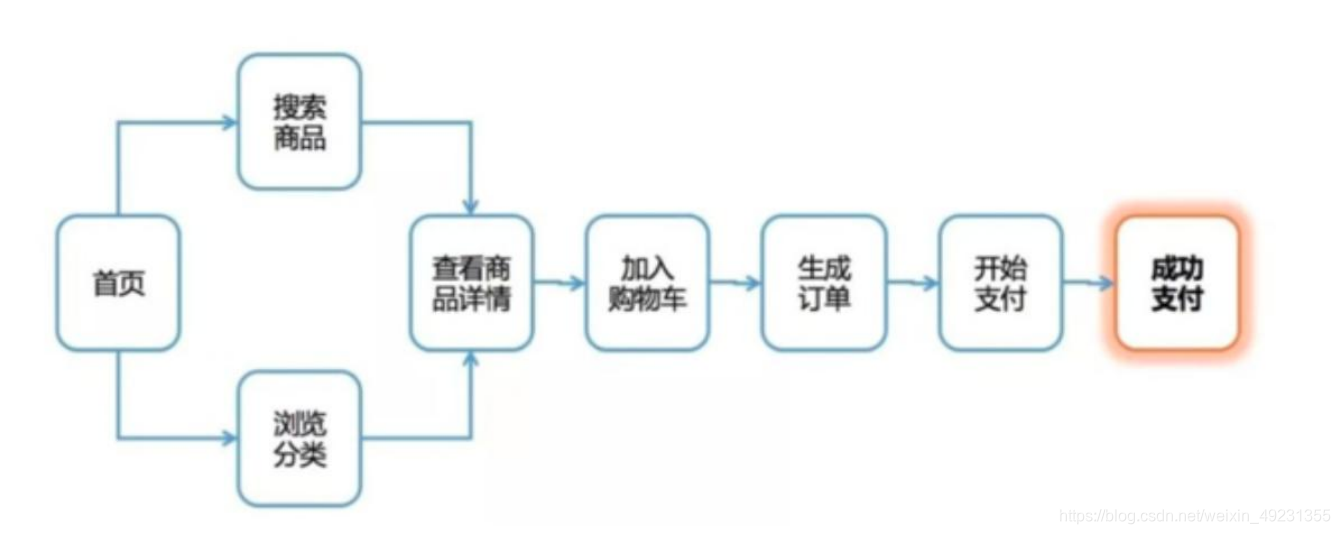
RFM模型
用户分类(RFM模型),对比分析不同用户群体在时间、地区等维度下交易量, 交易金额指标,并根据分析结果提出优化建议
- R: 最近一次消费时间(最近一次消费到参考时间的长度)
- F: 消费的频次(单位时间内消费了多少次)
- M:消费的金额(单位时间内总消费金额)
| R | F | M | 用户分类 | 相应策略 |
|---|---|---|---|---|
| 高 | 高 | 高 | 重要价值用户 | RFM得分都高于平均值,属于优质客户,需要保持 |
| 低 | 高 | 高 | 重点保持用户 | 交易金额和交易次数都很大,但最近交易很少,需要唤回 |
| 高 | 低 | 高 | 重点发展用户 | 交易金额大贡献度高,且最近有交易,需要重点识别 |
| 高 | 高 | 低 | 重点挽留用户 | 交易次数多且最近有交易,但交易金额较小,需要挖掘客户需求 |
| 低 | 低 | 高 | 一般价值用户 | 交易金额大,但最近交易很少,且交易次数少,需要挽留 |
| 低 | 高 | 低 | 一般保持用户 | 交易次数多,但贡献不大,一般保持 |
| 高 | 低 | 低 | 一般发展用户 | 最近有交易,属于新客户,有推广价值 |
| 低 | 低 | 低 | 一般挽留用户 | RFM得分都低于平均值,最近再没有交易,属于流失 |
2. 理解数据
2.1 导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import plotly as py
import plotly.graph_objs as go
py.offline.init_notebook_mode()
pyplot=py.offline.iplot
import seaborn as sns
sns.set(style='darkgrid',context='notebook',font_scale=1.5)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import warnings
warnings.filterwarnings('ignore')
2.2 导入数据
data_user=pd.read_csv('tianchi_mobile_recommend_train_user.csv',dtype=str)
data_user.head()
user_id item_id behavior_type user_geohash item_category time
0 98047837 232431562 1 NaN 4245 2014-12-06 02
1 97726136 383583590 1 NaN 5894 2014-12-09 20
2 98607707 64749712 1 NaN 2883 2014-12-18 11
3 98662432 320593836 1 96nn52n 6562 2014-12-06 10
4 98145908 290208520 1 NaN 13926 2014-12-16 21
查看数据,列字段分别是:
- user_id:用户身份,脱敏
- item_id:商品ID,脱敏
- behavior_type:用户行为类型(包含点击、收藏、加购物车、支付四种行为,分别用数字1、2、3、4表示)
- user_geohash:地理位置
- item_category:品类ID(商品所属的品类)
- time:用户行为发生的时间
data_user.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12256906 entries, 0 to 12256905
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 user_id object
1 item_id object
2 behavior_type object
3 user_geohash object
4 item_category object
5 time object
dtypes: object(6)
memory usage: 561.1+ MB
3. 数据预处理
3.1 缺失值处理
#统计缺失值
data_user.apply(lambda x:sum(x.isnull()),axis=0)
user_id 0
item_id 0
behavior_type 0
user_geohash 8334824
item_category 0
time 0
dtype: int64
data_user.apply(lambda x:sum(x.isnull())/len(x),axis=0)
user_id 0.00000
item_id 0.00000
