## 一、系统基础操纵:
1、修改主机名
sudo hostnamectl set-hostname hadoop
bash
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LEqeHAg7-1664255722246)(:/ee9ce513a2e24ade80c7e23577721e20)]](https://img-blog.csdnimg.cn/f7aaec6af0a14ad7a851e28b6bfac705.png)
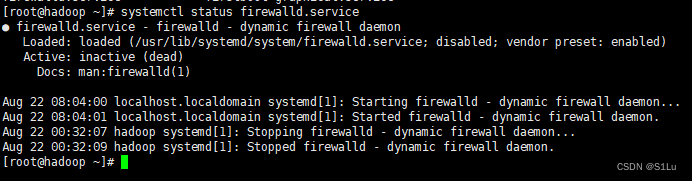
2、禁用防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service

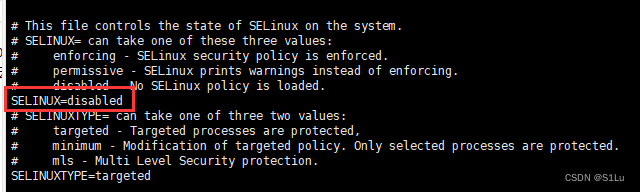
3、禁用SELinux
vi /etc/selinux/config

4、修改repo源
5、安装软件
二、Java环境配置
1、解压
tar -zxf jdk-8u221-linux-x64.tar.gz -C /opt/module/

2、配置系统环境变量
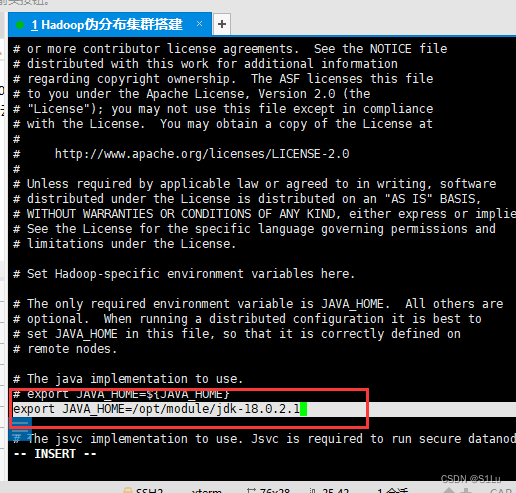
vi /etc/profile.d/hadoop.sh
export JAVA_HOME=/opt/module/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
![(:/fd350a77086341629c77c0dfe6aa10f2)]](https://img-blog.csdnimg.cn/45f5505c4f2a40c6832481c51e1ba442.png)

3、生效
source /etc/profile.d/hadoop.sh

4、测试
java -version

三、ssh免密登录
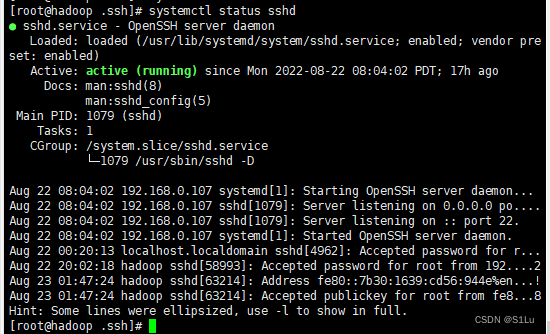
1、启动ssh守护进程
systemctl start sshd

2、查看状态
systemctl status sshd
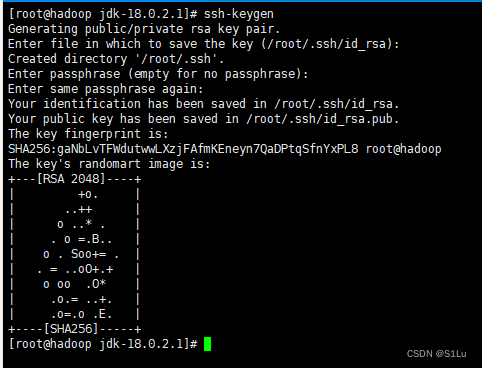
3、生成密钥对
ssh-keygen
4、切换目录
cd ~/.ssh/

