数据库的基础知识
数据库系统(DBS)
是按照数据结构来组织,存储和管理数据的仓库,数据库通常分为层次式数据库, 网状式数据库, 关系型数据库三种,不同的数据库是按照不同的数据结构来进行联系和组织的,将反映和实现数据联系的方法称为数据模型数据库管理系统(DBMS)
是一种操纵和管理数据库的大型文件,用于建立,使用和维护数据库,简称DBMS. 他对数据库进行统一的管理和控制,以保证数据库的安全性和完整性.常见的关系型数据库
DB2, Sybase, Oracle, MySQL, Access, MS, SQLserver
oracle数据库管理系统
1) oracle数据库管理系统是由oracle数据库和oracle实例构成的(mysql中没有实例的概念)
2)oracle实例:
位于物理内存的数据结构,它由操作系统的多个后台进程和共享的内存池所组成,共享内存可以被所有的进程访问.实质上oracle实例就是平常所说的数据库服务(service),在任何时刻,一个实例只能与一个数据库关联,访问同一个数据库;而同一个数据库可由多个实例访问
oracle的存储结构
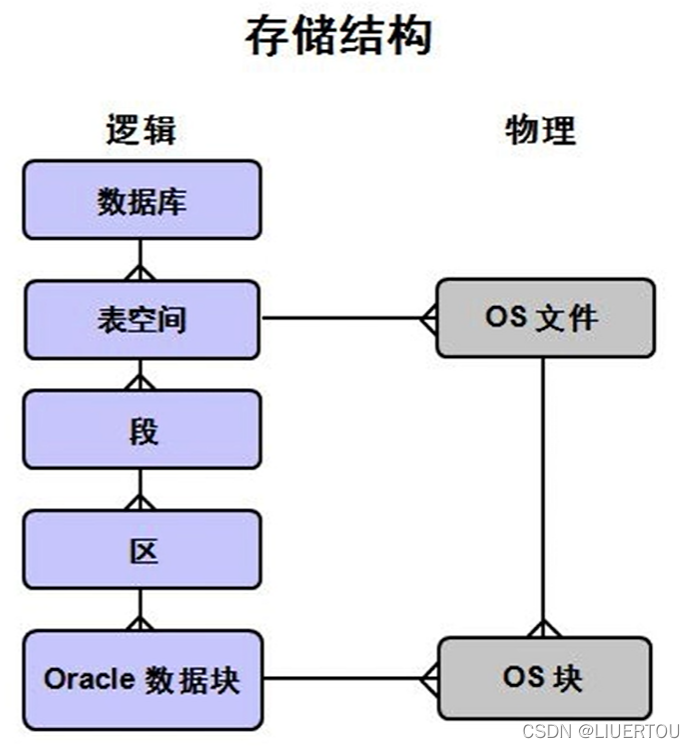
Oracle的整体架构

- 说明:
1)一般Oracle数据库是由: 实例和数据库两部分组成的
2)数据库是一系列的物理文件的集合(数据文件,控制文件, 联机日志, 参数文件) 而Oracle数据库由操作系统文件组成, 这些文件也称为数据库文件,为数据库信息提供物理存储区
3)实例则是一组Oracle后台进程/线程以及在服务器分配的共享内存区.
4)Oracle可以创建多个oracle数据库,一个oracle数据库将又由实例和数据库构成,
SQL plus的常用命令
- 显示设置
-- 设置每行显示的最长字符
set linesize 120;
-- 设置一页显示的记录数
set pagesize 20;
-- 设置是否显示一页的记录数
set feedback on/off;
-- 打开或取消oracle自带的输出方法dbms_output, 并输出内容
set serveroutput on/off;
-- 表明将empno列名对应的列值格式为4位长度的数值型
col empno for 9999;
-- 指定一个文件夹目录,将多有的输出命令追加到这个文件中
spool 文件目录;
-- 输入完成后直接关闭自动保存
spool off;
-- 追加记录
spool 文件目录 append;
- 其他命令
-- 清空屏幕的命令
clear screen / host cls
-- 显示系统的所有参数变量值
show all
-- 显示当前的用户
show user
表空间
说明
表空间是数据库中最大的逻辑单位, oracle数据库采用表空间将相关的逻辑组件组合在一起, 一个oracle数据库至少有一个表空间, 每个表空间由一个或多个数据文件组成, 一个数据文件只能与一个表空间联系表空间的类型
1)永久性表空间: 一般只保存表, 视图, 过程, 和索引等数据
2)临时性表空间: 在当前会话中有效
3)撤销表空间:
- 表空间相关语法
-- 创建表空间的语句
CREATE TABLESPACE 表空间名
DATAFILE '数据文件路径' SIZE 大小
[AUTOEXTEND ON] [NEXT 大小]
[MAXSIZE 大小];
------------------------------------
SIZE为初始表空间大小,单位为K或者M
AUTOEXTEND ON 是否自动扩展
NEXT为文件满了后扩展大小
MAXSIZE为文件最大大小,值为数值或UNLIMITED(表示不限大小)
-- 查询表空间
select file_name, tablespace_name, bytes, autoextensible from dba_data_files where tablespace='表空间名'
-- 修改表空间
ALTER TABLESPACE 表空间名
ADD DATAFILE '文件路径' SIZE 大小
[AUTOEXTEND ON] [NEXT 大小]
[MAXSIZE 大小];
-- 删除表空间
DROP TABLESPACE 表空间名;
DROP TABLESPACE 表空间名 INCLUDING CONTENTS AND DATAFILES;(删的最干净)
数据库用户
-- 系统的用户
sys
system(默认系统的管理员,拥有DBA权限)
-- 查询系统用户
select * from all_users;
-- 解锁用户
alter user 用户名 account unlock;
Oracle中用户的创建
-- 连接Oracle数据库
conn sys/root as sysdba
-- 创建一个表空间
create tablespace test01_space datafile 'c:/tbspace/scott_tb_space.dbf' size 200m;
-- 创建一个用户scott,设置密码,指定一个表空间
create user scott identified by tiger default tablespace test01_space;
-- 给用户scott 一个最高的权限
grant dba to scott;
-- 修改用户密码
alter user itcast identified by it;
-- 删除用户
drop user itcast cascade;
-- 查看当前用户的对象权限
