1、foreach操作:对RDD中的每个元素执行f函数操作,返回Unit。
def funOps1(): Unit = {
var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1.foreach(println _)
}源码:

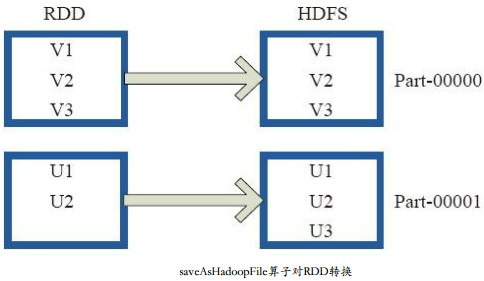
2、saveAsTextFile操作:将数据输出到hdfs上,将RDD中的每个元素映射转变为(Null, e.toString),然后将其写入HDFS。RDD的每个分区存储为HDFS中的一个Block。
def funOps2(): Unit = {
var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
var rdd2 = rdd1.map(_ + 1)
rdd2.saveAsTextFile("hdfs://xxx")
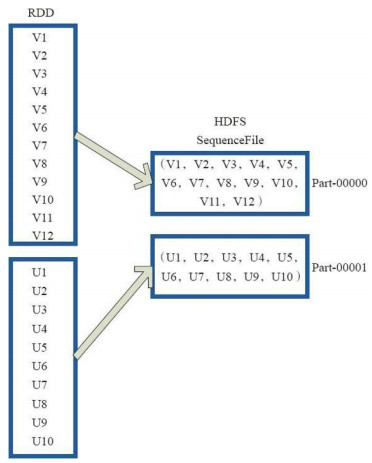
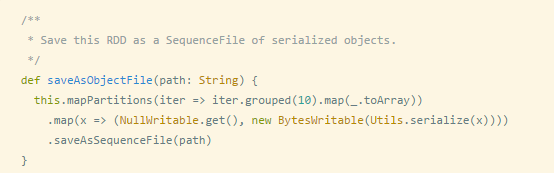
}3、saveAsObjectFile操作:saveAsObjectFile将分区中的每10个元素组成一个Array,然后将这个Array序列化,映射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
def funOps2(): Unit = {
var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
var rdd2 = rdd1.map(_ + 1)
rdd2.saveAsObjectFile("hdfs://xx")
// rdd2.saveAsTextFile("hdfs://xxx")
}源码:
4、collect操作:相当于toArray操作,将分布式的RDD转为一个数组返回到Driver程序所在的节点。
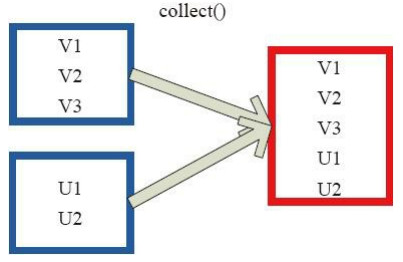
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[45] at parallelize at <console>:27
scala> rdd1.collect
res19: Array[Int] = Array(1, 2, 3, 5, 6) 5、collectAsMap操作:对(k,v)型的RDD数据转为一个单机的HashMap返回到Driver程序所在的节点。如果有重复的k,则后面的元素覆盖前面的。
源码:

6、reduceByKeyLocally操作:实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。
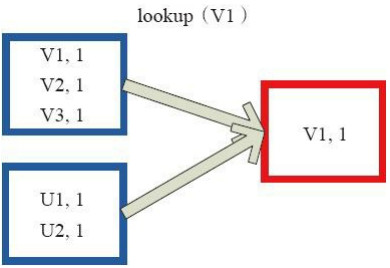
7、Lookup操作:对(K,V)型的RDD操作,返回指定K对应的元素形成的Seq。这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。
左侧方框代表RDD分区,右侧方框代表Seq,最后结果返回到Driver所在节点的应用中。
8、count操作:返回RDD中元素个数。
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at <console>:27
scala> rdd1.count
res23: Long = 5 9、top操作:返回RDD中最大的k个元素
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at <console>:27
scala> rdd1.top(2)
res24: Array[Int] = Array(6, 5) 10、take操作:返回RDD中最小的k个元素
scala> rdd1.take(2)
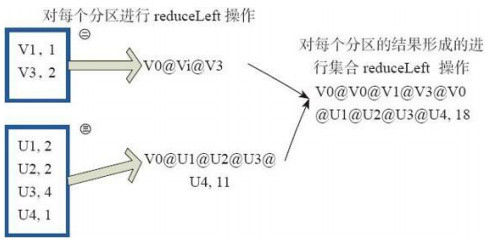
res25: Array[Int] = Array(1, 2)11、reduce操作:相当于对每个元素进行reduceLeft操作。
12、fold操作
13、aggregate操作:对每个分区的所有元素进行aggregate操作,再对分区的结果进行fold操作。aggregate采用归并的方式进行数据聚集,是并行化的。 而在fold和reduce函数的运算过程中,每个分区中需要进行串行处理,每个分区串行计算完结果,结果再按之前的方式进行聚集,并返回最终聚集结果。