1、线程池是什么?
线程池是一种基于池化思想管理线程的工具。
2、使用多个单线程会有什么影响?线程池可以帮到什么忙?
如果线程过多,会带来额外的开销,比如创建销毁线程的开销、调度线程的开销,最终就会降低计算机的整体性能。
线程池可以管理维护多个线程,分配并发执行的任务,这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度的开销,保证了对内核的充分利用。

计算机
3、线程池的好处
(1)降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损失。
(2)提高响应速度:任务到达时,无需等待线程创建即可立即执行。
(3)提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
(4)提供更强大的功能:线程池具有可拓展性,允许开发人员向其中增加更多的功能。比如添加一个延时定时线程池ScheduledThreadPoolExecutor,就可以实现任务延期执行或定期执行的功能。
4、线程池核心设计与实现
Java线程池的核心实现类是ThreadPoolExecutor,我们以JDK1.8的源码来分析Java线程池的核心设计与实现。
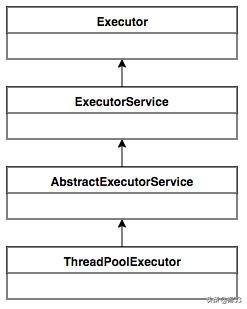
ThreadPoolExecutor的继承关系-UML类图
4.1、ThreadPoolExecutor的UML类图解释:
(1)Executor接口:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需继承Runnable接口,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
(2)ExecutorService接口:增加了一些能力,比如扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;提供了管控线程池的方法,比如停止线程池的运行。
(3)AbstractExecutorService抽象类:上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
(4)ThreadPoolExecutor实现类:最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
代码举例:
线程池
import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.ExecutorService;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;/** * 线程池类 */public class ThreadPool { //线程池维护线程的最少数量 private static final int CORE_POOL_SIZE = 30;//线程池维护线程的最大数量 private static final int MAX_POOL_SIZE = 100;//线程池维护线程所允许的空闲时间 private static final int KEEP_ALIVE_TIME = 10;//线程阻塞队列中允许的最大待执行线程数 private static final int BLOCKING_QUEUE_SIZE = 10000; private static Object obj;/** * 线程池的构造函数参数设置 */ private static ExecutorService logServer = new ThreadPoolExecutor( CORE_POOL_SIZE, MAX_POOL_SIZE, KEEP_ALIVE_TIME, TimeUnit.MINUTES, new ArrayBlockingQueue(BLOCKING_QUEUE_SIZE), new ThreadPoolExecutor.DiscardOldestPolicy()); /** * 在线程池中运行任务类 * @param runnable */public static void logExecute(Runnable runnable) { if (logServer == null) { synchronized (obj) { logServer = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE, KEEP_ALIVE_TIME, TimeUnit.MINUTES, new ArrayBlockingQueue(BLOCKING_QUEUE_SIZE), new ThreadPoolExecutor.DiscardOldestPolicy()); } } //提交任务 logServer.execute(runnable); }}任务类继承Runnable接口
