TOP命令是我们经常用到的一个命令,得到的参数每一个的含义都是什么呢?最近梳理笔记,将这部分整理出来了,希望对你们有用~
目录
TOP
如下是一个top命令得到的截图,接下来会通过每一行参数来分析代表的含义。

L1:CPU信息
![]()
10:03:30 | 185days | users | load average |
当前系统时间 | 系统开机后运行时间 | 有几个user登录 | 3数字分别代表过去1分钟,5分钟,15分钟的负载情况。如果这个数字除以逻辑CPU数量高于5则说明CPU在超负荷运转 |
逻辑CPU个数:lscpu 里的cpu个数
物理CPU、物理核和逻辑核
物理CPU(即板子上插了多少个宏观的CPU芯片)、物理核(CPU中包含的物理内核个数)以及逻辑核(用SMT技术将物理核虚拟而成的逻辑处理单元)的判断依据:
在/proc/cpuinfo文件的条目中:
1.有多少个不同的physical id就有多少个物理CPU。
2.cpu cores记录了对应的物理CPU(以该条目中的physical id标识)有多少个物理核。
3.siblings记录了对应的物理CPU(以该条目中的physical id标识)有多少个逻辑核。
通过执行以下命令,可以得到物理CPU数目及各自包含多少个物理核:
cat /proc/cpuinfo | grep -E "physical id|cpu cores" | sed 'N;s/ / /' | sort | uniq
假设输出如下,则表示有两个物理CPU,各自包含4个物理核:
physical id : 0 cpu cores : 4
physical id : 1 cpu cores : 4
通过执行以下命令,可以得到物理CPU数目及各自包含多少个逻辑核
cat /proc/cpuinfo | grep "physical id" | sort | uniq -c
假设输出如下,则表示有两个物理CPU,各自包含8个逻辑核
8 physical id : 0
8 physical id : 1
L2:进程状态信息
![]()
total | running | sleeping | stopped | zombie |
总共任务进程数 | 运行中的任务进程数 | 休眠中的进程数 | 停止态的进程数 | 僵死态的任务进程数 |
休眠态:
可中断休眠:进程在等待事件完成 S
不可中断休眠:是数据从磁盘到内核装入过程,进程通常会等待IO的结束 D
僵死态:以下文章有说明
停止态:暂停内存中,但是不会被调度,除非手动启动
linux内核中状态分类:
孤儿和僵死状态区别?
- R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列 里。
- S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptible sleep))。
- D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的 进程通常会等待IO的结束。
- T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可 以通过发送 SIGCONT 信号让进程继续运行。
- X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
- Z僵死状态(zombie):在Linux中,正常情况下,子进程是通过父进程创建的,子进程再创建新的子进程。但是子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束。当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。当进程退出但是父进程并没有调用wait或waitpid获取子进程的状态信息时就会产生僵尸进程。当一个子进程结束运行(一般是调用exit、运行时发生致命错误或收到终止信号所导致)时,子进程的退出状态(返回值)会回报给操作系统,系统则以SIGCHLD信号将子进程被结束的事件告知父进程,此时子进程的进程控制块(PCB)仍驻留在内存中。一般来说,收到SIGCHLD后,父进程会使用wait系统调用以获取子进程的退出状态,然后内核就可以从内存中释放已结束的子进程的PCB;而如若父进程没有这么做的话,子进程的PCB就会一直驻留在内存中,也即成为僵尸进程
- 孤儿进程则是指当一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。孤儿进程由于有init进程循环的wait()回收资源,因此并没有什么危害
L3:CPU状态信息
![]()
us | sy | ni(nice) | id | si | wa | st | hi | |
user空间占CPU百分比 | 内核空间占CPU百分比 | 改变优先级的进程占CPU百分比 | 空闲CPU百分比 | 软中断 | IO等待占用CPU百分比 | 系统花了百分之多少等待得到真正的cpu资源 | 硬中断 |
软中断:在 Linux 系统里,我们可以通过查看/proc/softirqs 的 内容来知晓「软中断」的运行情况,以及 /proc/interrupts 的 内容来知晓「硬中断」的运行情况
中断:
软中断可看这篇文章 【系统】什么是中断?如何处理软中断过多?_带你去吃小豆花的博客-CSDN博客
hi硬中断:键盘外部输入产生的中断
L4:内存状态信息
![]()
total | free | buff/cache | used |
物理内存总量 | 空闲内存总量 | 用作内核缓存的内存量 | 使用的物理内存总量 |
L5:swap交换分区信息
![]()
什么是swap?
