建立向量
建立一个向量
a <- 5
b <- TRUE
c <- "Beijing"
在 R 语言中,TRUE和FASLE要全部大写,可以简写为T或F。
用c函数创建多个向量
a <- c(1, 2, 5, 3, 6, -2, 4)
b <- c("one", "two", "three")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
d <- c(1:10) # 或 d <- 1:10
x <- c()
最后一个建立了一个空向量,这样的好处是便于今后好加入新的值。
使用seq函数生成等差序列的向量
sep函数的原型如下:
# 默认的S3方法
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)),
length.out = NULL, along.with = NULL, ...)
seq.int(from, to, by, length.out, along.with, ...)
其中from是首项,默认为1;to是末项,默认为1;by是步长或等差增量,可以为负数,当没有指定to末项的时候,默认为1。
还有简单形式的两个函数:
seq_along(along.with)
seq_len(length.out)
length.out是向量的长度(length.out通常缩写为length或len);along.with用于指明该向量与另外一个向量的长度相同。
例子:
seq(from = 1, to = 10) # 从1输出到10
seq(from = 1, to = 10, by = 2) # 从1开始,步长为2,最大不超过10
seq(from = 1, to = 9, length = 5) # 从1开始,最大不超过9,输出5个,系统可以自动计算步长
s3 <- seq(from = 3, by = 3, length = 5)
>>> [1] 3 6 9 12 15
s4 <- seq(by = 3, along.with = s3) # 长度与s3一致
>>> [1] 1 4 7 10 13
如果只需要与s3有相同数据量,则可以使用
s4 <- seq_along(s3)
# 或者
seq(length.out = 5)
# 或者
seq_len(5)
>>> [1] 1 2 3 4 5
使用rep函数创建重复序列的向量
rep函数的原型如下:
rep(x, times = 1, length.out = NA, each = 1)
其中x为要重复的序列对象;times为重复的次数,默认为1;length.out 为产生的向量长度,默认为NA(未限制);each为每个元素重复的次数,默认为1。
例子:
rep(c(1:3), times = 2)
>>> [1] 1 2 3 1 2 3
rep(c(1:3), each = 2)
# 或者
rep(c(1:3), rep(2, 3))
>>> [1] 1 1 2 2 3 3
rep(c(2, 5), c(3, 4)) # 将向量c(2, 5)按照后面给出的次数向量依次重复3次和4次
>>> [1] 2 2 2 5 5 5 5
rep(c(2, 4, 6), times = 3, length.out = 5) # 这里规定了长度,所以只有5项
>>> [1] 2 4 6 2 4
给元素命名
使用names函数:
vn <- c(11, 22, 33, 44)
names(vn) <- c("one","two","three","four")
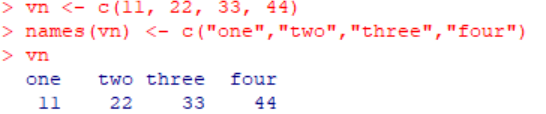
图一 给向量命名
索引元素
使用元素的位置索引
vc <- c(11, 22, 33, 44, 55, 66)
vc[1] # 提取第一个元素
vc[c(1:3)] # 提取第一个到第三个元素
vc[c(2, 4, 5)] # 提取第二、四、五个元素
vc[-1] # 提取除第一个元素之外的元素值
vc[-(1:3)] # 提取除第一个到第三个元素之外的元素值
vc[-c(2, 4, 5)] # 提取除第二、四、五个之外的元素值
注意:在 R 语言中,下标是从1开始的。而在 python 或 C 语言中,索引下标是从0开始的。
使用逻辑值索引
vc[c(TRUE, TRUE, FALSE, FALSE, TRUE, FALSE)] # 提取对应位置为TRUE的元素值
# 或者使用
x <- c(TRUE, TRUE, FALSE, FALSE, TRUE, FALSE)
vc[x]
>>> [1] 11 22 55
vc[c(TRUE, FALSE)] # 这里c(TRUE, FALSE)自动补齐到与vc向量长度相同
# 等价于
vc[c(TRUE, FALSE, TRUE, FALSE, TRUE, FALSE)]
>>> [1] 11 33 55
使用元素名字索引
首先我们先要给向量中的每个元素命名
vc <- c(11, 22, 33, 44, 55, 66)
names(vc) <- c("one", "two", "three", "four", "five", "six")
vc["one"] # 提取名称为 "one" 的元素
vc[c("one", "three", "six")]

图二 使用元素名字索引
使用which函数筛选数据
which函数的函数原型:
which(x, arr.ind = FALSE)
其中x为逻辑向量或数组。NA 值是允许的,并且可以省略(当作 FALSE 处理);arr.ind为逻辑值。当x是一个数组时,是否应该返回数组索引。
vc <- c(11, 22, 33, 44, 55, 66)
which(vc == 22) # 输出元素22的下标
>>> [1] 2
which.min(vc) # 找出最小元素所在的下标
which.max(vc) # 找出最大元素值所在的下标
which(vc == 11 | vc == 33)
which(vc > 11 & vc <= 44)
vc[vc > 20 & vc < 60]
# 等价的
vc[which(vc > 20 & vc < 60)]

图二 which函数的使用
注意:which函数输出的是元素值的位置,而不是元素值本身。
使用subset函数取子集
subset函数的函数原型:
subset(x, subset, ...)
# S3方法用于'matrix'或'data.frame'
subset(x, subset, select, drop = FALSE, ...)
其中x为需要提取的子集;subset指示要保留的元素或行的逻辑表达式:缺失的值被视为 FALSE;select为表达式,指示从 dataframe 中选择的列;drop传递给[索引操作符。
subset(vc, c(TRUE, FALSE, TRUE)) # 重复自动补齐
>>> [1] 11 33 44 66
subset(vc, vc > 11 & vc < 55)
>>> [1] 22 33 44