/*** 任务类*/public class DemoThread implements Runnable { @Overridepublic void run() { //具体业务实现 ...... }}将任务类提交到线程池中
......ThreadPool.logExecute(new DemoThread());......4.2、ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的呢?其运行机制如下图所示:
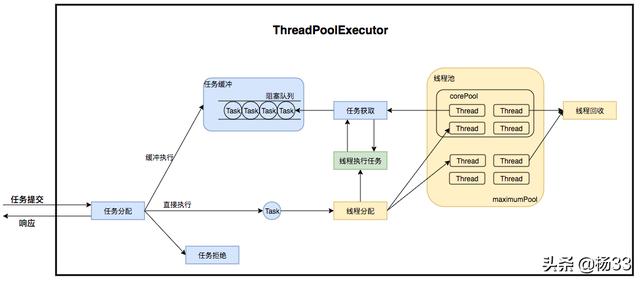
ThreadPoolExecutor运行流程
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。
线程池的运行主要分成两部分:任务管理、线程管理。
任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行;(3)拒绝该任务。
线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
4.3、任务提交入口execute方法的执行过程
首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。如果线程数量workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。如果线程数量workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。如果线程数量workerCount >= corePoolSize && 线程数量workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。如果线程数量workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。其执行流程如下图所示:
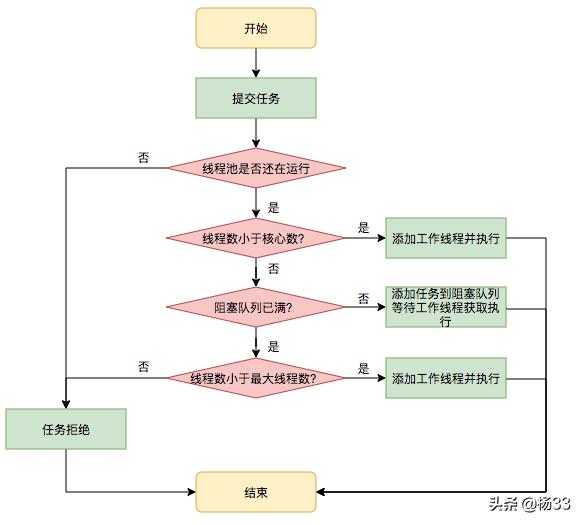
execute方法的执行流程
4.4、线程阻塞队列
线程池中是以生产者消费者模式实现的,而阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
下图中展示了阻塞队列缓存线程1,而工作线程2从阻塞队列中获取任务:
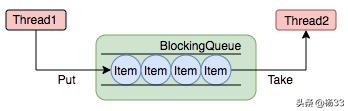
阻塞队列
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队列的成员:

阻塞队列的成员
4.5、getTask方法帮助线程从阻塞队列中不断获取任务
getTask方法可以帮助线程不断的从缓存队列中获取任务,实现线程管理模块(生产者)和任务管理模块(消费者)之间的通信。
其执行流程如下图所示:
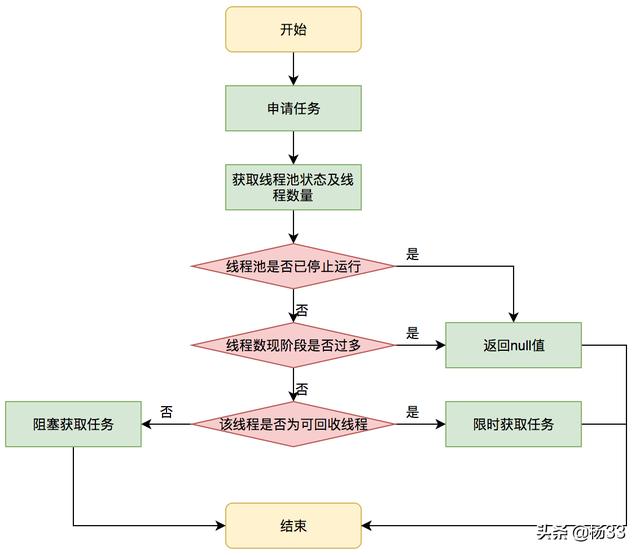
getTask方法获取任务流程图
4.6、任务拒绝策略,保护线程池
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
public interface RejectedExecutionHandler { void rejectedExecution(Runnable r, ThreadPoolExecutor executor);}用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略。
5、Worker线程管理
5.1、Worker线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看一下它的部分代码:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable { //Worker持有的线程 final Thread thread; //初始化的任务,可以为null Runnable firstTask;}Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。
thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务。
firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
Worker执行任务的模型如下图所示:
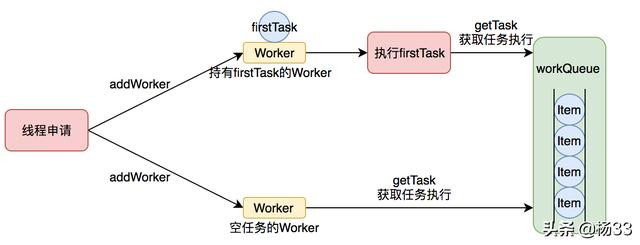
Worker执行任务
5.2、如何根据独占锁AQS,判断线程是否在运行,空闲状态的线程怎么回收?
