经过决定运用Python Scrapy库进行数据爬取,于是开展了针对Scrapy的学习
1.整体架构
官方解析:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
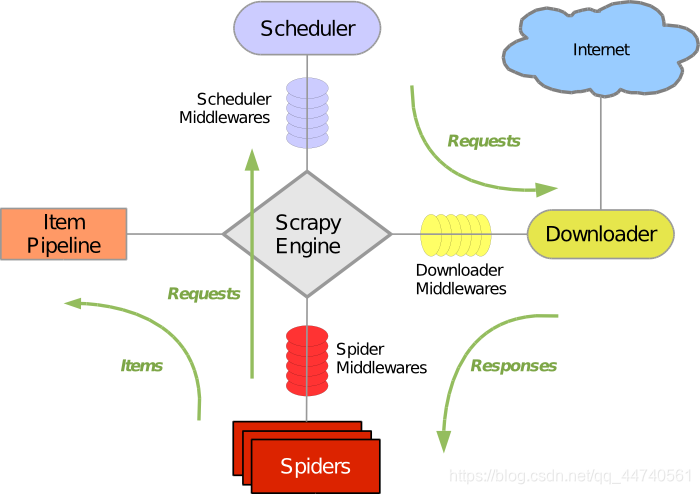
架构理解:
Scrapy Engine:即Scrapy引擎,负责综合控制各个事件,并调度各个部件;
Scheduler:即调度器,从引擎接收信号后将数据入列,并可再次返回给引擎,用于决定操作的调度顺序;
Downloader:即下载器,抓取网页并将网页内容返还给Spiders;
Spiders:即爬虫,自定义的类,用以解析网页,发起url请求和提取item;
Item Pipelines:即管道,处理spider提取出的item,可用于存储等操作。
2.初步实现
在安装配置好scrapy后在cmd中开始新项目,
scrapy startproject youtube随后初步设定各个基本文件的参数以及属性,
items.py中定义想要爬取的各个数据,
class User(scrapy.Item):
#设置用户所需爬取信息
user_name = scrapy.Field() #用户名称
user_id = scrapy.Field() #用户ID
user_icon = scrapy.Field() #用户头像
user_fansnum = scrapy.Field() #用户粉丝数
user_desc = scrapy.Field() #用户简介
class Video(scrapy.Item):
#设置视频所需爬取信息
video_title = scrapy.Field() #视频标题
video_pubtime = scrapy.Field() #发布时间
video_viewcount = scrapy.Field() #播放量
video_id = scrapy.Field() #视频IDsetting.py中设置项目名称、管线优先度、是否遵守机器人协议以及数据库相关属性等,
BOT_NAME = 'youtube'
LOG_LEVEL= 'INFO'
SPIDER_MODULES = ['youtube.spiders']
NEWSPIDER_MODULE = 'youtube.spiders'
ITEM_PIPELINES = {
'youtube.pipelines.YoutubeSavePipeline':300,
}
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
# mysql连接配置
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'youtube'
MYSQL_USER = 'root'
MYSQL_PASSWD ='********'
MYSQL_PORT = 3306pipline.py中可设置好数据库相关的配置,
def __init__(self):
# 连接到数据库
self.connect = pymysql.connect(host='localhost', user='root', password='********', db='youtube', port=3306)
self.cursor = self.connect.cursor()
此后可打开Spider文件夹进行自定义爬虫的编写。
版权声明:本文为qq_44740561原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。