一:窗口函数
1.1.窗口函数语法
over()用于指定分析函数工作时的数据窗口大小,这个数据窗口大小可能随着行的变化而变化。
窗口函数的基本语法:
<窗口函数> over(partition by <用于分组的列名>
order by <用于排序的列名>)
上述中窗口函数处可以放两类函数
1)专用窗口函数:包括dense_rank(),rank(),row_number()等专用窗口函数
2)聚合函数:例如sum(),avg(),max(),min(),count()。
【注意】:可以注意到专用窗口函数后面括号里是空的,什么也没有写,
但是聚合函数后面括号可不能为空,需要指定聚合的列名。
【注】:因为窗口函数是对where或者group by子句处理后的结果进行的操作,所以窗口函数
原则上只能写在select子句中。
1.2.思考一下窗口函数与我们之前学习的group by区别
1.group by 分组汇总会改变行数(默认返回每组中的第一行);
而partition by和rank()函数不会减少原表中的行数。

1.3窗口函数的功能
为什么叫做窗口函数呢?这是因为partition by分组以后的结果叫做窗口,这里的窗口是范围的意思。
1)窗口函数同时具有分组和排序的功能;
2)不减少原有表的行数
1.4窗口函数是聚合函数时
1)聚合函数作为窗口函数样例
select *,
sum(play_rate) over(order by user_id),
avg(play_rate) over(order by user_id),
max(play_rate) over(order by user_id),
min(play_rate) over(order by user_id),
count(play_rate) over(order by user_id)
from haokan_ads_test02;
2)我们返回的结果如下:

3)探究聚合函数作为窗口函数时其作用范围
以sum()为例,我们讲清楚以聚合函数作为窗口函数时,其作用范围。
聚合函数在窗口函数中,是对自身记录及位于自身记录以上的数据进行求和的结果。
比如user_id为4号,在使用sum窗口函数后的结果,是对1,2,3,4号的play_rate求和,
若是5号,则结果是1号~5号成绩的求和,以此类推。
4)总结
- 不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算
- [补充]:如果想看所有人的聚合情况(例如最大,最小,平均等),我们直接看输出结果的最后一行即可。
- 为什么要这样把聚合函数作为窗口函数呢?聚合函数作为窗口函数,可以在每一行的数据里直观地看到,
截止到本行数据化,统计数据(avg,max等)是多少,同时可以看出每一行数据对整体统计数据的影响。
1.5窗口函数总结
1)窗口函数中partition by子句可以省去,但此时就失去了分组的功能
2)窗口函数一般用于排名问题和topN问题
二:hive中日期函数
2.1常用的日期函数
| 序号 | 函数名称 | 返回类型 | 描述 |
| 1 | to_date(String timestamp) | string | 返回时间字符串日期部分 eg:to_date("1997-02-03 00:00:00") = "1997-01-01" |
| 2 | year(string date) | int | 返回时间字符串的年份部分 year("1998-02-02") = 1998 |
| 3 | quarter(date/timestamp/string) | int | 返回当前时间属性是哪个季度eg:1,2,3,4 |
| 4 | month(string date) | int | 返回时间字符串的月份部分 |
| 5 | day(string date) dayofmounth(date) | int | 返回时间字符串对应日期是该月份的第几天 day("1998-11-01") = 1 |
| 6 | hour(string date) | int | 返回字符串的小时 |
| 7 | minute(string date) | int | 返回字符串的分钟 |
| 8 | second(string date) | int | 返回字符串的秒 |
| 9 | weekofyear(string date) | int | 返回自然周:即返回时间字符串位于一年中的第几个周内 |
| 10 | datediff(string enddate,string startdate) | int | 计算enddate到startdate之间相差的天数 |
| 11 | date_add(string startdate,int days) | string | 从开始时间加上days. date_add('208-12-31',1)= '2009-01-01' |
| 12 | date_sub(string startdate,int days) | string | 从开始时间减去days |
| 13 | current_date | date | 返回当前时间日期 |
| 14 | current_timestamp | timestamp | 返回当前时间戳 |
| 15 | last_day() | string | 返回这个月最后一天的日期 |
| 16 | next_day(string start_date,string day_of_week) | string | 返回当前时间下一个星期x对应的日期 |
| 17 | date_format(date/timestamp/string ts, string fmt) | string | 按照指定格式返回时间date eg:date_format("2016-06-22", "MM-dd") = 06-22 |
| 记住几个最常用的,其余要学会去查 |
2.2 hive中时间数据对应的几种类型
hive中可以使用string, date, timestamp表示日期时间
1)String 用 yyyy-MM-dd 的形式表示,Date 用 yyyy-MM-dd 的形式表示,
Timestamp 用 yyyy-MM-dd hh:mm:ss 的形式表示
2)在用命令行插入值的时候,需要进行类型转换,
把String类型的字符串转化成相应的时间类型。转化的规则如下

