提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
这是我学习黑马程序员课程里面讲述的如何设计和编写mapreduce---求共同好友,我想为有需要的朋友提供我书写的源码。如果需要具体视频教学也可以看看老师是怎么将,课程链接:
黑马程序员大数据基础教程|史上最全面的Hadoop入门教程-day5-5-MapReduce案例-WordCount-主类代码编写-网易公开课
https://upos-sz-mirrorhw.bilivideo.com/upgcxcode/42/90/257089042/257089042-1-30080.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1642683756&gen=playurlv2&os=hwbv&oi=2028411111&trid=a4f447766d2649a3b31b7ae440468fdfu&platform=pc&upsig=a344e7dc7a94afa955c2b7014c2608b7&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=1615393173&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=15324&logo=80000000
https://upos-sz-mirrorkodo.bilivideo.com/upgcxcode/42/90/257089042/257089042-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1642683756&gen=playurlv2&os=kodobv&oi=2028411111&trid=a4f447766d2649a3b31b7ae440468fdfu&platform=pc&upsig=178b7e4b4f15750d07af857a0ac429be&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=1615393173&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=16402&logo=80000000
https://upos-sz-mirrorcos.bilivideo.com/upgcxcode/42/90/257089042/257089042-1-30032.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1642683756&gen=playurlv2&os=cosbv&oi=2028411111&trid=a4f447766d2649a3b31b7ae440468fdfu&platform=pc&upsig=155b75ac66bd6265ee6154396fa0290c&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=1615393173&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=10432&logo=80000000
https://upos-sz-mirrorcos.bilivideo.com/upgcxcode/42/90/257089042/257089042-1-30016.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1642683756&gen=playurlv2&os=cosbv&oi=2028411111&trid=a4f447766d2649a3b31b7ae440468fdfu&platform=pc&upsig=f1d0d04b1d5433d51ec38fa02006f5ce&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=1615393173&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=7020&logo=80000000