5、添加公钥
cat id_rsa.pub > authorized_keys

6、修改权限
chmod 600 authorized_keys

7、使用本机做回环测试
ssh root@hadoop
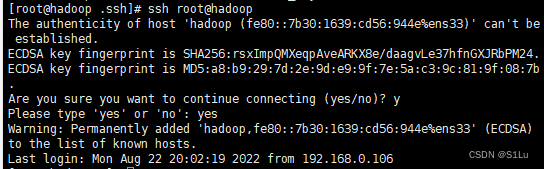
8、退出
exit

四 、gadoop配置安装
1、解压压缩包
tar -xzf hadoop-2.7.7.tar.gz -C /opt/module/

2、 配置hadoop系统环境变量
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_PATH/sbin

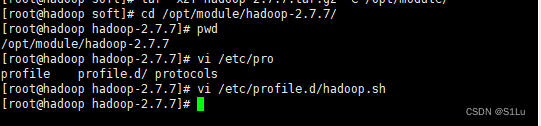
3、使脚本生效
source /etc/profile.d/hadoop.sh

4、查看是否生效
hadoop version
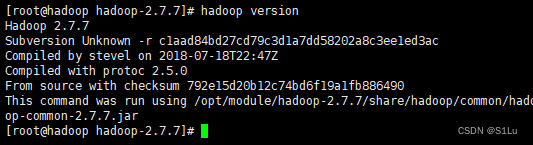
五、配置HDFS
1、配置hadoop-env.sh中的JAVA_HOME
先进入
/opt/module/hadoop-2.7.7/etc/hadoop
vi hadoop-env.sh
:! echo $JAVA_HOME
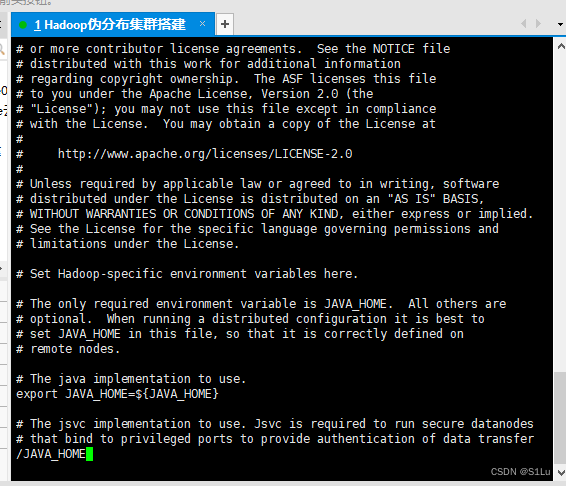
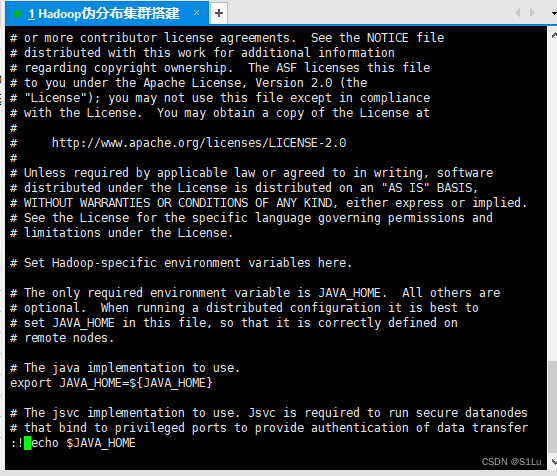
/opt/module/jdk1.8.0_221
2、配置core-site.xml
vi core-site.xml
新的
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
原来的
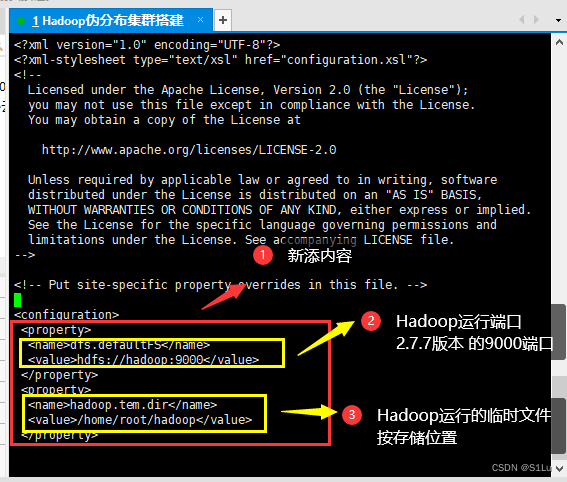
<property>
<name>dfs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/root/hadoop</value>
</property>
3、配置hdfs-site.xml
vi hdfs-site.xml

