目录
四、kfifo的入队__kfifo_put和出队__kfifo_get操作
1.++i和i++是线程安全的吗
i++ 先赋值再+1, ++i是先+1再赋值, 例如:
int i = 0;
int j = 0;
i = i++;
cout<<"i的最后结果" << i<<endl;//0;
j = i++;
cout<<"i的最后结果 "<< i<<endl;//1
cout<<"j的最后结果"<<j<<endl;//0
不论是++i还是i++都不是原子操作,在运行中都可能会有CPU调度产生,造成i的值被修改,造成脏读脏写。(读入eax寄存器,值+1,再赋值给地址 这个过程不是原子的,会存在竞争现象)
结论: 由于线程不共享栈区,共享堆区和全局区,所以当且仅当i 位于栈上是安全的,反之不安全。(栈,方法栈,是每个线程方法自己的,因为每个线程有自己的寄存器),atomic_int 和 各种 Lock 都可以确保线程安全。atomic_int 的效率高是因为它是互斥区非常小,只有一条指令,而 Lock 的互斥区是拿锁到放锁之间的区域,至少三条指令。
volatile不能解决这个线程安全问题。因为volatile只能
- 阻止编译器为了提高速度而将一个变量缓冲到寄存器而不写回
- 阻止编译器调整操作volatile变量的指令顺序
而不能阻止cpu动态调度顺序
因此解决方式有:
- 锁。
- atomic_int。(如atomic_int64_t total = 0; //atomic_int64_t相当于int64_t,但是本身就拥有原子性),其实现原理是利用处理器的CAS操作(Compare And Swap,比较与交换,一种有名的无锁算法)来检测栈中的值是否被其他线程改变,如果被改变则CAS操作失败。这种实现方法在CPU指令级别实现了原子操作,因此,其比使用synchronized来实现同步效率更高。
(CAS操作过程都包含三个运算符:内存地址V、期望值E、新值N。当操作的时候,如果地址V上存放的值等于期望值E,则将地址V上的值赋为新值N,否则,不做任何操作,但是要返回原值是多少。这就保证比较和设置这两个动作是原子操作。系统主要利用JNI(Java Native Interface,Java本地接口)来保证这个原子操作,它利用CPU硬件支持来完成,使用硬件提供swap和test_and_set指令,但CPU下同一指令的多个指令周期不可中断,SMP(Symmetric Multi-Processing)中通过锁总线支持这两个指令的原子性。)
i++和++i的区别:
i++:
int operator++(int)
{
int tmp = *this;
++*this;
return tmp;
}
++i:
int operator++()
{
++*this;
return *this;
}
2.无锁队列的实现
我们知道,加锁会降低性能
眉目传情之匠心独运的kfifo:原文 https://blog.csdn.net/chen19870707/article/details/39899743
作者:
Author:Echo Chen(陈斌)
Email:chenb19870707@gmail.com
Blog:Blog.csdn.net/chen19870707
Date:October 10th, 2014
| 本文分析的原代码版本 | 2.6.32.63 |
| kfifo的头文件 | include/linux/kfifo.h |
| kfifo的源文件 | kernel/kfifo.c |
一、kfifo概述
kfifo是一种"First In First Out “数据结构,它采用了环形缓冲区来实现,提供一个无边界的字节流服务。采用环形缓冲区的好处为,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率。更重要的是,kfifo采用了并行无锁技术,kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的。
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};这是kfifo的数据结构,kfifo主要提供了两个操作,__kfifo_put(入队操作)和__kfifo_get(出队操作)。 它的各个数据成员如下:
buffer: 用于存放数据的缓存
size: buffer空间的大小,在初化时,将它向上扩展成2的幂
lock: 如果使用不能保证任何时间最多只有一个读线程和写线程,需要使用该lock实施同步。
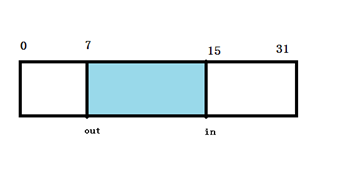
in, out: 和buffer一起构成一个循环队列。 in指向buffer中队头,而且out指向buffer中的队尾
它的结构如示图如下:
二、kfifo内存分配和初始化
首先,看一个很有趣的函数,判断一个数是否为2的次幂,按照一般的思路,求一个数n是否为2的次幂的方法为看 n % 2 是否等于0, 我们知道“取模运算”的效率并没有 “位运算” 的效率高,有兴趣的同学可以自己做下实验。下面再验证一下这样取2的模的正确性,若n为2的次幂,则n和n-1的二进制各个位肯定不同 (如8(1000)和7(0111)),&出来的结果肯定是0;如果n不为2的次幂,则各个位肯定有相同的 (如7(0111) 和6(0110)),&出来结果肯定为0。是不是很巧妙?
