1 二分类
评价指标:准确率,精确率,召回率,F1-Score, AUC, ROC, P-R曲线
对于二分类问题,通常以关注的类为正类,其他类为负类,分类器在数据集上的预测或者正确或者不正确,我们有4中情况:
- TP:True Positive, 把正类预测为正类;
- FP:False Positive,把负类预测为正类;
- TN:True Negative, 把负类预测为负类;
- FN:False Negative,把正类预测为负类。
1.1 准确率(Accuracy)
1.2精确率(Precision)
精确率是指在预测为正类的样本中真正类所占的比例,公式为:
![]()
1.3 查全率/召回率 (Recall)
召回率是指在所有的正类中被预测为正类的比例,公式为:
![]()
不同的分类问题,对精确率和召回率的要求也不同。例如:假币预测,就需要很高的精确率,我需要你给我的预测数据具有很高的准确性。肿瘤预测就需要很高的召回率。“宁可错杀三千,不可放过一个”。要取决于具体问题。
1.4 F1-Score
精确率(P)和召回率(R)的调和平均。 即:
![]()
![]()
因为Precision和Recall是一对相互矛盾的量,当P高时,R往往相对较低,当R高时, P往往相对较低,所以为了更好的评价分类器的性能,一般使用F1-Score作为评价标准来衡量分类器的综合性能。
1.5 ROC曲线和AUC
- TPR:True Positive Rate,真正率, TPR代表能将正例分对的概率;
TPR=TP /(TP+FN)
- FPR:False Positive Rate, 假正率, FPR代表将负例错分为正例的概率。
FPR=FP /(FP+TN)
使用FPR作为横坐标,TPR作为纵坐标得到ROC曲线如下:
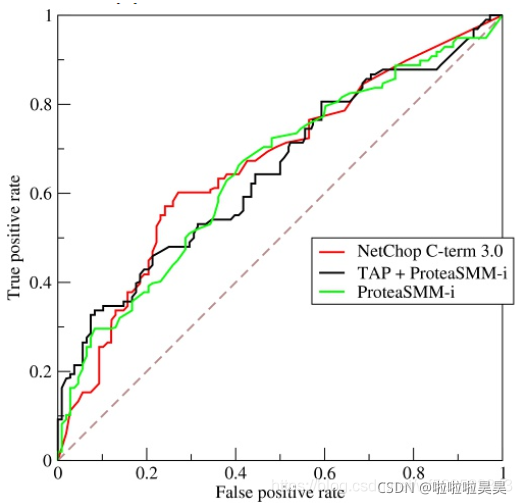
其中ROC曲线中的四个点和一条线代表的含义:
- (0,1):FN = 0, FP = 0, 表示所有样本都正确分类,这是一个完美的分类器;
- (1,0):TN = 0, TP = 0, 表示所有样本都分类错误,这是一个最糟糕的分类器;
- (0, 0):FP = 0, TP = 0, 表示所有样本都分类为负;
- (1,1):TN = 0, FN = 0, 表示左右样本都分类为正。
经过以上分析,ROC曲线越靠近左上角,该分类器的性能越好。
上图虚线与 y = x,该对角线实际上表示一个随机猜测的分类器的结果。
ROC曲线画法:在二分类问题中,我们最终得到的数据是对每一个样本估计其为正的概率值(Score),我们根据每个样本为正的概率大小从大到小排序,然后按照概率从高到低,一次将“Score”值作为阈值threshold,当测试样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,就可以得到一组FPR和TPR,即ROC曲线上的一点。利用Python画二分类和多分类ROC曲线。
AUC:(Area Under roc CurveROC)曲线下的面积,引入AUC的原因是量化评价指标。
AUC的面积越大,分类效果越好。AUC小于1,另一方面,正常的分类器你应该比随机猜测效果要好吧?所以 0.5 <= AUC <= 1。
AUC表征了分类器把正样本排在负样本前边的能力。这里的意思其实是指数据按照其为正的概率从大到小排序之后,正样本排在负样本前边的能力。AUC越大,就有越多的正样本排在负样本前边。极端来看,如果ROC的(0, 1)点,所有的正样本都排在负样本的前边。
1.6 ROC曲线 与 P-R曲线对比
ROC曲线特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
下图是ROC曲线和Precision-Recall曲线的对比:
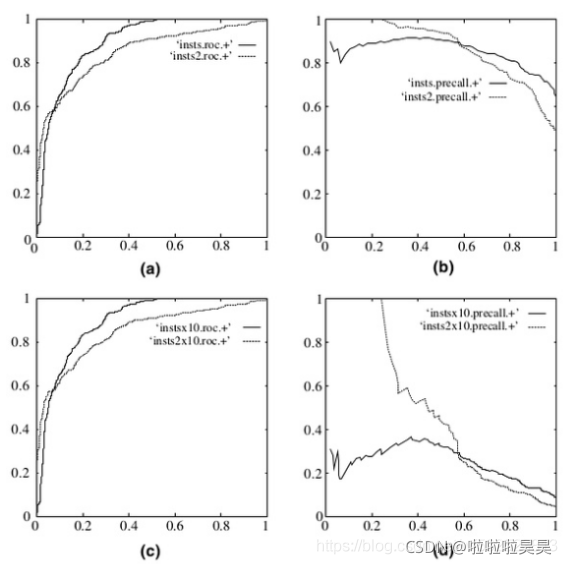
a,c为ROC曲线,b,d为P-R曲线;
a,b 为在原始测试集(balanced)上的结果,c,d为把原始数据集的负样本增加10倍后的结果。很明显,ROC曲线基本保持不变,P-R曲线变化较大。
为什么取AUC较好?因为一个二分类问题,如果你取P或R的话,那么你的评价结果和你阈值的选取关系很大,但是我这个一个分类器定了,我希望评价指标是和你取得阈值无关的,也就是需要做与阈值无关的处理。所以AUC较P-R好。
2 多分类
2.1 多分类转化为2vs2问题来评价
- 准确率:与二分类相同,预测正确的样本占总样本的比例。
- 精确率: ‘macro’, 对于每个标签,分别计算Precision,然后取不加权平均
- 查全率: ‘macro’,对于每个标签,分别计算Recall,然后取不加权平均
- F1-Score:‘macro’, 对于每个标签,分别计算发,然后取不加权平均
- ‘micro’, 将n个二分类评价的TP,FP,FN对应相加,计算P和R,然后求得F1
一般macro-f1和micro-f1都高的分类器性能好