<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/root/hadoop/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:///home/root/hadoop/data</value>
</property>
4、配置mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
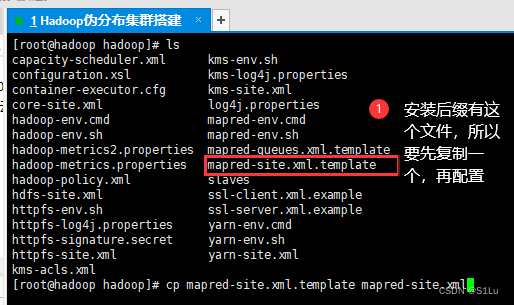
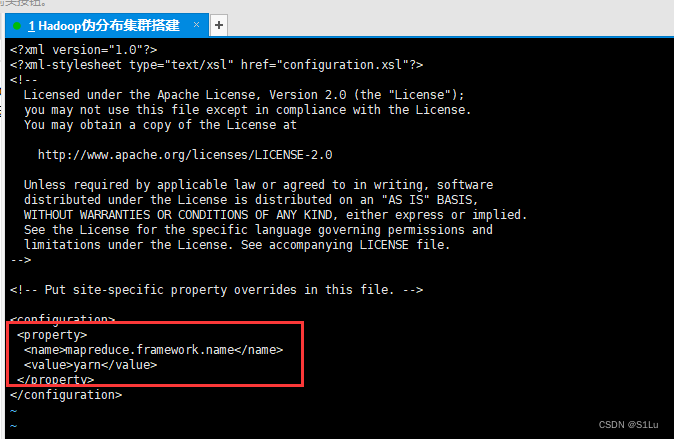
vi mapred-site.xml

<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
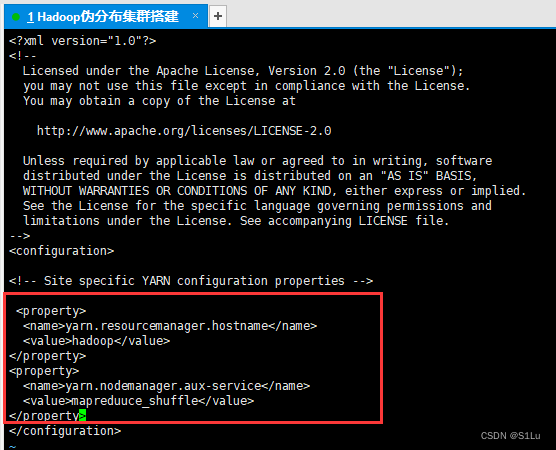
5、配置yarn-site.xml
vi yarn-site.xml

<property>
<name>yarn.resourcemanager.hostname</sname>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
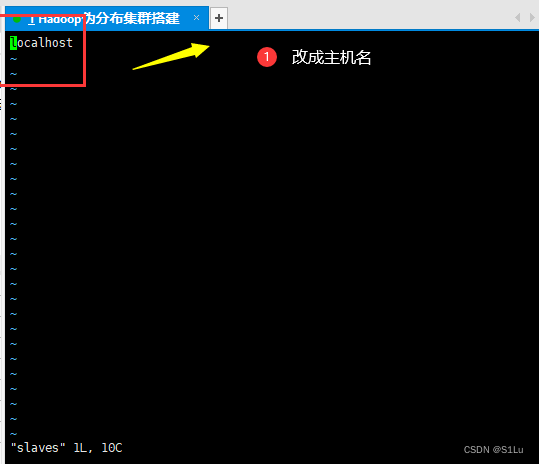
6、配置slaves
vi slaves