3)在做join操作时候
如果时间信息中不包含时分秒,String 与 Date、Timestamp 表达的时间相同时是可以直接比较的,
但是Date和Timestamp之间却不能直接比较的。
如果想比较这两种时间类型,需要用cast函数做转换,
如:a_table join b_table on (a_table.timestamp_column = cast(b_table.date_column as timestamp));
2.3 获取当前时间以及时间格式转换
hive中的from_unixtime()函数,可以把时间戳格式的时间,转化为年月日时分秒格式的时间。
from_unixtime的参数要求为整数,且单位为秒。
如果从业务系统拿到的时间戳格式的时间单位为毫秒,则需要先将它转化为秒 。
unix_timestamp() 得到当前时间戳。
三:行转列和列转行函数
3.1 行列转换函数总览

3.2.列转行函数--explode()
有时也被称为表生成函数,其语法见下表

下面通过一个具体样例来解释explode()函数的用法及其意义。
1)首先创建一张表,写入数据,explode之后进行查询
--建表
create table t1 (id int,name string)
--插入数据
insert into t1 (id,name) values (1,'a,b,c'),(2,'d,e,f')
--执行
SELECT explode(split(t.name,',')) from t1 t2)查询结果如下:
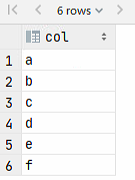
3)explode()函数作用分析
可以看到explode()函数的作用就是列转行,‘a,b,c’对应有三列,通过explode()函数炸开之后就变成三行了。
但是可以看到一个上述explode()函数有一个明显缺点,那就是炸开后的各行,与原表中关联列失去列关联。
在此例中也就是说我们不知道炸开后的a,b,c对应的id是谁了。如果想要把原始表中id和炸开后的a,b,c一一对应起来,
就需要用到lateral view函数了。
3.3 lateral view explode()
1)使用语句
继续使用3.2中的表和数据
SELECT id,colAliasName from t1 t
LATERAL VIEW explode(split(t.name,',')) tableAliasName as colAliasName其中tableAliasName是表的别名,随便起一个,colAliasName是列的别名,也是我们随便起。
(为什么要起别名?通过下面的原理可以知道,lateral view explode()会新生成一个表,
新生成的表和原表要做连接,所以要给表和列都要起别名)
2)查询结果
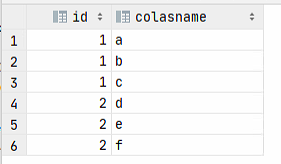
3)lateral view explode()使用分析
基本语法格式
select basetable.字段 , 炸开后的列别名 from basetable
lateral view explode(split(basetable.另外一个别名, ',')) 表别名 as 列别名
4)lateral view原理
原理是:通过lateral view UDTF(expression)函数把一行转换为多行,
会生成一个临时表,把这些数据放入这个临时表中(这就是为什么有表别名的原因),
然后使用这个临时表和base表做inner join 使用的条件就是原始表的关系
5)注意事项
当遇到该字符串为空时,如果在使用该函数,就会导致该条记录消失
这时,就要用到lateral view outer explode
四.条件函数
条件函数nvl() , case ... when ... then ... else... end , isnull()
| nvl(T value, T default_value) | Returns default value if value is null else returns value (as of HIve 0.11). 如果value值为NULL就返回default_value,否则返回value |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | When a = b, returns c; when a = d, returns e; else returns f. 如果a=b就返回c,a=d就返回e,否则返回f 如CASE 4 WHEN 5 THEN 5 WHEN 4 THEN 4 ELSE 3 END 将返回4
|
| isnull( a ) | Returns true if a is NULL and false otherwise. 如果a为null就返回true,否则返回false |
参考:
https://blog.csdn.net/qq_26803795/article/details/105141785#hive_138