behavior_type 0.00000
user_geohash 0.68001
item_category 0.00000
time 0.00000
dtype: float64
- 存在缺失值的是User_geohash,有8334824条,缺失率0.68,不能删除缺失值,因为地理信息在数据集收集过程中做过加密转换,因此对数据集不做处理。
3.2 一致化处理
用户行为发生的时间由日期和小时构成,需要将该列进行拆分
#拆分数据集
data_user['date']=data_user['time'].str[0:10].str.strip()
data_user['hour']=data_user['time'].str[11:].str.strip()
data_user.head()
user_id item_id behavior_type user_geohash item_category time date hour
0 98047837 232431562 1 NaN 4245 2014-12-06 02 2014-12-06 02
1 97726136 383583590 1 NaN 5894 2014-12-09 20 2014-12-09 20
2 98607707 64749712 1 NaN 2883 2014-12-18 11 2014-12-18 11
3 98662432 320593836 1 96nn52n 6562 2014-12-06 10 2014-12-06 10
4 98145908 290208520 1 NaN 13926 2014-12-16 21 2014-12-16 21
# 查看data_user数据集数据类型:
data_user.dtypes
user_id object
item_id object
behavior_type object
user_geohash object
item_category object
time object
date object
hour object
dtype: object
#数据类型转换:time,date应该为日期格式,hour应该为整数型
data_user['time']=pd.to_datetime(data_user['time'])
data_user['date']=pd.to_datetime(data_user['date'])
data_user['hour']=data_user['hour'].astype('int64')
#检查数据类型转换结果
data_user.dtypes
user_id object
item_id object
behavior_type object
user_geohash object
item_category object
time datetime64[ns]
date datetime64[ns]
hour int64
dtype: object
3.3 异常值处理
#对数据按照time字段进行排序处理
data_user.sort_values(by='time',ascending=True,inplace=True)
#重建索引
data_user.reset_index(drop=True,inplace=True)
data_user.head()
user_id item_id behavior_type user_geohash item_category time date hour
0 73462715 378485233 1 NaN 9130 2014-11-18 2014-11-18 0
1 36090137 236748115 1 NaN 10523 2014-11-18 2014-11-18 0
2 40459733 155218177 1 NaN 8561 2014-11-18 2014-11-18 0
3 814199 149808524 1 NaN 9053 2014-11-18 2014-11-18 0
4 113309982 5730861 1 NaN 3783 2014-11-18 2014-11-18 0
#查看统计量
data_user.describe(include=['object'])
user_id item_id behavior_type user_geohash item_category
count 12256906 12256906 12256906 3922082 12256906
unique 10000 2876947 4 575458 8916
top 36233277 112921337 1 94ek6ke 1863
freq 31030 1445 11550581 1052 393247
- 通过观察数据集的统计等,发现数据集并无异常值存在。
4. 构建模型(用户行为分析)
4.1 pv和uv分析