7、格式化NameNode
hdfs namenode -format
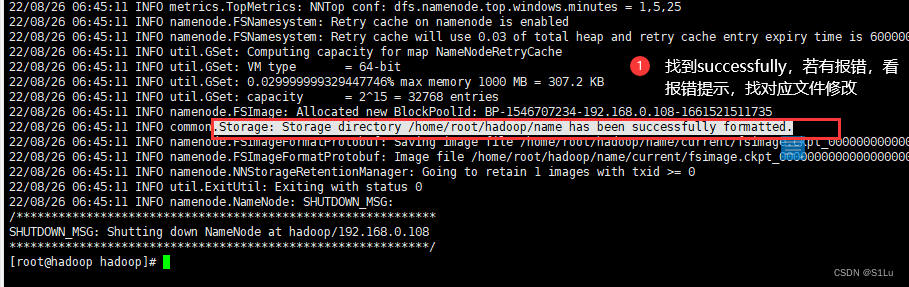
六、启动Hadoop
在/opt/module/hadoop-2.7.7/sbin下
bash start-all.sh

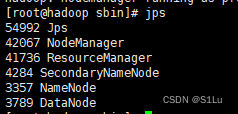
查看启动:
jps
http://192.168.0.108:50070/dfshealth.html#tab-overview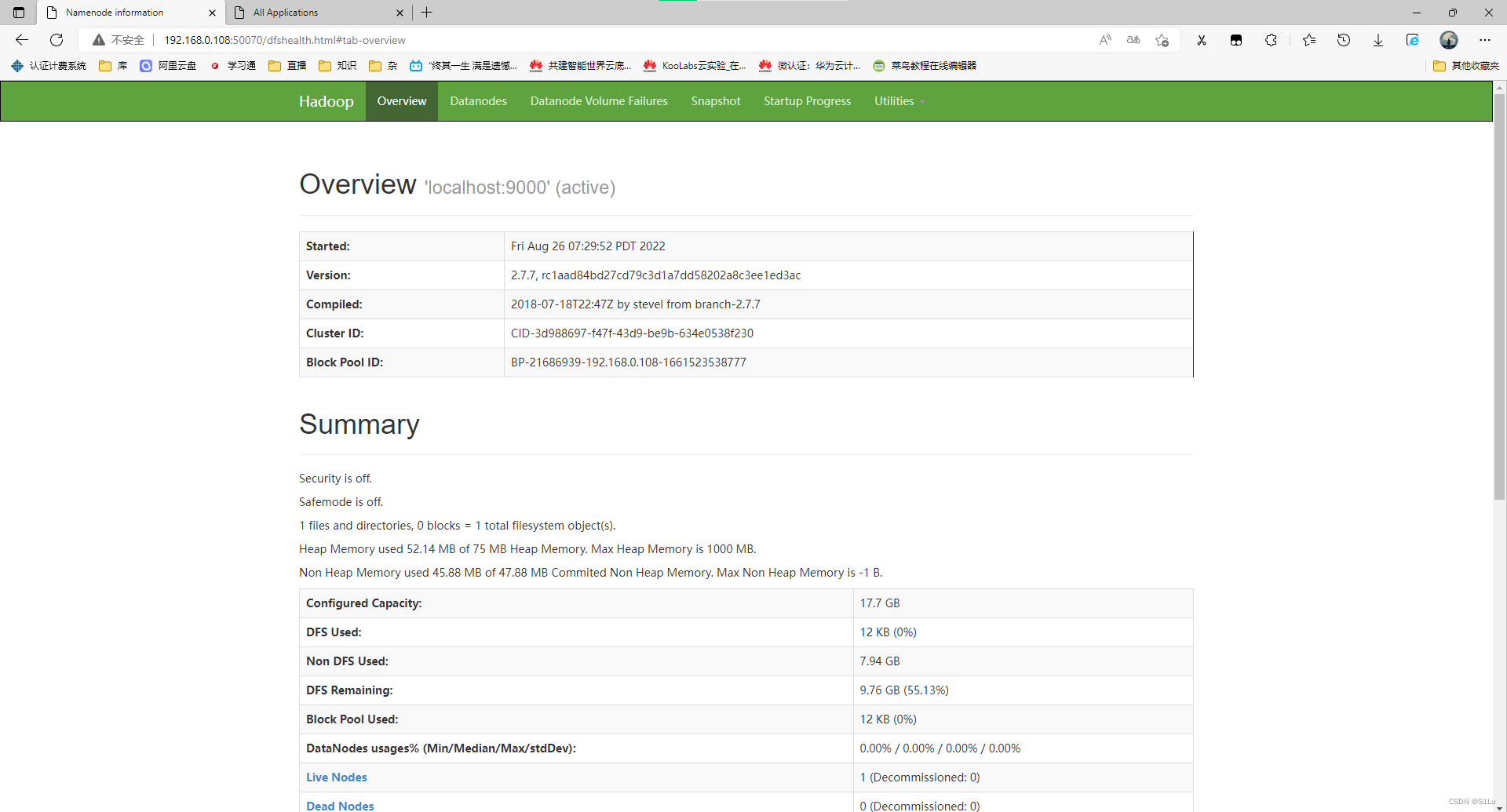