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}这里值得一提的是,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展,这是内核一贯的做法。这样的好处不言而喻——对kfifo->size取模运算可以转化为与运算,如下:
kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
在kfifo_alloc函数中,使用size & (size – 1)来判断size 是否为2幂,如果条件为真,则表示size不是2的幂,然后调用roundup_pow_of_two将之向上扩展为2的幂。
这都是常用的技巧,只不过大家没有将它们结合起来使用而已
三、kfifo并发无锁奥秘---内存屏障
为什么kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的呢?天底下没有免费的午餐的道理人人都懂,下面我们就来看看kfifo实现并发无锁的奥秘。
我们知道编译器编译源代码时,会将源代码进行优化,将源代码的指令进行重排序,以适合于CPU的并行执行。然而,内核同步必须避免指令重新排序,优化屏障(Optimization barrier)避免编译器的重排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
举个例子,如果多核CPU执行以下程序:
1: a = 1;
2: b = a + 1;
3: assert(b == 2);假设初始时a和b的值都是0,a处于CPU1-cache中,b处于CPU0-cache中。如果按照下面流程执行这段代码:
1 CPU0执行a=1;
2 因为a在CPU1-cache中,所以CPU0发送一个read invalidate消息来占有数据
3 CPU0将a存入store buffer
4 CPU1接收到read invalidate消息,于是它传递cache-line,并从自己的cache中移出该cache-line
5 CPU0开始执行b=a+1;
6 CPU0接收到了CPU1传递来的cache-line,即“a=0”
7 CPU0从cache中读取a的值,即“0”
8 CPU0更新cache-line,将store buffer中的数据写入,即“a=1”
9 CPU0使用读取到的a的值“0”,执行加1操作,并将结果“1”写入b(b在CPU0-cache中,所以直接进行)
10 CPU0执行assert(b == 2); 失败
软件可通过读写屏障强制内存访问次序。读写屏障像一堵墙,所有在设置读写屏障之前发起的内存访问,必须先于在设置屏障之后发起的内存访问之前完成,确保内存访问按程序的顺序完成。Linux内核提供的内存屏障API函数说明如下表。内存屏障可用于多处理器和单处理器系统,如果仅用于多处理器系统,就使用smp_xxx函数,在单处理器系统上,它们什么都不要。
| 适用于多处理器的读内存屏障。 |
| 适用于多处理器的写内存屏障。 |
| 适用于多处理器的内存屏障。 |
如果对上述代码加上内存屏障,就能保证在CPU0取a时,一定已经设置好了a = 1:
1: void foo(void)
2: {
3: a = 1;
4: smp_wmb();
5: b = a + 1;
6: }
这里只是简单介绍了内存屏障的概念,如果想对内存屏障有进一步理解,请参考作者的译文《为什么需要内存屏障》。
四、kfifo的入队__kfifo_put和出队__kfifo_get操作
1: unsigned int __kfifo_put(struct kfifo *fifo,
2: const unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->size - fifo->in + fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->out index -before- we
10: * start putting bytes into the kfifo.
11: */
12:
13: smp_mb();
14:
15: /* first put the data starting from fifo->in to buffer end */
16: l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
17: memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
18:
19: /* then put the rest (if any) at the beginning of the buffer */
20: memcpy(fifo->buffer, buffer + l, len - l);
21:
22: /*
23: * Ensure that we add the bytes to the kfifo -before-
24: * we update the fifo->in index.
25: */
26:
27: smp_wmb();
28:
29: fifo->in += len;
30:
31: return len;
32: }6行,环形缓冲区的剩余容量为fifo->size - fifo->in + fifo->out,让写入的长度取len和剩余容量中较小的,避免写越界;
13行,加内存屏障,保证在开始放入数据之前,fifo->out取到正确的值(另一个CPU可能正在改写out值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1),所以fifo->size - (fifo->in & (fifo->size - 1)) 即位 fifo->in 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为需要拷贝l 字节到fifo->buffer + fifo->in的位置上。
17行,拷贝l 字节到fifo->buffer + fifo->in的位置上,如果l = len,则已拷贝完成,第20行len – l 为0,将不执行,如果l = fifo->size - (fifo->in & (fifo->size - 1)) ,则第20行还需要把剩下的 len – l 长度拷贝到buffer的头部。
27行,加写内存屏障,保证in 加之前,memcpy的字节已经全部写入buffer,如果不加内存屏障,可能数据还没写完,另一个CPU就来读数据,读到的缓冲区内的数据不完全,因为读数据是通过 in – out 来判断的。
29行,注意这里 只是用了 fifo->in += len而未取模,这就是kfifo的设计精妙之处,这里用到了unsigned int的溢出性质,当in 持续增加到溢出时又会被置为0,这样就节省了每次in向前增加都要取模的性能,锱铢必较,精益求精,让人不得不佩服。
__kfifo_get是出队操作,它从buffer中取出数据,然后移动out的位置,其源代码如下:
1: unsigned int __kfifo_get(struct kfifo *fifo,
2: unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->in - fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->in index -before- we
10: * start removing bytes from the kfifo.