PV(访问量):即Page View, 具体是指网站的页面浏览量或者点击量,页面被刷新一次就计算一次。
UV(独立访客):即Unique Visitor,访问网站的一台电脑客户端为一个访客。
(1)每天访问量分析
# pv_daily记录每天用户操作次数
pv_daily=data_user.groupby('date').count()['user_id'].rename()
pv_daily.head()
date
2014-11-18 366701
2014-11-19 358823
2014-11-20 353429
2014-11-21 333104
2014-11-22 361355
dtype: int64
# uv_daily记录每天不同的上线用户数量
uv_daily=data_user.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count())
uv_daily.head()
date
2014-11-18 6343
2014-11-19 6420
2014-11-20 6333
2014-11-21 6276
2014-11-22 6187
Name: user_id, dtype: int64
#将两个数据进行合并
pv_uv_daily=pd.concat([pv_daily,uv_daily],axis=1)
pv_uv_daily.rename(columns={0:'pv','user_id':'uv'},inplace=True)
pv_uv_daily.head()
pv uv
date
2014-11-18 366701 6343
2014-11-19 358823 6420
2014-11-20 353429 6333
2014-11-21 333104 6276
2014-11-22 361355 6187
#pv与uv相关性研究
corr=pv_uv_daily.corr(method='pearson')
print('访问量与访问用户数的相关系数为:{:.2f}'.format(corr.iloc[0,1]))
访问量与访问用户数的相关系数为:0.92
#每天访问量情况可视化
plt.figure(figsize=(16,9))
plt.subplot(211)
plt.plot(pv_daily,color='red')
plt.title('网页访问量每日变化趋势')
plt.xticks(fontsize=10)
plt.subplot(212)
plt.plot(uv_daily,color='green')
plt.title('用户访问量每日变化趋势')
plt.xticks(fontsize=10)
plt.suptitle('PV和UV变化趋势',size=30)
plt.show()
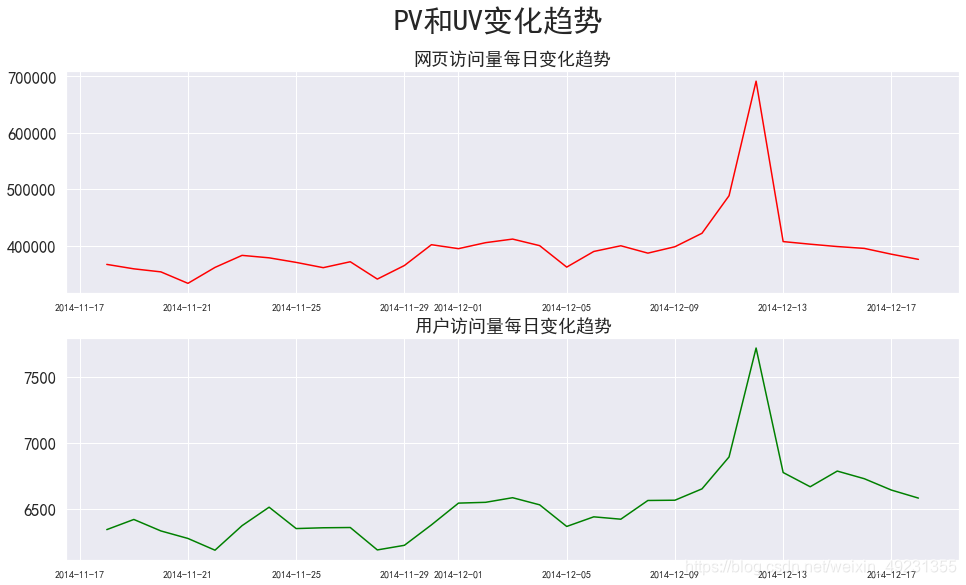
- 通过图形观察,发现在双十二期间,pv和uv访问量达到峰值,并且可以发现,uv和pv两个访问量数值差距比较大
(2)小时访问量分析
# pv_hourly记录每小时用户操作次数
pv_hourly=data_user.groupby('hour').count()['user_id'].rename()
pv_hourly.head()
hour
0 517404
1 267682
2 147090
3 98516
4 80487
dtype: int64
# uv_hourly记录每小时的上线用户数量
uv_hourly=data_user.groupby('hour')['user_id'].apply(lambda x:x.drop_duplicates().count())
uv_hourly.head()
hour
0 5786
1 3780
2 2532
3 1937
4 1765
Name: user_id, dtype: int64
#将两个数据进行合并
pv_uv_hourly=pd.concat([pv_hourly,uv_hourly],axis=1)
pv_uv_hourly.rename(columns={0:'pv','user_id':'uv'},inplace=True)
pv_uv_hourly.head()
pv uv
hour
0 517404 5786
1 267682 3780
2 147090 2532
3 98516 1937
4 80487 1765
#二者相关性
corr=pv_uv_hourly.corr(method='spearman')
print('访问量与访问用户数的相关系数为:{:.2f}'.format(corr.iloc[0,1]))
访问量与访问用户数的相关系数为:0.90
#每小时访问量情况可视化
plt.figure(figsize=(16,9))