https://upos-sz-mirrorhw.bilivideo.com/upgcxcode/42/90/257089042/257089042-1-30280.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1642683756&gen=playurlv2&os=hwbv&oi=2028411111&trid=a4f447766d2649a3b31b7ae440468fdfu&platform=pc&upsig=05ccc6bb694ffea810b4b459abfb4ea2&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=1615393173&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=16640&logo=80000000
提示:以下是本篇文章正文内容,下面案例可供参考
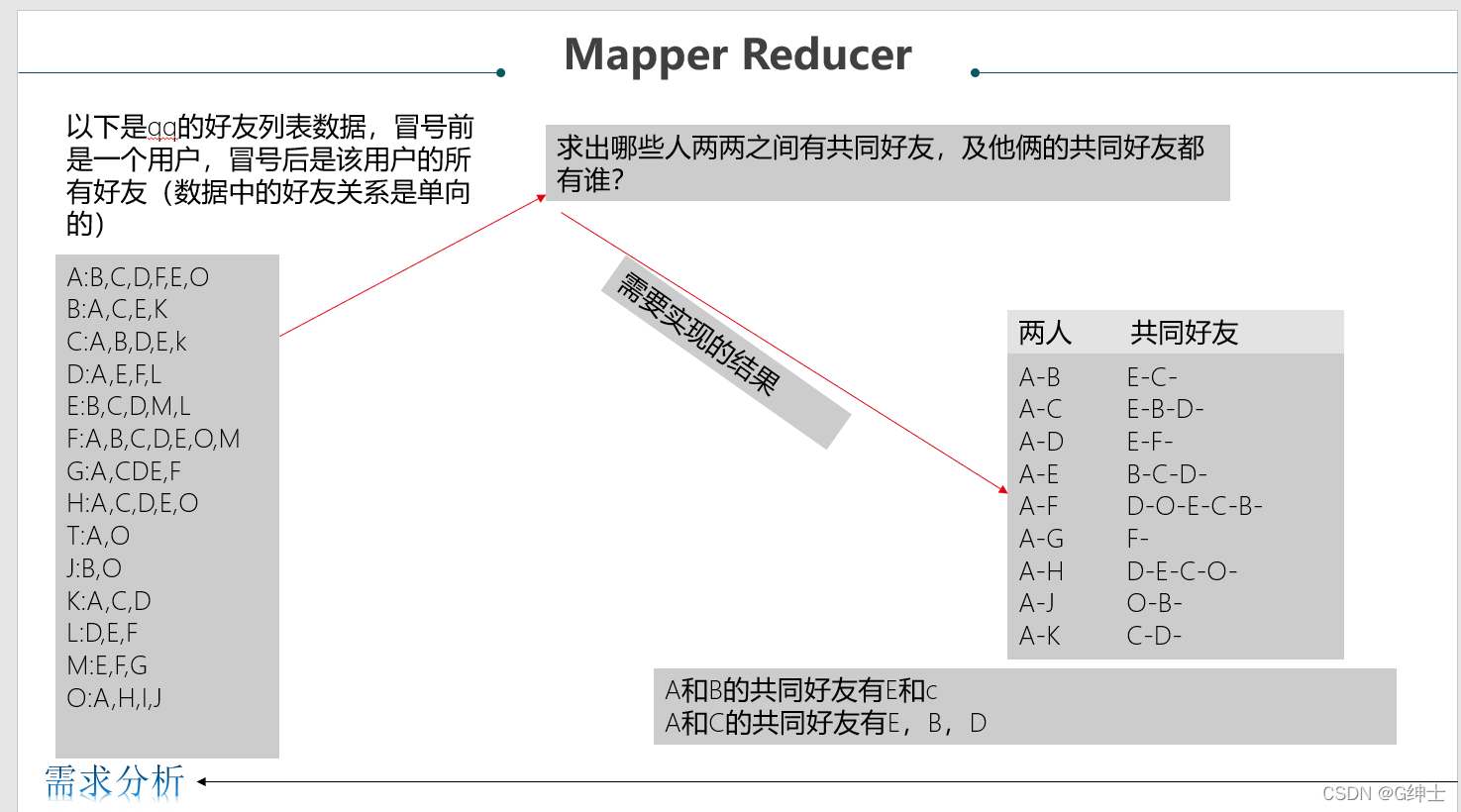
一、需求分析
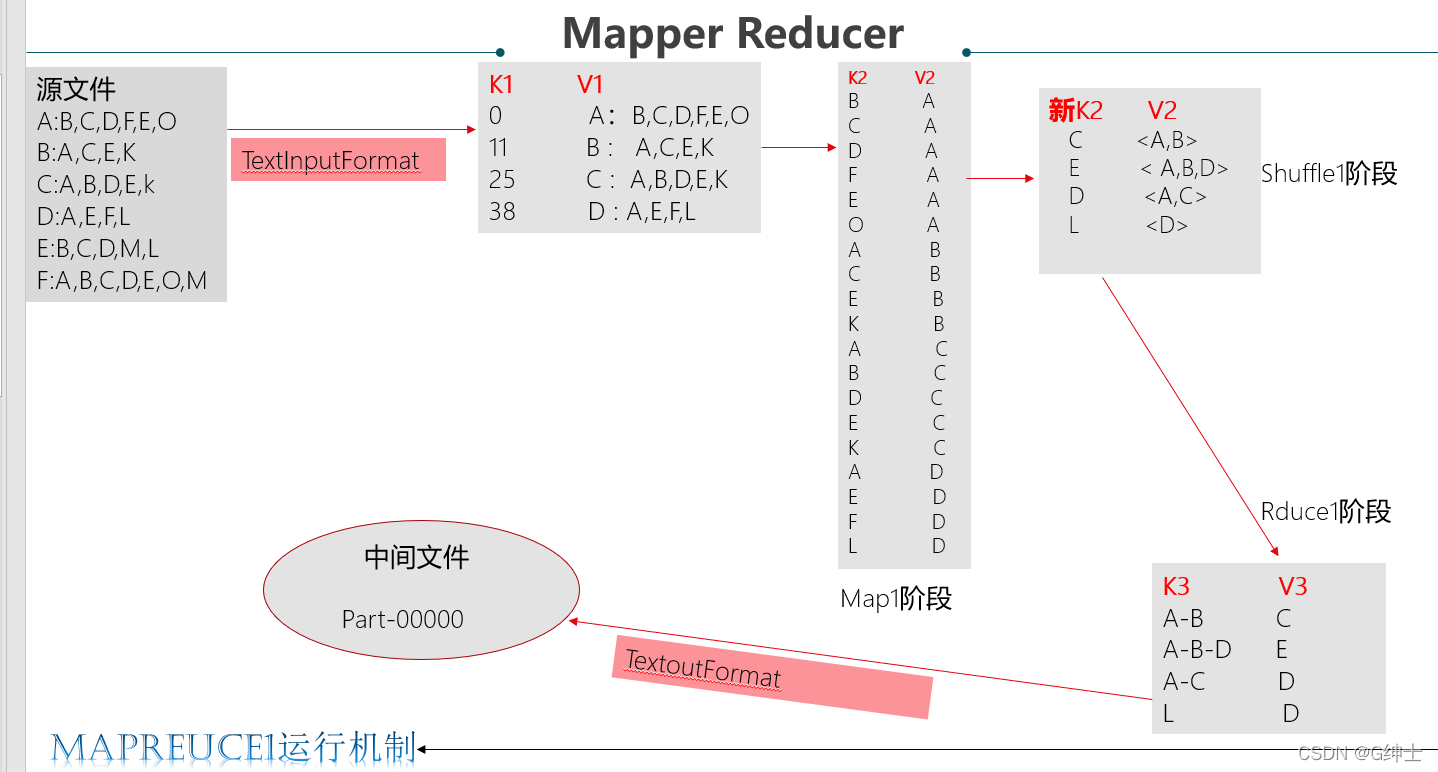
二,运行机制
mapreduce1
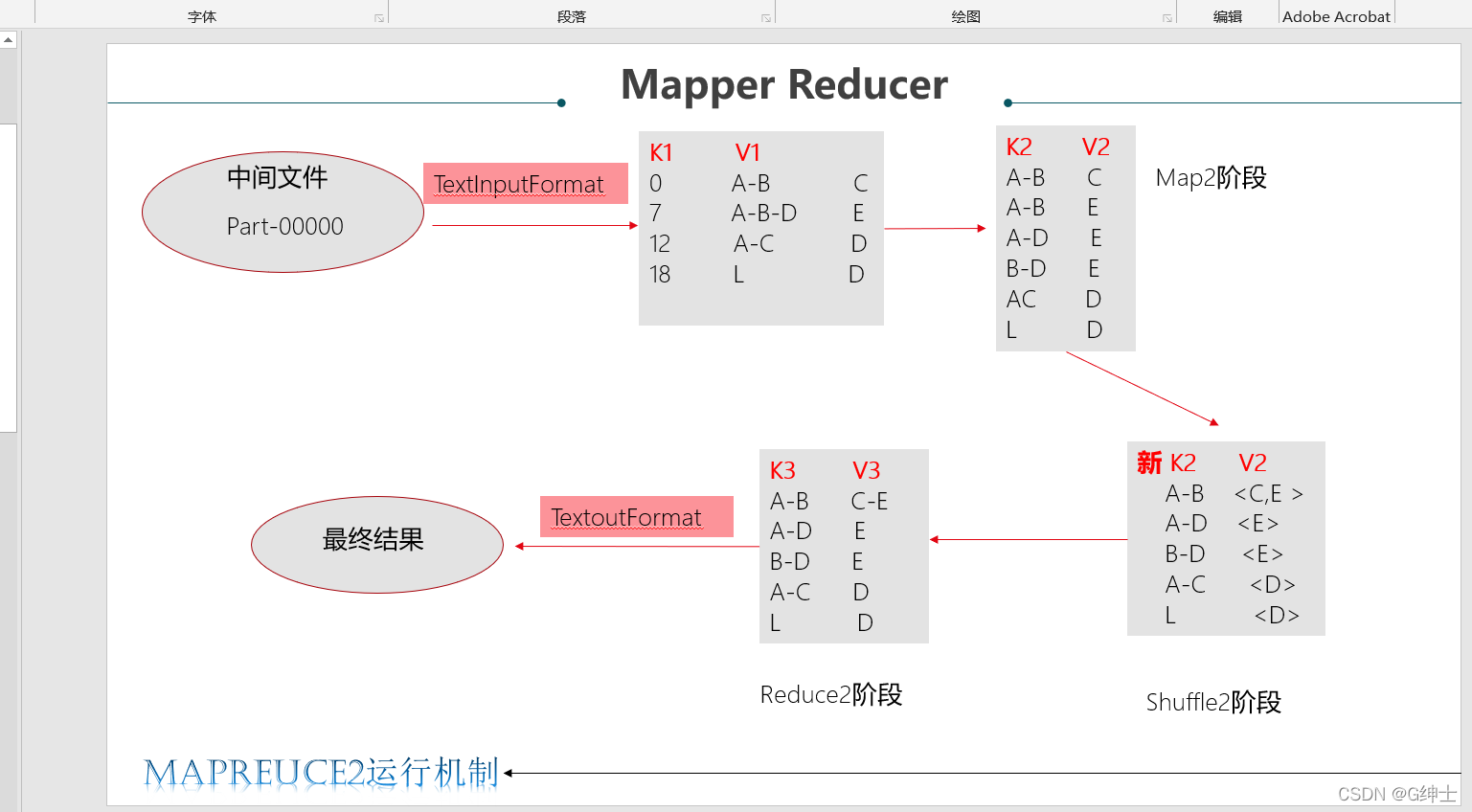
maprekduce2
三、源码
1.mapreduce1
代码如下(示例):
Step1Mapper
package cn.itcast.common_friends_step1;
import com.google.inject.internal.cglib.proxy.$MethodInterceptor;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//@time : 2021/12/15 19:00
//@Author : 高林映
//@File :Step1Mapper.java
//@Software : IntelliJ IDEA
public class Step1Mapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:以冒号拆分行文本数据: 冒号左边就是v2 就是好友
String[] split = value.toString().split(":");
String userStr = split[0];
//2:将冒号右边的字符串以逗号拆分,每个成员就是k2 好友列表里面的成员
String[] split1 = split[1].split(",");
for (String s : split1) {
//3:将k2 v2写入上下文中
context.write(new Text(s), new Text(userStr));
}
}
}
Step1Reducer
package cn.itcast.common_friends_step1;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
//@time : 2021/12/15 19:29
//@Author : 高林映
//@File :Step1Reducer.java
//@Software : IntelliJ IDEA
public class Step1Reducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:遍历集合,并将每个元素拼接,得到k3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//2:k2就是k3
//3:将k3和v3写入上下文中