11: */
12:
13: smp_rmb();
14:
15: /* first get the data from fifo->out until the end of the buffer */
16: l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
17: memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
18:
19: /* then get the rest (if any) from the beginning of the buffer */
20: memcpy(buffer + l, fifo->buffer, len - l);
21:
22: /*
23: * Ensure that we remove the bytes from the kfifo -before-
24: * we update the fifo->out index.
25: */
26:
27: smp_mb();
28:
29: fifo->out += len;
30:
31: return len;
32: }
6行,可去读的长度为fifo->in – fifo->out,让读的长度取len和剩余容量中较小的,避免读越界;
13行,加读内存屏障,保证在开始取数据之前,fifo->in取到正确的值(另一个CPU可能正在改写in值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->out % kfifo->size 可以转化为 kfifo->out & (kfifo->size – 1),所以fifo->size - (fifo->out & (fifo->size - 1)) 即位 fifo->out 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为从fifo->buffer + fifo->in到末尾所要去读的长度。
17行,从fifo->buffer + fifo->out的位置开始读取l长度,如果l = len,则已读取完成,第20行len – l 为0,将不执行,如果l =fifo->size - (fifo->out & (fifo->size - 1)) ,则第20行还需从buffer头部读取 len – l 长。
27行,加内存屏障,保证在修改out前,已经从buffer中取走了数据,如果不加屏障,可能先执行了增加out的操作,数据还没取完,令一个CPU可能已经往buffer写数据,将数据破坏,因为写数据是通过fifo->size - (fifo->in & (fifo->size - 1))来判断的 。
29行,注意这里 只是用了 fifo->out += len 也未取模,同样unsigned int的溢出性质,当out 持续增加到溢出时又会被置为0,如果in先溢出,出现 in < out 的情况,那么 in – out 为负数(又将溢出),in – out 的值还是为buffer中数据的长度。
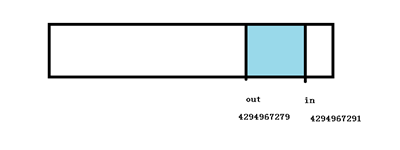
这里图解一下 in 先溢出的情况,size = 64, 写入前 in = 4294967291, out = 4294967279 ,数据 in – out = 12;
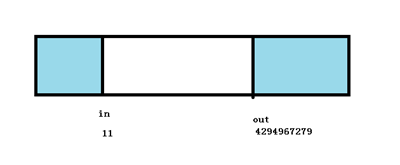
写入 数据16个字节,则 in + 16 = 4294967307,溢出为 11,此时 in – out = –4294967268,溢出为28,数据长度仍然正确,由此可见,在这种特殊情况下,这种计算仍然正确,是不是让人叹为观止,妙不可言?