pv_uv_hourly['pv'].plot(color='steelblue',label='每个小时的访问量')
plt.legend(loc='upper left')
plt.ylabel('每小时访问量',labelpad=20)
pv_uv_hourly['uv'].plot(color='red',secondary_y=True,label='每个小时的不同用户访问量')
plt.legend(loc='upper center')
plt.ylabel('每小时访问用户量',labelpad=20)
plt.xticks(range(0,24),pv_uv_hourly.index)
plt.grid(True)
plt.show()
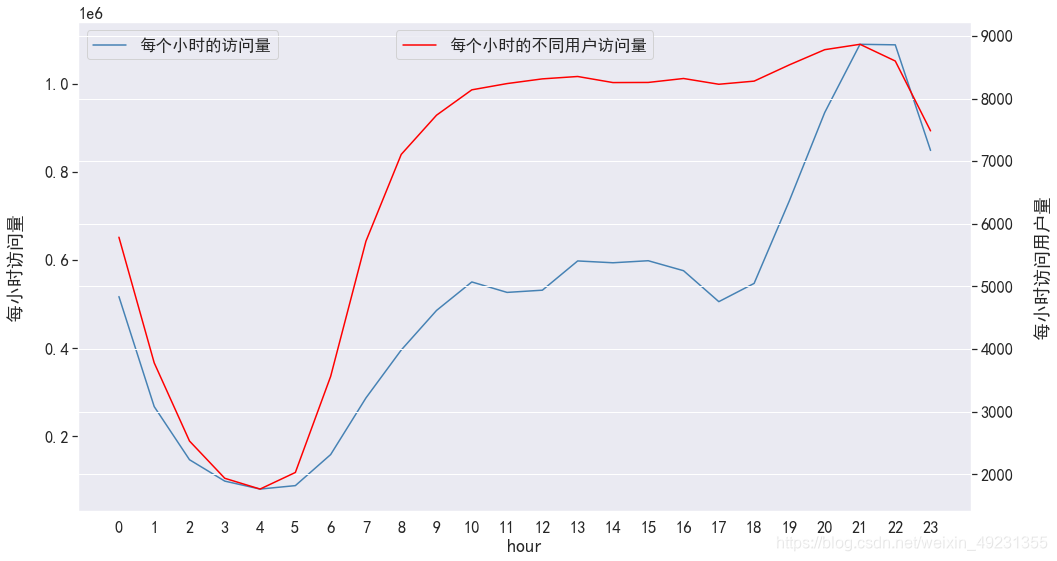
- pv和uv在凌晨0-5点期间波动情况相同,都呈下降趋势,访问量都比较小,同时在晚上18:00左右,pv波动情况比较剧烈,相比来看uv不太明显,因此晚上18:00以后是淘宝用户访问app的活跃时间段。
(3)不同行为类型用户pv分析
# 计算不同的用户行为,在每个小时的访问量
pv_detail=pd.pivot_table(columns='behavior_type',index='hour',data=data_user,\
values='user_id',aggfunc=np.size)
pv_detail.head()
behavior_type 1 2 3 4
hour
0 487341 11062 14156 4845
1 252991 6276 6712 1703
2 139139 3311 3834 806
3 93250 2282 2480 504
4 75832 2010 2248 397
#数据可视化
plt.figure(figsize=(12,8))
sns.lineplot(data=pv_detail)
plt.show()
plt.figure(figsize=(12,8))
sns.lineplot(data=pv_detail.iloc[:,1:])
plt.show()
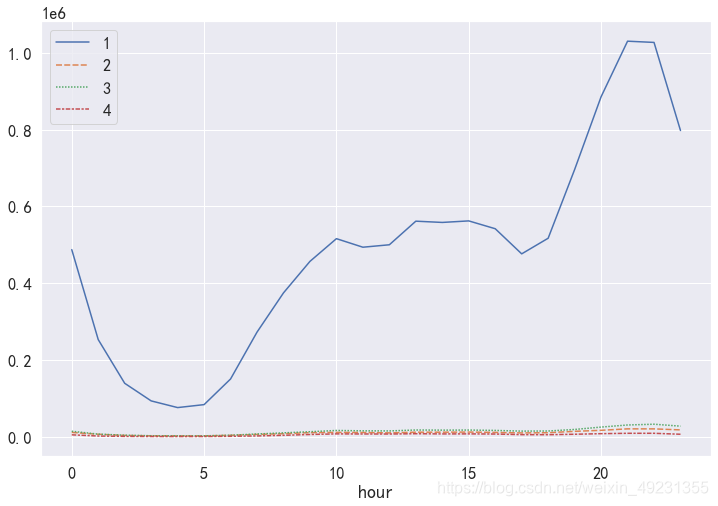
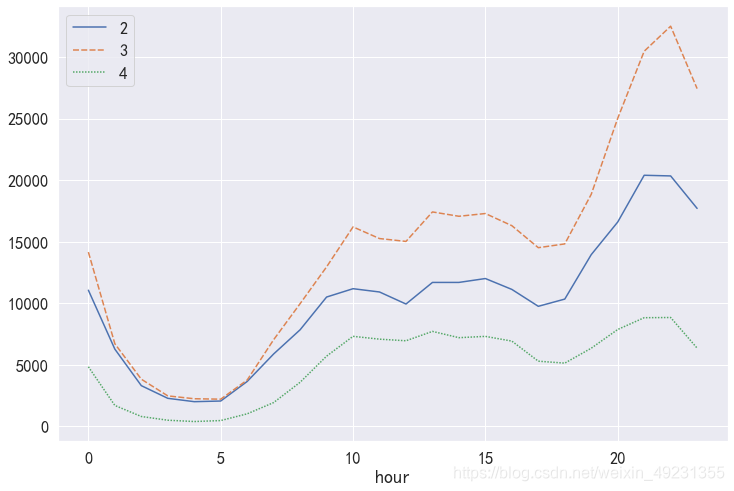
- 通过图发现,点击这一用户行为相比较于其他三类用户行为,pv访问量较高,同时四种用户行为的波动情况基本一致,因此晚上这一时间段不管哪一种用户行为,pv访问量都是最高的。
可以看出,加入购物车这一用户行为的pv总量高于收藏的总量,因此在后续漏斗流失分析中,用户类型3应该在2之前分析。
4.2 用户消费行为分析
(1)用户购买次数情况分析
# 取出支付的用户
data_user_buy=data_user[data_user.behavior_type=='4'].groupby('user_id').size()
data_user_buy.describe()
count 8886.000000
mean 13.527459
std 19.698786
min 1.000000
25% 4.000000
50% 8.000000
75% 17.000000
max 809.000000
dtype: float64
plt.hist(x=data_user_buy,bins=100)
plt.show()
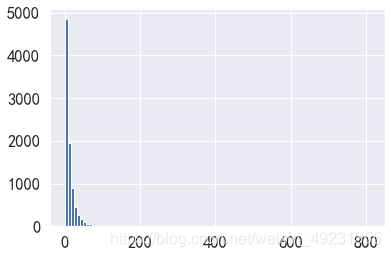
- 图表显示:淘宝用户消费次数普遍在10次以内,因此需要重点关注购买次数在10次以上的消费者用户群体。
(2)分析日ARPPU
- ARPPU(average revenue per paying user)是指从每位付费用户身上获得的收入,它反映的是每个付费用户的平均付费额度
- ARPPU=总收入/活跃用户付费数量
- 本数据集中没有消费金额,因此在计算过程中用消费次数代替消费金额
# 人均消费次数=消费总次数/消费人数
data_user_buy1=data_user[data_user.behavior_type=='4'].groupby(['date','user_id'])['behavior_type'].\
count().reset_index().rename(columns={'behavior_type':'total'})
data_user_buy1.head()
date
2014-11-18 3730
2014-11-19 3686
2014-11-20 3462
2014-11-21 3021
2014-11-22 3570
Name: total, dtype: int64
#统计每天的消费总次数
data_user_buy1.groupby('date').sum()['total'].head()
#统计每天的消费人数
