本文旨在罗列现有 Vitis AI 中文文档供学习记录之用,单击文档标题可直接跳转官网文档页面浏览学习:
Vitis AI 概述
Vitis™ AI 开发环境可在赛灵思硬件平台上加速 AI 推断,包括边缘器件和 Alveo™ 加速器卡。此环境由经过最优化的 IP 核、工具、库、模型和设计示例组成。其设计以高效和易用为核心,旨在通过赛灵思 FPGA 和自适应计算加速平台 (ACAP) 来充分发掘 AI 加速的全部潜能。Vitis AI 开发环境将底层 FPGA 和 ACAP 的繁复细节加以抽象化,从而帮助不具备 FPGA 知识的用户轻松开发深度学习推断应用。
编辑
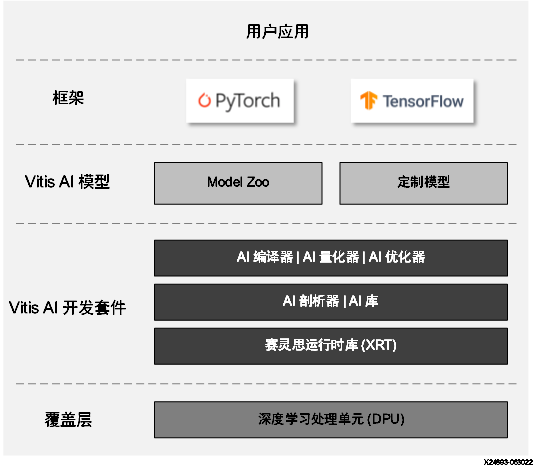
Vitis AI 栈
注释: 从 Vitis™ AI 2.5 起,已弃用 Caffe。如需了解有关 Caffe 的信息,请参阅《Vitis AI 2.0 用户指南》。
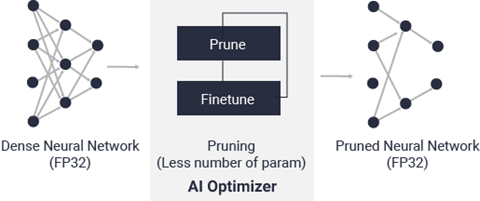
Vitis AI 优化器概述 Vitis™ AI 是赛灵思开发套件,用于在赛灵思硬件平台上进行 AI 推断。机器学习中的推断是计算密集型流程,需要大量存储器带宽以满足各种应用的低时延和高吞吐量要求。 Vitis AI 优化器支持对神经网络模型进行最优化。当前,Vitis AI 优化器仅包含一项工具,称为“pruner”(剪枝器)。Vitis AI 剪枝器用于对神经网络中的冗余内核进行剪枝,从而减少推断的总体计算成本。由 Vitis AI 剪枝器所生成的剪枝后的模型随后由 Vitis AI 量化器进行量化,然后部署到赛灵思 FPGA、SoC 或 ACAP 器件。如需了解有关 Vitis AI 量化器和部署的更多信息,请参阅 Vitis AI 用户指南(UG1414)。
编辑
VAI 优化器
Vitis AI 剪枝器支持 4 种深度学习框架。下表中列出了这些框架及其对应的工具名称(_p_ 表示剪枝):
框架 | 工具名称 |
|---|---|
TensorFlow | vai_p_tensorflow (TF1.15) 和 vai_p_tensorflow2 (TF2.x) |
PyTorch | vai_p_pytorch |
Vitis AI 优化器需商用许可证。请联系 xilinx_ai_optimizer@xilinx.com 以获取 Vitis AI 优化器安装包和许可证。
Vitis AI Library 用户指南 (UG1354)
相关库 以下 Vitis™ AI Library 与本文档有关。
编号 | 程序包名称 | 版本 |
|---|---|---|
1 | vitis_ai_library_r2.5.0_video.tar.gz | r2.5.0 |
2 | vitis_ai_library_r2.5.0_image.tar.gz | r2.5.0 |
3 | vitis-ai-runtime-2.5.0.tar.gz | r2.5.0 |
4 | vitis_ai_2022.1-r2.5.0.tar.gz | r2.5.0 |
6 | alveo_xclbin-2.5.0.tar.gz | r2.5.0 |
7 | sdk-2022.1.0.0.sh | 2022.1 |
目标受众 Vitis AI Library 的目标用户如下:
用户想要使用经过预训练的赛灵思模型来快速构建应用。
用户使用 Vitis AI Library 支持网络列表下其自有数据集来训练自有模型。
用户具有与 Vitis AI Library 支持的模型类似的自定义模型,并使用 Vitis AI 后处理库。
注释: 如果您拥有的自定义模型与 Vitis AI Library 所支持的模型截然不同,或者您有专业的后处理要求,则可使用 Vitis AI Library 实现作为参考。
文档导航 本文档描述了如何使用 Vitis AI Library 来安装、使用和开发应用。
引言 提供了有关 Vitis AI Library 的高层次综述。本章提供了有关 Vitis AI Library 整体、其框架、受支持的网络和受支持的硬件平台的清晰综述。
安装 描述了如何安装 Vitis AI Library 和运行示例。本章中的信息将有助于您快速设置主机和目标环境、编译并执行 Vitis AI Library 相关的示例。
库和样本 描述了 Vitis AI Library 支持的每个模型库。本章提供了有关 Vitis AI Library 支持的模型库、每个库的用途、如何使用图像和视频来进行库测试以及如何测试库性能的综述。