图三 subset函数的使用
用subset函数时,会自动忽略掉 NA 值,这是个很方便的去掉 NA值的特性。
修改元素
扩展向量
vc <- c(11, 22, 33, 44)
vc <- c(vc, c(55, 66))
>>> [1] 11 22 33 44 55 66
# 或者使用下面的形式
mc <- c(55, 66)
vc <- c(vc, mc)
还可以使用append函数。append函数的函数原型如下:
append(x, values, after = length(x))
其中x是要附加值的向量。values包含在修饰向量。after指示要插入的元素的下标位置,默认在末尾追加。
例子:
vc <- c(1:5)
mc <- c(0:1)
append(vc, mc, after = 3)
>>> [1] 1 2 3 0 1 4 5
修改元素的值
vc <- c(11, 22, 33, 44, 55, 66)
vc[1] <- 111 # 将第一个值改为111
vc[1:3] <- 111 # 第一个到第三个元素的值都变为111
vc[1:3] <- c(111, 222, 333)
>>> [1] 111 222 333 44 55 66
vc[vc > 33] <- 11 # 将所有元素值大于33的元素修改为11
vc[vc == 33] <- 11 # 将元素值为33的元素修改为11
删除元素
vc <- vc[-1]
>>> [1] 22 33 44 55 66
vc <- vc[-c(3:5)] # 删除下标为3, 4, 5的元素
# 或者
vc <- vc[c(2:4)]
排序向量
sort函数
sort函数原型如下:
sort(x, decreasing = FALSE, na.last = NA, index.return = TRUE)
其中x为要排序的对象;decreasing为排序顺序,默认为FALSE,即升序,TRUE为降序;na.last用于控制 NA 的处理。如果 TRUE,数据中缺少的值被放在最后;如果 FALSE,它们被放在第一位;如果不传参,则删除它们。index.return逻辑指示是否也应该返回排序索引向量。
例子:
vc <- c(10, NA, 9, 10, 8, 8, 13, 10, 10, 10, 12)
sort(vc) # 默认升序排序,NA 值不参与排序,且被剔除掉
>>> [1] 8 8 9 10 10 10 10 10 12 13
sort(vc, decreasing = TRUE) # 降序排序,NA值默认被剔除掉
sort(vc, na.last = TRUE) #默认升序排序,NA值不被剔除掉,且放在排序序列的后面
>>> [1] 8 8 9 10 10 10 10 10 12 13 NA
sort(vc,na.last = FALSE) # 默认升序排序,NA值不被剔除掉,且放在排序序列的前面
>>> [1] NA 8 8 9 10 10 10 10 10 12 13
sort(vc, index.return = TRUE) # 返回排序结果的位置索引值。即输出排序后的元素在原向量组的位置

图四 index.return参数的作用
order函数
order函数原型如下:
order(..., na.last = TRUE, decreasing = FALSE)
例子:
x <- c(34, 234, NA, 3, 1)
order(x)
>>> [1] 5 4 1 2 3
order函数与sort(x,index.return = TRUE)是类似的。
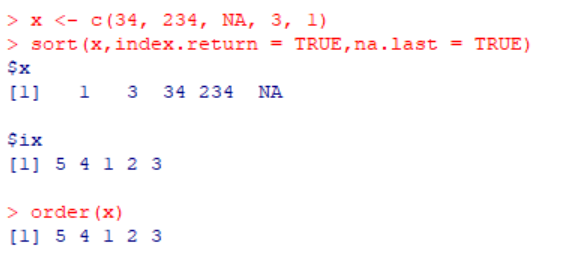
图六 order函数与sort函数的区别
类似的还有rank函数。
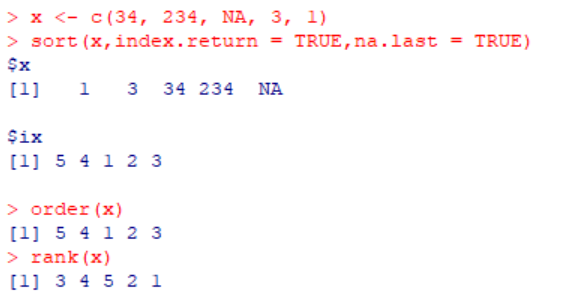
图七 rank函数与order函数、sort函数的区别
order函数与rank函数的区别:
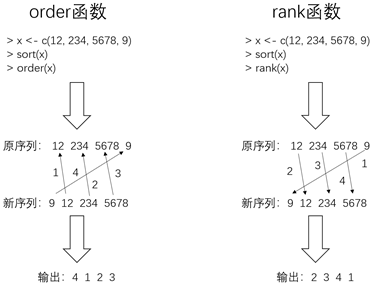
图八 order函数与rank函数的区别
rev函数
rev函数将向量倒序,即将原向量的元素按位置翻转。
vc <- c(11, 44, 33, 22, 77, 66)
rev(vc)
sort(vc,reductioning = TRUE) # 等价的
>>> [1] 66 77 22 33 44 11
类似地用法还可以用在降序排序中:
a <- c("e", "g", "a", "c")
rev(sort(a))
sort(a)先将序列排列成:"a","c","e","g"。然后rev(sort(a))把序列的顺序倒过来:"g","e","c","a"。
参考资料
《R语言实战》第二版
所有的使用帮助都可以使用help函数进行查询!