data_user_buy1.groupby('date').count()['user_id'].head()
#计算每天的人均消费次数
data_user_buy2=data_user_buy1.groupby('date').sum()['total']/data_user_buy1.groupby('date').count()['total']
data_user_buy2.head()
date
2014-11-18 2.423652
2014-11-19 2.439444
2014-11-20 2.320375
2014-11-21 2.271429
2014-11-22 2.530120
Name: total, dtype: float64
data_user_buy2.describe()
data_user_buy2.plot()
plt.show()
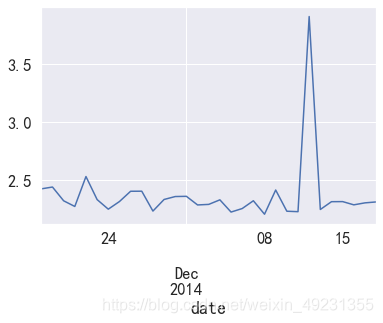
- 平均每天消费次数在2-3次之间波动,双十二期间消费次数达到最高值。
(3)日ARPU情况
- ARPU(Average Revenue Per User) :平均每用户收入,可通过 总收入/AU 计算得出。它可以衡量产品的盈利能力和发展活力。
- 活跃用户数平均消费次数=消费总次数/活跃用户人数(每天有操作行为的为活跃)
data_user['operation']=1
data_user_buy3=data_user.groupby(['date','user_id','behavior_type'])['operation'].count().reset_index()
data_user_buy3=data_user_buy3.rename(columns={'operation':'total'})
data_user_buy3.head()
date user_id behavior_type total
0 2014-11-18 100001878 1 127
1 2014-11-18 100001878 3 8
2 2014-11-18 100001878 4 1
3 2014-11-18 100014060 1 23
4 2014-11-18 100014060 3 2
data=data_user_buy3.groupby('date').apply(lambda x:x[x['behavior_type']=='4'].total.sum()/
len(x.user_id.unique()))
data.head()
date
2014-11-18 0.588050
2014-11-19 0.574143
2014-11-20 0.546660
2014-11-21 0.481358
2014-11-22 0.577016
dtype: float64
data.plot()
plt.show()
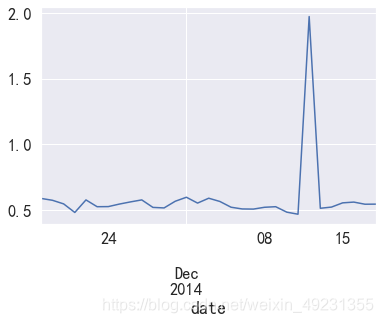
- 淘宝活跃用户(有过操作行为的用户)平均每天消费次数比较低,在0.58次左右,双十二期间达到最高值,有2次左右。
(4)付费率
- 付费率=消费人数/活跃用户人数
data=data_user_buy3.groupby('date').apply(lambda x:x[x['behavior_type']=='4'].total.count()/
len(x.user_id.unique()))
data.head()
date
2014-11-18 0.242630
2014-11-19 0.235358
2014-11-20 0.235591
2014-11-21 0.211918
2014-11-22 0.228059
dtype: float64
data.describe()
count 31.000000
mean 0.241566
std 0.050087
min 0.210183
25% 0.225660
50% 0.235358
75% 0.240304
max 0.504793
dtype: float64
data.plot()
plt.show()
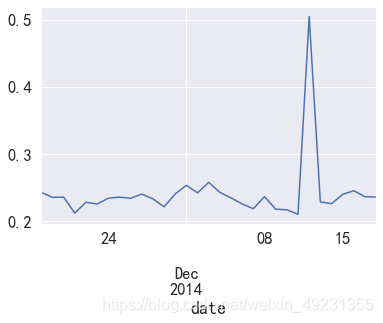
- 每天活跃用户人群中,大概24%的用户具有消费行为,在双十二期间消费用户人数最多。
(5)同一时间段用户消费次数分布
data_user_buy4=data_user[data_user['behavior_type']=='4'].groupby(['user_id','date','hour'])['operation'].sum().rename('buy_count')
data_user_buy4
user_id date hour
100001878 2014-11-18 20 1
2014-11-24 20 3
2014-11-25 13 2
2014-11-26 16 2
21 1
..