编程示例 描述了如何使用 Vitis AI Library 来开发应用。本章提供了下列综述:
使用 Vitis API 进行开发
使用模型进行开发
自定义预处理
使用配置文件作为预处理和后处理参数
在 Vitis AI Library 中使用后处理库
实现后处理代码
使用 xdputil 工具进行 dpu 和 xmodel 调试
自定义运算符的实现和寄存
应用演示 描述了如何设置测试环境和运行应用演示。Vitis AI Library 提供了 2 个应用演示。
API 编程 描述了如何查找编程 API。
性能 描述了不同开发板上的 Vitis AI Library 性能。
面向 Zynq UltraScale+ MPSoC 的 DPUCZDX8G 产品指南 (PG338)
引言 DPUCZDX8G 是专为 Zynq UltraScale+ MPSoC 设计的深度学习处理单元 (DPU)。它是专为卷积神经网络最优化的可配置计算引擎。引擎中所使用的并行度是一项设计参数,可根据目标器件和应用来选择。DPU 属于高层次微码计算引擎,其中具有经过最优化的高效指令集,并可支持推断大部分卷积神经网络。功能特性
支持通过 1 个 AXI 从接口来访问配置和状态寄存器。
支持通过 1 个 AXI 主接口执行指令提取。
支持每条通道单独配置。
IP 支持多种变体,可从逻辑资源利用率和并行度两方面进行缩放。配置包括:B512、B800、B1024、B1152、B1600、B2304、B3136 和 B4096,其中采用的命名法表示每个 DPU 时钟周期的 MAC 总数。
软件和 IP 核支持单个赛灵思 SoC 内最多包含 4 个同构 DPU 实例
以下列表高亮了 DPUCZDX8G 支持的关键运算符:
支持卷积和转置卷积
逐通道卷积和逐通道转置卷积
最大池化
平均池化
ReLU、ReLU6、Leaky ReLU、Hard Sigmoid 和 Hard Swish
逐元素求和与逐元素乘法
扩张
重组
完全连接的层
Softmax
串联、批量归一化
IP 相关信息
DPUCZDX8G IP 相关信息表 | |
|---|---|
核规格 | |
支持的器件系列 | Zynq® UltraScale+™ MPSoC 系列 |
支持的用户接口 | AXI 存储器映射接口: |
资源 | 请参阅 DPU 配置。 |
随核提供 | |
设计文件 | 加密 RTL |
设计示例 | Verilog |
约束文件 | 赛灵思设计约束 (XDC) |
支持的软件驱动程序 | 包含在 PetaLinux 中 |
测试激励文件 | 不提供 |
仿真模型 | 不提供 |
经过测试的设计流程 | |
设计输入 | Vivado® Design Suite 和 Vitis™ 统一软件平台 |
仿真 | 不适用 |
综合 | Vivado® 综合 |
赛灵思支持网页 | |
Linux 操作系统和驱动程序支持信息可从 DPUCZDX8G TRD 或 Vitis™ AI 开发套件获取。要了解受支持的工具版本,请参阅 Vivado Design Suite 用户指南:版本说明、安装和许可(UG973)。DPUCZDX8G 是由 Vitis AI 编译器生成的指令驱动的。目标神经网络 (NN)、DPUCZDX8G 硬件架构或 AXI 数据宽度发生更改时,必须通过更新 arch.json 文件来重新生成包含 DPUCZDX8G 指令的相关 .xmodel 文件。DPU 不支持 hw_emu 函数。原因如下:DPU 的 RTL 代码已加密。 Vitis™ 不对源代码进行分析。DPU 是协处理器,需要高度复杂的测试环境才能进行充分的设计验证。 |
Linux 操作系统和驱动程序支持信息可从 DPUCZDX8G TRD 或 Vitis™ AI 开发套件获取。
要了解受支持的工具版本,请参阅 Vivado Design Suite 用户指南:版本说明、安装和许可(UG973)。
DPUCZDX8G 是由 Vitis AI 编译器生成的指令驱动的。目标神经网络 (NN)、DPUCZDX8G 硬件架构或 AXI 数据宽度发生更改时,必须通过更新 arch.json 文件来重新生成包含 DPUCZDX8G 指令的相关 .xmodel 文件。
DPU 不支持 hw_emu 函数。原因如下:
DPU 的 RTL 代码已加密。 Vitis™ 不对源代码进行分析。
DPU 是协处理器,需要高度复杂的测试环境才能进行充分的设计验证。
(待续)