当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。
另外,当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
这种,将内存数据换出磁盘,又从磁盘中恢复数据到内存的过程,就是 Swap 机制负责的。
Swap 就是把一块磁盘空间或者本地文件,当成内存来使用,它包含换出和换入两个过程:
- 换出(Swap Out) ,是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存;
- 换入(Swap In),是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来;
为何用swap?swap能给我们带来什么好处?
使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。
查看系统中swap in/out的情况
并不是swap空间占用多就一定性能下降,真正影响性能是swap in和out的频率,频率越高,对系统的性能影响越大,我们可以通过 vmstat 命令来查看 swap in/out 的频率
#参数2表示每两秒统计一次,si和so两列就是每秒swap in和out的次数
dev@ubuntu:~$ vmstat 2
procs------------memory--------------swap----io-----system-----------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 70232 75620 7940 209476 0 0 0 0 111 180 0 1 99 0 0
0 0 70232 75620 7940 209476 0 0 0 0 116 186 1 1 99swap如何启用?
Linux 提供了两种不同的方法启用 Swap,分别是 Swap 分区(Swap Partition)和 Swap 文件(Swapfile),开启方法可以看这个资料 (opens new window):
- Swap 分区是硬盘上的独立区域,该区域只会用于交换分区,其他的文件不能存储在该区域上,我们可以使用
Swapon -s 命令查看当前系统上的交换分区;
- Swap 文件是文件系统中的特殊文件,它与文件系统中的其他文件也没有太多的区别;
swap开启方法:
场景一:使用块设备创建swap (创建新分区,将新分区创建为swap,激活swap,查询swap分区UUID,实现swap开机自动挂载,将挂载信息写入/etc/fstab,挂载swap)
- 执行以下命令,新建一个分区(以2G为例)。
# fdisk /dev/vdb
回显信息如下:
Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): Using default response p Partition number (1-4, default 1): First sector (2048-20971519, default 2048): Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-20971519, default 20971519): +2G Partition 1 of type Linux and of size 2 GiB is set
Command (m for help): p Disk /dev/vdb: 10.7 GB, 10737418240 bytes, 20971520 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x1f02f438 Device Boot Start End Blocks Id System /dev/vdb1 2048 4196351 2097152 83 Linux Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.
- 执行以下命令,将新建的分区创建为swap。
# mkswap /dev/vdb1
- 执行以下命令,激活swap分区。
# swapon /dev/vdb1
- 执行以下命令,查询已启动的swap。
# swapon -s
- 执行以下命令,查询swap分区UUID。
# blkid |grep swap |awk '{print $2}'
UUID="1ee90e3c-1538-453b-9240-ad430f835f6f"
- 执行以下命令,实现swap开机自动挂载,将挂载信息写入/etc/fstab。
swap的UUID从步骤4.执行以下命令,查询swap分区UUID。获取。本例中执行命令如下。
# echo "UUID=1ee90e3c-1538-453b-9240-ad430f835f6f swap swap defaults 0 0" >>/etc/fstab
- 执行以下命令,挂载swap。
# mount -a
场景二:使用文件模拟的块设备做swap分区(创建swap文件,更改文件为swap,启用swap,实现开机自动挂载,将swap文件挂载写入/etc/fstab。)
说明:
使用文件模拟的块设备做swap性能较之直接使用块设备性能较差。
- 执行以下命令,创建1G的swap文件。
# dd if=/dev/zero of=/swapfile bs=1M count=1000
- 执行以下命令,更改文件为swap。
# chmod 600 /swapfile
- 执行以下命令,更改文件属性为swap。
# mkswap /swapfile
- 执行以下命令,启用swap。
# swapon /swapfile
- 执行以下命令,实现swap开机自动挂载,将swap文件挂载写入/etc/fstab。
# echo "/swapfile swap swap defaults 0 0" >>/etc/fstab
- 执行以下命令,挂载swap。
# mount -a
扩展:申请的物理内存超过物理内存会怎样?