99989881 2014-12-05 1 1
2014-12-09 21 1
2014-12-12 0 2
2014-12-14 20 1
2014-12-15 23 1
Name: buy_count, Length: 65223, dtype: int64
data_user_buy4.describe()
count 65223.000000
mean 1.842985
std 2.295531
min 1.000000
25% 1.000000
50% 1.000000
75% 2.000000
max 97.000000
Name: buy_count, dtype: float64
sns.distplot(data_user_buy4)
plt.show()
print('大多数用户的消费次数为:{}次'.format(data_user_buy4.mode()[0]))
大多数用户的消费次数为:1次

- 在同一时间段中,大多数用户消费次数为1次
4.3 复购情况分析
- 复购情况,即两天以上有购买行为,一天多次购买算一次
- 复购率=有复购行为的用户数/有购买行为的用户总数
#计算每个用户在多少个不同日期购买
data_rebuy=data_user[data_user.behavior_type=='4'].groupby('user_id')['date'].agg(['nunique'])
data_rebuy.head()
nunique
user_id
100001878 15
100011562 3
100012968 11
100014060 12
100024529 9
data_rebuy[data_rebuy['nunique']>=2].count()/data_rebuy.count()
print('复购率为:',round(data_rebuy[data_rebuy['nunique']>=2].count()/data_rebuy.count(),4))
复购率为: nunique 0.8717
dtype: float64
#所有复购时间间隔消费次数分布
# 计算不同的用户,不同的日期下的购买次数
data_day_buy=data_user[data_user.behavior_type=='4'].groupby('user_id').date.apply(lambda x:x.sort_values().diff(1).dropna())
data_day_buy5=data_day_buy.map(lambda x:x.days)
data_day_buy5
user_id
100001878 2439076 6
2439090 0
2440428 0
2660355 1
2672617 0
..
99989881 8203371 4
9248497 3
9249028 0
10601909 2
11085567 1
Name: date, Length: 111319, dtype: int64
data_day_buy5.describe()
count 111319.000000
mean 1.351692
std 2.934267
min 0.000000
25% 0.000000
50% 0.000000
75% 1.000000
max 30.000000
Name: date, dtype: float64
plt.figure(figsize=(16,9))
data_day_buy5.value_counts().plot(kind='bar')
plt.show()
sns.distplot(data_day_buy5.reset_index().groupby('user_id').date.mean())
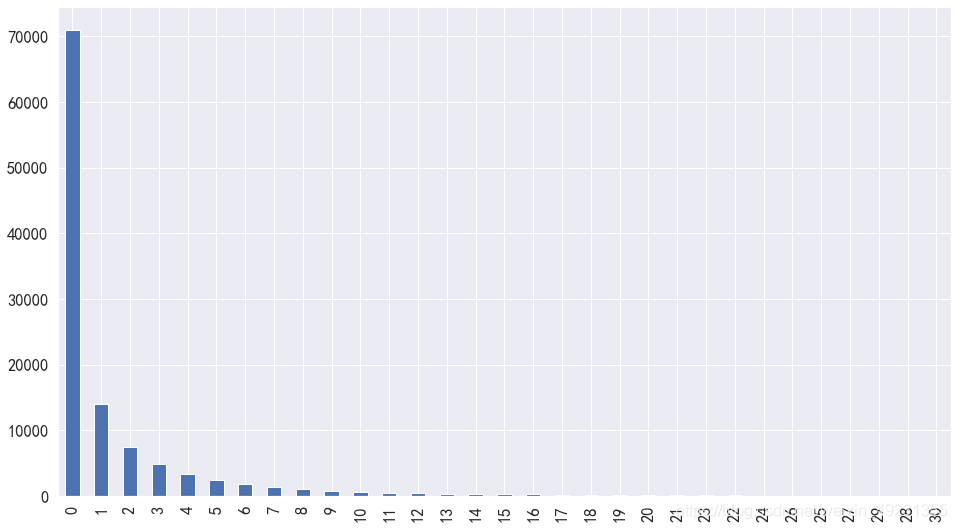
- 多数用户复购率为0.8717,消费次数随着消费时间间隔的增加而不断下降,在1-10天之内复购次数比较多,10天之后复购次数淘宝用户很少在进行复购,因此需要重视10天之内的淘宝用户复购行为,增加用户复购。
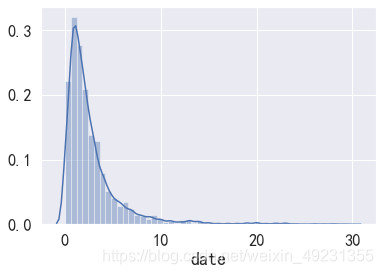
- 不同用户平均复购时间接近正态分布,但是总体来看,呈现逐渐下降趋势。多数淘宝用户平均复购时间集中在1-6天时间间隔内。
4.4 漏斗流失分析
data_user_count=data_user.groupby('behavior_type').size()
data_user_count
# 1是总点击量,2是总收藏量,3是总加入购物车量,4是总下单量
behavior_type
1 11550581
2 242556
3 343564
4 120205
dtype: int64
data_user.describe(include='all')
user_id item_id behavior_type user_geohash item_category time date hour operation
count 12256906 12256906 12256906 3922082 12256906 12256906 12256906 1.225691e+07 12256906.0