http://192.168.0.108:8088/cluster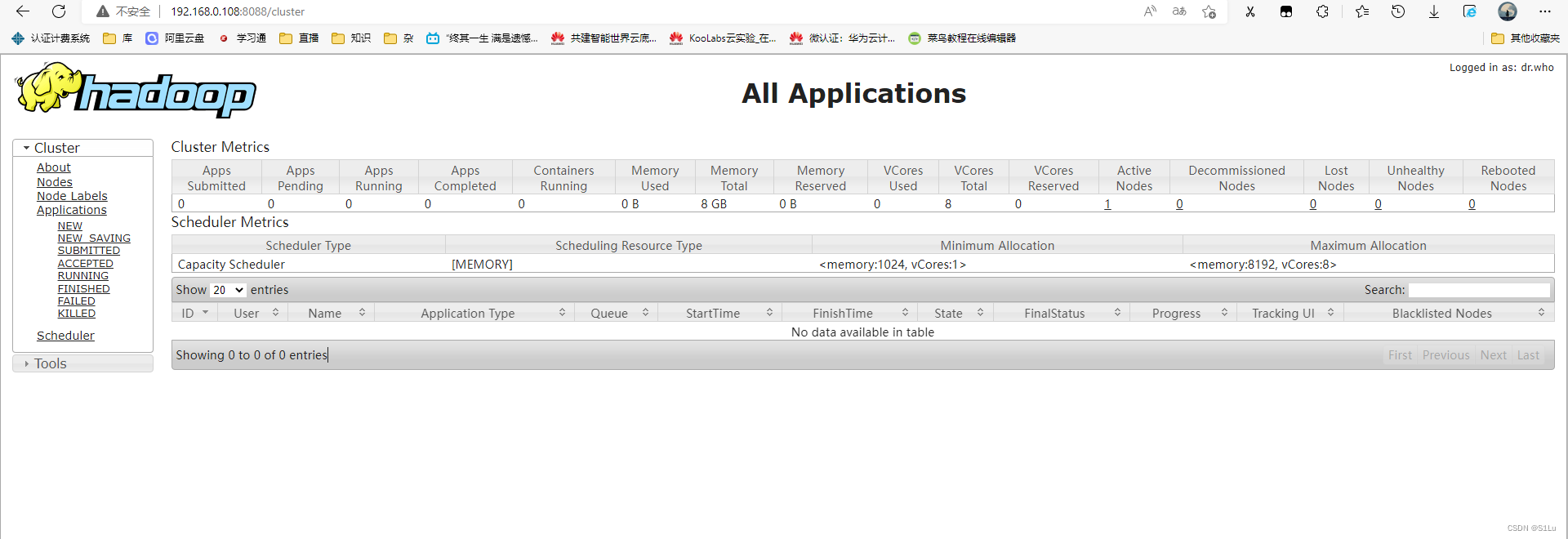
结语
2022-08-27 12:08 凌晨
由于jar包导错了,导致最后的运行 出现不兼容现象,运行失败,两小时时间排错。卸载重装jdk,解决问题。要注意环境的需求。
报错处理
参考大佬连接:
https://www.javaroad.cn/questions/79621
版权声明:本文为qq_51644623原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。