- 在 32 位操作系统,因为进程最大只能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
- 在 64位 位操作系统,因为进程最大只能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
- 如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
- 如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
- 内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
swap缺点?
频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
swap回收的是什么?
Linux 的 Swap 机制回收的是匿名页,像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
L6:共享内存等其他信息
![]()
PID | USER | PR | NI | VIRT | RES | SHR | S | %CPU | %MEM | TIME+ |
进程id | 进程所有者 | 进程优先级 | nice值,越小优先级越高 | 进程使用的虚拟内存总量 | 进程使用的、未被换出的物理内存大小,单位kb | 共享内存大小,单位kb | 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程) | 上次更新到现在的CPU时间占用百分比 | 进程使用的物理内存百分比 | 进程使用的CPU时间总计,单位1/100秒 |
NI VS PR:
NI 是代表 nice 的意思,是一个进程用户态的一个概念;PR 代表 priority 优先级,是进程的实际优先级,是进程内核态的一个概念
虚拟内存vs物理内存vs共享内存vs缓存
虚拟内存
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
为何要有虚拟内存?虚拟内存作用?
在多进程环境下,使得进程之间的内存地址不受影响,相互隔离,于是操作系统就为每个进程独立分配一套虚拟地址空间,每个程序只关心自己的虚拟地址就可以,实际上大家的虚拟地址都是一样的,但分布到物理地址内存是不一样的。作为程序,也不用关心物理地址的事情
虚拟内存可否无限大?
每个进程都有自己的虚拟空间,而物理内存只有一个,所以当启用了大量的进程,物理内存必然会很紧张,于是操作系统会通过内存交换技术,把不常使用的内存暂时存放到硬盘(换出),在需要的时候再装载回物理内存(换入)
- 在 32 位操作系统,因为进程最大只能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
- 在 64位 位操作系统,因为进程最大只能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
- 如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
- 如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
虚拟内存和物理内存关系?
操作系统引入了虚拟内存,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存
虚拟内存代价?
1.虚存的管理需要建立很多数据结构,这些数据结构要占用额外的内存
2.虚拟地址到物理地址的转换,增加了指令的执行时间。
3.页面的换入换出需要磁盘I/O,这是很耗时的
4.如果一页中只有一部分数据,会浪费内存。
缓存是什么?
最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
cache vs buffer
cache 是cpu与内存间的,buffer是内存与磁盘间的,都是为了解决速度不对等问题
在内存压力较大的情况下,当然有必要清空释放cache,作为free空间分给相关进程使用。所以一般情况下,我们认为buffer/cache空间可以被释放,这个理解是正确的。
使用free -m 命令 查看一下内存的使用情况,这里简单介绍一下这个命令的返回
total:内存总数used:已经使用的内存数free:空闲的内存数shared:多个进程共享的内存总额buff/cache:磁盘缓存的大小
一般情况下两个缓存系统是一起配合使用的,比如当我们对一个文件进行写操作的时候,page cache的内容会被改变,而buffer cache则可以用来将page标记为不同的缓冲区,并记录是哪一个缓冲区被修改了。这样,内核在后续执行脏数据的回写(writeback)时,就不用将整个page写回,而只需要写回修改的部分即可。在内存不够时,可以清缓存来释放内存,这种清缓存的工作也并不是没有成本。所以伴随着cache清除的行为的,一般都是系统IO飙高。因为内核要对比cache中的数据和对应硬盘文件上的数据是否一致,如果不一致需要写回,之后才能回收
怎样释放Buff/cache呢?