unique 10000 2876947 4 575458 8916 744 31 NaN NaN
top 36233277 112921337 1 94ek6ke 1863 2014-12-11 22:00:00 2014-12-12 00:00:00 NaN NaN
freq 31030 1445 11550581 1052 393247 54797 691712 NaN NaN
first NaN NaN NaN NaN NaN 2014-11-18 00:00:00 2014-11-18 00:00:00 NaN NaN
last NaN NaN NaN NaN NaN 2014-12-18 23:00:00 2014-12-18 00:00:00 NaN NaN
mean NaN NaN NaN NaN NaN NaN NaN 1.481799e+01 1.0
std NaN NaN NaN NaN NaN NaN NaN 6.474778e+00 0.0
min NaN NaN NaN NaN NaN NaN NaN 0.000000e+00 1.0
25% NaN NaN NaN NaN NaN NaN NaN 1.000000e+01 1.0
50% NaN NaN NaN NaN NaN NaN NaN 1.600000e+01 1.0
75% NaN NaN NaN NaN NaN NaN NaN 2.000000e+01 1.0
max NaN NaN NaN NaN NaN NaN NaN 2.300000e+01 1.0
#总浏览量
pv_all=data_user['behavior_type'].count()
print('总浏览量-点击量的流失率:{:.2%}'.format(((pv_all-data_user_count[0])/pv_all)))
总浏览量-点击量的流失率:5.76%
print('总点击量—总加入购物车的流失率:{:.2%}'.format(((data_user_count[0] - data_user_count[2])/data_user_count[0])))
总点击量—总加入购物车的流失率:97.03%
print('总加入购物车的量—总收藏量的流失率:{:.2%}'.format(((data_user_count[2] - data_user_count[1])/data_user_count[2])))
总加入购物车的量—总收藏量的流失率:29.40%
print('总收藏量—总购买量的流失率:{:.2%}'.format(((data_user_count[1] - data_user_count[3])/data_user_count[1])))
总收藏量—总购买量的流失率:50.44%
trace = go.Funnel(
y = ["点击", "加入购物车并收藏", "购买"],
x = [data_user_count[0],data_user_count[2]+data_user_count[1],data_user_count[3]],
textinfo = "value+percent initial",
marker=dict(color=["deepskyblue", "lightsalmon", "tan"]),
connector = {"line": {"color": "royalblue", "dash": "solid", "width": 3}})
data =[trace]
fig = go.Figure(data)
fig.show()
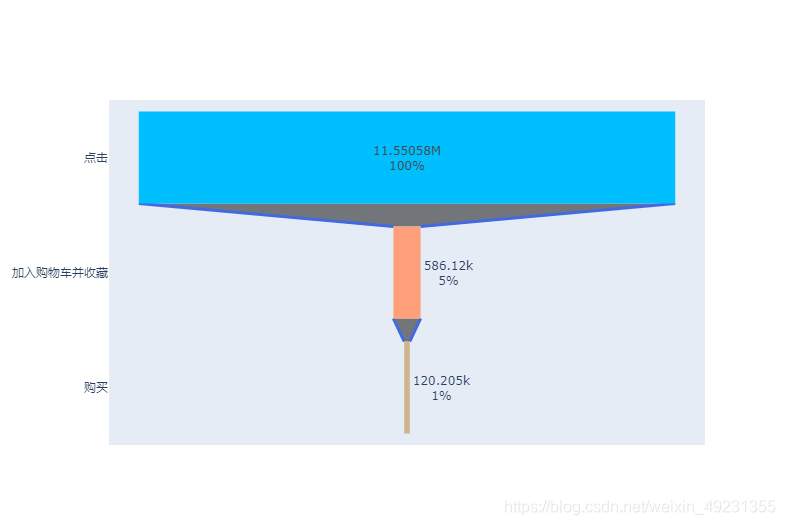
- 由于收藏和加入购车都是有购买意向的一种用户行为,切不分先后顺序,因此我们将其合并看作一个阶段。从上面的漏斗图和可以看出,从浏览到具有购买意向(收藏和加入购物车),只有5%的转化率,但是到了真正到购买的转化率只有1%,说明从浏览到进行收藏和加入购物车的阶段,是指标提升的重要环节。
4.5 用户价值度RFM模型分析
RFM的含义:
- R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
- M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
- 因为本数据集没有提供消费金额,因此只能R和F进行用户价值分析
from datetime import datetime
datenow=datetime(2014,12,18)
#每位用户最近购买时间
recent_buy_time=data_user[data_user['behavior_type']=='4'].groupby('user_id')['date'].apply(lambda x:datenow-x.sort_values().iloc[-1])
recent_buy_time=recent_buy_time.reset_index().rename(columns={'date':'recent'})
recent_buy_time.recent=recent_buy_time.recent.map(lambda x:x.days)
recent_buy_time.recent
0 0
1 2
2 0
3 0
4 2
..