五、扩展
kfifo设计精巧,妙不可言,但主要为内核提供服务,内存屏障函数也主要为内核提供服务,并未开放出来,但是我们学习到了这种设计巧妙之处,就可以依葫芦画瓢,写出自己的并发无锁环形缓冲区,这将在下篇文章中给出,至于内存屏障函数的问题,好在gcc 4.2以上的版本都内置提供__sync_synchronize()这类的函数,效果相差不多。《无锁队列的实现》给出自己的并发无锁的实现,有兴趣的朋友可以参考一下。
3.进程间加锁
一、互斥量 mutex
进程间也可以使用互斥锁 ,来达到同步的目的。但应在 pthread_mutex_init 初始化之前,修改其属性为进程间共享。mutex 的属性修改函数主要有以下几个。
主要应用函数:
1、pthread_mutexattr_t mutexattr 类型: 用于定义互斥锁的属性。
2、pthread_mutexattr_init 函数: 初始化一个 mutex 属性对象
int pthread_mutexattr_init(pthread_mutexattr_t *attr);
3、pthread_mutexattr_destroy 函数: 销毁 mutex 属性对象(而非销毁锁)
int pthread_mutexattr_destroy(pthread_mutexattr_t *attr);
4、pthread_mutexattr_setpshared 函数: 修改 mutex 属性
int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr,int pshared);
参数 2 :pshared 取值:
线程锁: PTHREAD_PROCESS_PRIVATE( mutex 的默认属性即为线程锁,进程间私有)
进程锁:PTHREAD_PROCESS_SHARED 进程间互斥量操作代码示例:
/*
互斥量 实现 多进程 之间的同步
*/
#include<unistd.h>
#include<sys/mman.h>
#include<pthread.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<fcntl.h>
#include<string.h>
#include<stdlib.h>
#include<stdio.h>
struct mt
{
int num;
pthread_mutex_t mutex;
pthread_mutexattr_t mutexattr;
};
int main(void)
{
int i;
struct mt* mm;
pid_t pid;
/*
// 创建映射区文件
int fd = open("mt_test",O_CREAT|O_RDWR,0777);
if( fd == -1 )
{
perror("open file:");
exit(1);
}
ftruncate(fd,sizeof(*mm));
mm = mmap(NULL,sizeof(*mm),PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
close(fd);
unlink("mt_test");
*/
// 建立映射区
mm = mmap(NULL,sizeof(*mm),PROT_READ|PROT_WRITE,MAP_SHARED|MAP_ANON,-1,0);
// printf("-------before memset------\n");
memset(mm,0x00,sizeof(*mm));
// printf("-------after memset------\n");
pthread_mutexattr_init(&mm->mutexattr); // 初始化 mutex 属性
pthread_mutexattr_setpshared(&mm->mutexattr, PTHREAD_PROCESS_SHARED); // 修改属性为进程间共享
pthread_mutex_init(&mm->mutex,&mm->mutexattr); // 初始化一把 mutex 锁
pid = fork();
if( pid == 0 ) // 子进程
{
for( i=0; i<10;i++ )
{
pthread_mutex_lock(&mm->mutex);
(mm->num)++;
printf("-child--------------num++ %d\n",mm->num);
pthread_mutex_unlock(&mm->mutex);
sleep(1);
}
}
else
{
for( i=0;i<10;i++)
{
sleep(1);
pthread_mutex_lock(&mm->mutex);
mm->num += 2;
printf("--------parent------num+=2 %d\n",mm->num);
pthread_mutex_unlock(&mm->mutex);
}
wait(NULL);
}
pthread_mutexattr_destroy(&mm->mutexattr); // 销毁 mutex 属性对象
pthread_mutex_destroy(&mm->mutex); // 销毁 mutex 锁
return 0;
}二、文件锁
借助 fcntl 函数来实现文件锁。操作文件的进程没有获得锁时,可以打开,但无法执行 read,write 操作。
fcntl 函数:获取、设置文件访问控制属性。
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
参数 2 :
F_SETLK(struct flock *); 设置文件锁 ( trylock )
F_SETLKW(struct flock*); 设置文件锁( lock ) W --- wait
F_GETLK(struct flock*); 获取文件锁
参数 3 :
struct flock {
...
short l_type; /* Type of lock: F_RDLCK,
F_WRLCK, F_UNLCK */
short l_whence; /* How to interpret l_start:
SEEK_SET, SEEK_CUR, SEEK_END */
off_t l_start; /* Starting offset for lock */
off_t l_len; /* Number of bytes to lock */
pid_t l_pid; /* PID of process blocking our lock
(F_GETLK only) */
...
};进程间文件锁 代码示例:
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdio.h>
#include<stdlib.h>
void sys_err(char*str)
{
perror(str);
exit(1);
}
int main(int argc,char *argv[])
{
int fd;
struct flock f_lock;
if( argc< 2 )
{
printf("./a.out filename\n");
exit(1);
}
if( ( fd = open(argv[1],O_RDWR)) < 0 )
sys_err("open");
// f_lock.l_type = F_WRLCK; // 选用写锁
f_lock.l_type = F_RDLCK; // 选用读锁
f_lock.l_whence = 0;
f_lock.l_len = 0; // 0 表示整个文件加锁
fcntl(fd,F_SETLKW,&f_lock);
printf("get flock\n");
sleep(10);
f_lock.l_type = F_UNLCK;
fcntl(fd,F_SETLKW,&f_lock);
printf("un flock\n");
close(fd);
return 0;
}