context.write(new Text(buffer.toString()), key);
}
}
JobMain
package cn.itcast.common_friends_step1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.VLongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
//@time : 2021/12/14 17:46
//@Author : 高林映
//@File :JobMain.java
//@Software : IntelliJ IDEA
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception {
//1:获取job对象
Job job = Job.getInstance(super.getConf(), "common_friends_step1_job");
//2:设置job任务
//第一步:设置输入类和输出路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\input"));
//第二步:设置mapper类和数据类型
job.setMapperClass(Step1Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:设置reducer类和数据类型
job.setReducerClass(Step1Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:设置输出类和输出的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///output1"));
//3:等待job任务结束
boolean b1 = job.waitForCompletion(true);
return b1 ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
2.mapreduce2
代码如下(示例):
Step2Mapper
package cn.itcast.common_friends_step2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
//@time : 2021/12/15 21:13
//@Author : 高林映
//@File :Step2Mapper.java
//@Software : IntelliJ IDEA
public class Step2Mapper extends Mapper<LongWritable, Text, Text, Text> {
/*
k1 v1
0 F-A-J-C-E- B
---------------------------------
k2 v2
A-C B
A-E B
A-F B
A-J B
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:拆分行本数据,结果的第二部分可以得到v2
String[] split = value.toString().split("\t");
String friendStr = split[1];
//2:继续以‘-’为分隔符拆分行文本数据第一部分,得到数组
String[] userArray = split[0].split("-");
//3:对数组做一个排序
Arrays.sort(userArray); //Arrays.sort()函数是专门对数组进行解析的函数
//4:对数组中的元素进行两两组合,得到数组
/*
F-A-J-C-E -------- >A C E F J
A C E F J
A C E F J
*/
for (int i = 0; i < userArray.length - 1; i++) {