通过proc下的一个文件,proc下的文件相当于与内核通信的一个媒介,也就是说可以通过修改/proc中的文件,来对当前kernel的行为做出调整.那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
物理内存
实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)
共享内存
一般来说,对于内存管理,采用的是虚拟内存技术,也就是每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存映射到不同的物理内存中。所以,即使进程 A 和 进程 B 的虚拟地址是一样的,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度
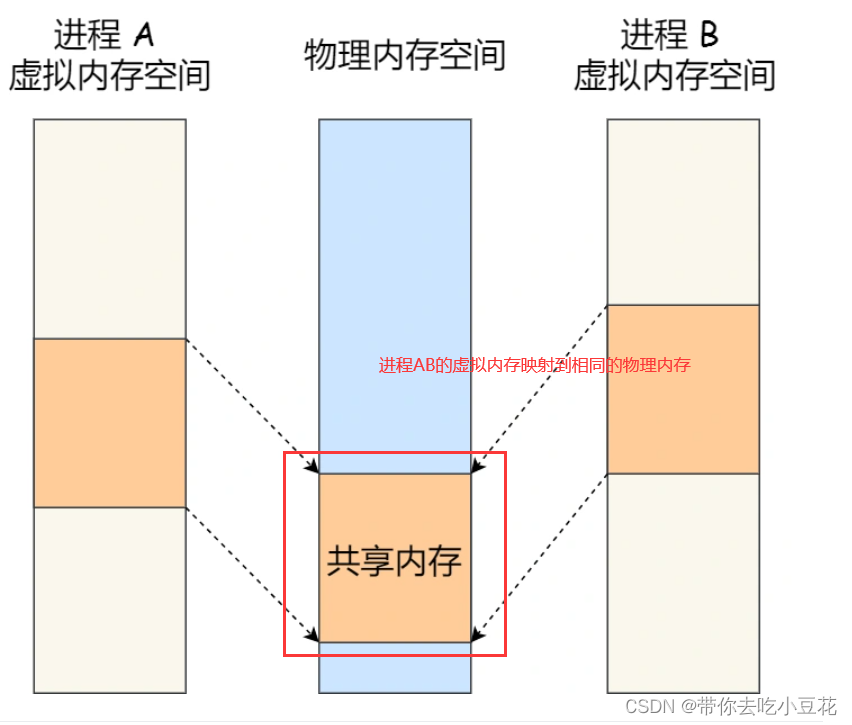
共享内存也是进程间通信的一种方式
扩展:进程间通信的其他方式还有:
管道、消息队列、共享内存、信号量、信号、socket
进程是位于用户空间的,彼此间独立,不可以互相访问,进程间的通信就需要借助内核来实现,linux内核提供不少的进程间通信方式,其中最简单的是管道方式,管道方式又可以分为匿名管道和命名管道。
匿名管道:比如shell命令的 | 就是匿名管道,其特点是通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失