8881 5
8882 11
8883 3
8884 4
8885 3
Name: recent, Length: 8886, dtype: int64
#每个用户的消费频次:
buy_freq=data_user[data_user.behavior_type=='4'].groupby('user_id').date.count().reset_index().rename(columns={'date':'freq'})
rfm=pd.merge(recent_buy_time,buy_freq,left_on='user_id',right_on='user_id',how='outer')
rfm['recent_value']=pd.qcut(rfm.recent,2,labels=['2','1'])
rfm['freq_value']=pd.qcut(rfm.freq,2,labels=['1','2'])
rfm['rfm']=rfm['recent_value'].str.cat(rfm['freq_value'])
rfm
user_id recent freq recent_value freq_value rfm
0 100001878 0 36 2 2 22
1 100011562 2 3 2 1 21
2 100012968 0 15 2 2 22
3 100014060 0 24 2 2 22
4 100024529 2 26 2 2 22
... ... ... ... ... ... ...
8881 99960313 5 8 1 1 11
8882 9996155 11 6 1 1 11
8883 99963140 3 19 2 2 22
8884 99968428 4 38 2 2 22
8885 99989881 3 17 2 2 22
8886 rows × 6 columns
def trans_value(x):
if x=='22':
return '重要价值客户'
elif x=='21':
return '重要发展客户'
elif x=='12':
return '重要挽留客户'
else:
return '流失客户'
rfm['用户等级']=rfm['rfm'].apply(trans_value)
rfm['用户等级'].value_counts()
重要价值客户 3179
流失客户 2767
重要发展客户 1721
重要挽留客户 1219
Name: 用户等级, dtype: int64
trace=[go.Pie(labels=rfm['用户等级'].value_counts().index,values=rfm['用户等级'].value_counts().values,\
hole=0.2,textfont=dict(size=12))]
fig=go.Figure(data=trace)
pyplot(fig)
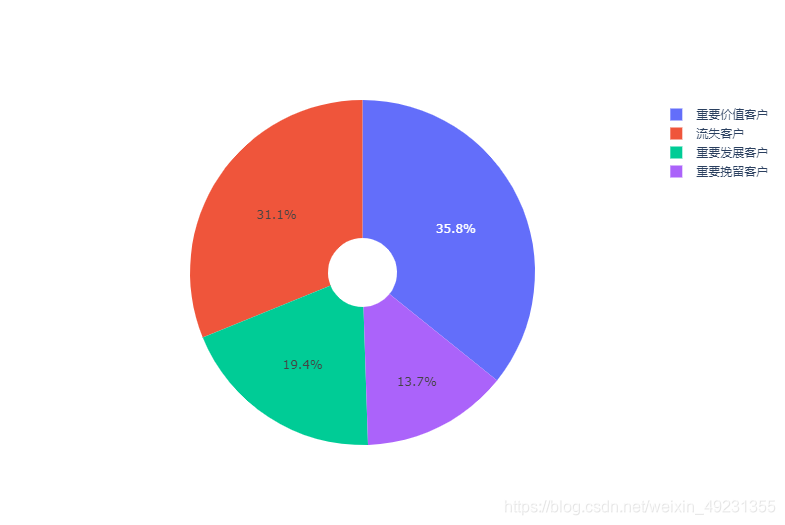
5. 结果解读
- 在上面每一次分析中,已经有了结论,这里不再重复描述
- 通过RF用户价值分析,对于22用户,为重点用户需要关注;对于21这类忠诚度高而购买能力不足的,可以适当给点折扣或捆绑销售来增加用户的购买频率。对于12这类忠诚度不高而购买能力强的,需要关注他们的购物习性做精准化营销。
版权声明:本文为weixin_49231355原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。