for (int j = i + 1; j < userArray.length; j++) {
//5:将k2和v2写入上下文中
context.write(new Text(userArray[i] + "-" + userArray[j]), new Text(friendStr));
}
}
}
}
Step2Reducer
package cn.itcast.common_friends_step2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//@time : 2021/12/15 22:10
//@Author : 高林映
//@File :Step2Reducer.java
//@Software : IntelliJ IDEA
public class Step2Reducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:原来的k2就是k3
//2:将集合进行遍历,将集合中的元素拼接,得到v3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//3:将k3和v3写入上下文中
context.write(key,new Text(buffer.toString()));
}
}
JobMain
package cn.itcast.common_friends_step2;
import cn.itcast.common_friends_step2.Step2Mapper;
import cn.itcast.common_friends_step2.Step2Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.VLongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
//@time : 2021/12/14 17:46
//@Author : 高林映
//@File :JobMain.java
//@Software : IntelliJ IDEA
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception {
//1:获取job对象
Job job = Job.getInstance(super.getConf(), "common_friends_step2_job");
//2:设置job任务
//第一步:设置输入类和输出路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\input1"));
//第二步:设置mapper类和数据类型
job.setMapperClass(Step2Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:设置reducer类和数据类型
job.setReducerClass(Step2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:设置输出类和输出的路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///output2"));
//3:等待job任务结束
boolean b1 = job.waitForCompletion(true);
return b1 ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new cn.itcast.common_friends_step2.JobMain(), args);
System.exit(run);
}
}
总结
需要具体ppt 和源码的可以到我的百度网盘里面下载;
链接: https://pan.baidu.com/s/1ojNm4XWYmvTp2YYKjjpG6A 提取码: wcxi