命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
socket通信:可以用于不同主机间,也可以用于同一个主机间,前面说到的通信机制,都是工作于同一台主机。可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。RPC:远程过程调用。是基于socket通信。
RES | SHR | S | %CPU | %MEM | TIME+ |
进程使用的,未被换出的物理内存大小 | 共享内存大小 | 进程状态,有S,T,R,Z,D | 上次更新到现在的CPU时间占用百分比 | 进程使用的物理内存百分比 | 进程使用的CPU时间总计,单位1/100s |
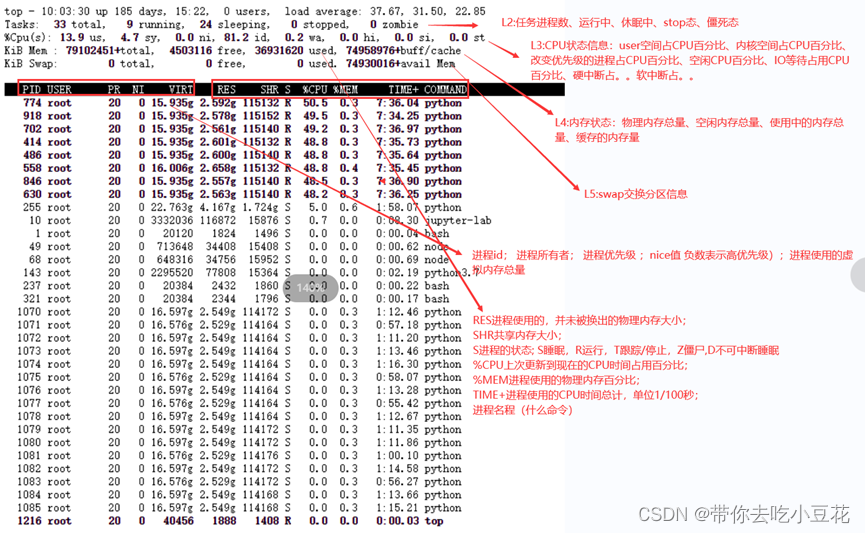
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下。所有运行态进行被加亮
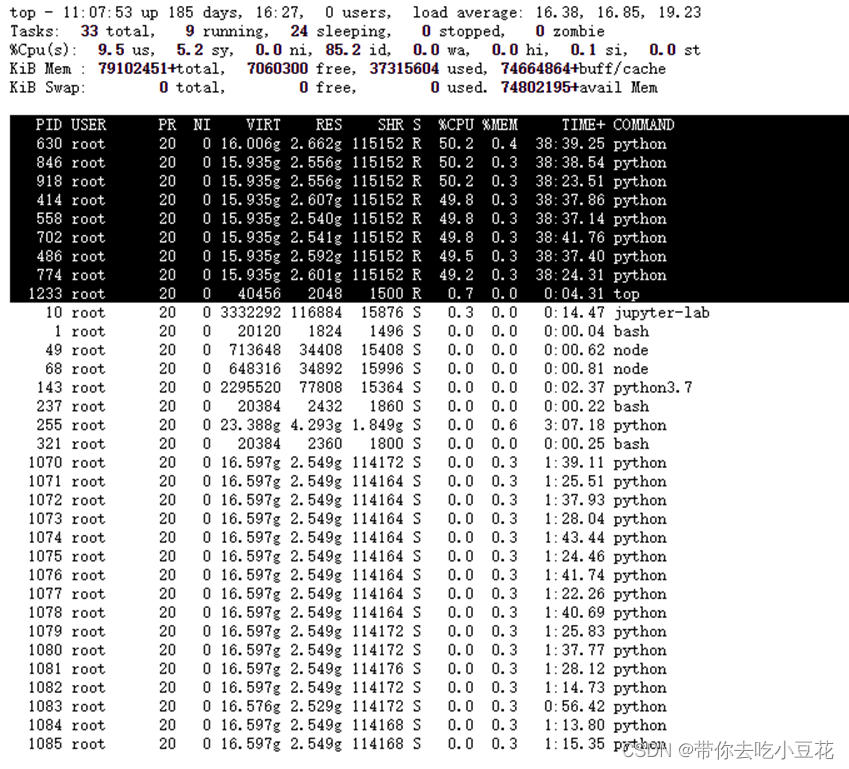
TOP交互式命令
1 键 可以监控每个逻辑CPU的状况
b 键(打开关闭加亮效果)
M 按照列 %MEM 排序
N 按照列 PID 排序
P 按照列 %CPU 排序
T 按照列 TIME+ 排序
R 在正序与逆序间切换(Reverse)