空闲状态的线程回收判断流程:
- lock方法一旦获取了独占锁,表示当前线程正在执行任务中。
- 如果正在执行任务,则不应该中断线程。
- 如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
- 线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
5.3、Worker线程增加
增加线程是通过线程池中的addWorker方法,该方法的功能就是增加一个线程,该方法不考虑线程池是在哪个阶段增加的该线程,这个分配线程的策略是在上个步骤完成的,该步骤仅仅完成增加线程,并使它运行,最后返回是否成功这个结果。addWorker方法有两个参数:firstTask、core。firstTask参数用于指定新增的线程执行的第一个任务,该参数可以为空;core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize,其执行流程如下图所示:
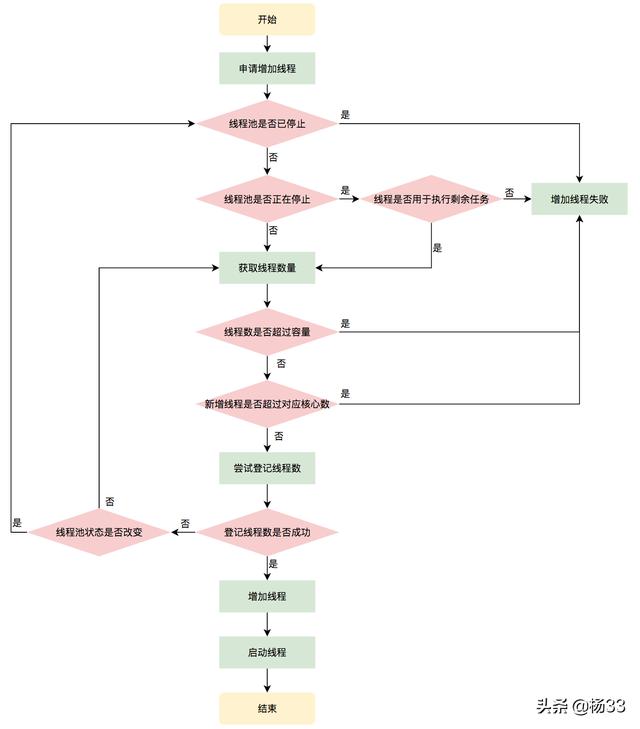
线程增加流程
5.4、Worker线程回收
线程池中线程的销毁依赖JVM自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被JVM回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可。Worker被创建出来后,就会不断地进行轮询,然后获取任务去执行,核心线程可以无限等待获取任务,非核心线程要限时获取任务。当Worker无法获取到任务,也就是获取的任务为空时,循环会结束,Worker会主动消除自身在线程池内的引用。
try { while (task != null || (task = getTask()) != null) { //执行任务 }} finally { //获取不到任务时,主动回收自己 processWorkerExit(w, completedAbruptly);}线程回收的工作是在processWorkerExit方法完成的。

Worker线程回收
事实上,在这个方法中,将线程引用移出线程池就已经结束了线程销毁的部分。但由于引起线程销毁的可能性有很多,线程池还要判断是什么引发了这次销毁,是否要改变线程池的现阶段状态,是否要根据新状态,重新分配线程。
5.5、Worker线程执行任务
在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
- while循环不断地通过getTask()方法获取任务。
- getTask()方法从阻塞队列中取任务。
- 如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。
- 执行任务。
- 如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。
执行流程如下图所示:
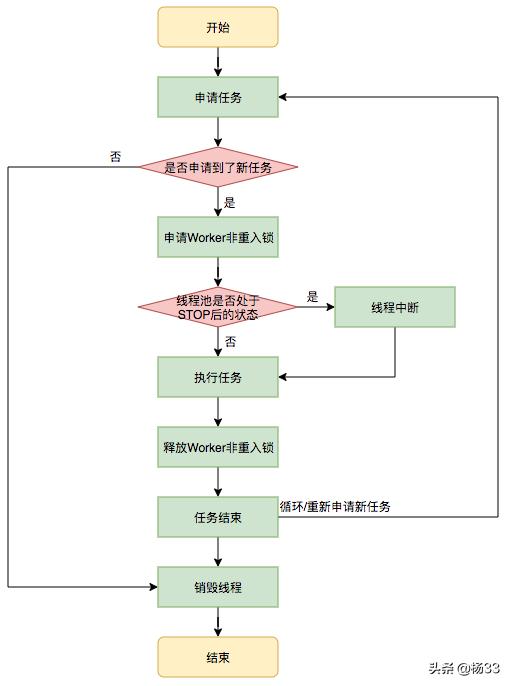
执行任务流程