select * from user_tab_privs;
-- 查看当前用户的所有角色
select * from user_role_privs;
-- 撤销用户权限和角色
revoke connect, resource from itcast
revoke select from itcast;
数据库DDL语言
创建表
【语法】
CREATE TABLE <table_name>(
column1 DATATYPE [NOT NULL] [PRIMARY KEY],
column2 DATATYPE [NOT NULL],
...
[constraint <约束名> 约束类型 (要约束的字段)
... ] );
【说明】
DATATYPE --是Oracle的数据类型
NUT NULL --可不可以允许资料有空的(尚未有资料填入)
PRIMARY KEY --是本表的主键
constraint --是对表里的字段添加约束.(约束类型有
Check,Unique,Primary key,not null,Foreign key);
-------------------------------------------
示例:
-- 创建表
create TABLE t_student(
s_id number(8) primary key,
s_name varchar2(30),
s_sex varchar(8),
clsid number(8),
constraint c_uni_stu_name unique(s_name),
constraint c_checl_sex check(s_sex in ('男','女'))
);
-- 插入数据
INSERT into t_student values(1234, 'itcast01', '男', 21);
-- 查询数据
SELECT * FROM t_student;
---------------------------------
-- 从已经存在的表创建表(创建表的第二种方式)
create table emp as select * from scott.emp;
-- 如果只复制表结构不复制表的数据
create table emp as select * from scott.emp where 1=2;
修改表和删除表
-- 修改表,新增加列
alter table t_student add(a_age number(3), s_address varchar(20));
-- 修改表中的字段
alter table t_student modify(s_name varchar2(50),s_address varchar2(100));
-- 删除表中的字段
alter table t_student drop(s_age,s_address);
-- 修改表表字段名
alter table t_student rename column s_id to s_no;
-- 删除表/ 删除表不经过回收站
drop table t_student;
drop table t_student purge;
回收站
--查看回收站
show recyclebin / select * from recyclebin;
--清空回收站
purge recyclebin;
oracle数据类型
1)varchar(size): 可变长度字符串,size的最大值为4000,最小值为1
2)nvarchar2(size): 可变长度字符串,依据所选的国家字符集
3)number(p,s): 精度为p,并且数值范围为s的数值,例如number(5,2)表示整数的最大位数为3位,小数部分为2位
4)long: 可变长度的字符数据,其长度可达2G个字节
5)date: 日期数据
DML语言
-- 插入数据
insert into emp (empno,ename) values(1111,'itcast');
-- 条件筛选插入数据
insert into t1 select * from emp where sal>2000;
-- 修改数据
update emp set sal=3000 where ename='itcast';
伪表dual和伪列
- dual : 是一个虚拟表,用来构成select的语法法则,oracle保证dual里面永远只有一条记录
- 伪列rowID: 是物理结构上的,每条记录的insert到数据库中都会有一个唯一的物理记录,同一条记录在不同的查询中对应的rowID相同
- 伪列rownum: 是根据SQL查询的结果给每行分配一个逻辑的编号,每次查询都会有不同的编号
-- 查询当前的用户
select user from dual;
-- 查询系统当前的时间并格式化
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
-- 在select中计算
select 8*8 from dual;
--------------------------------
-- 查询伪列rowid
select rowid, emp.* from emp;
-- 查询伪列rownum
select rownum, emp.* from emp;
DQL操作
-- 等值查询
select empno,ename,dname from emp,dept where emp.deptno=dept.deptno
--左外连接查询
--(方式一)
select d.deptno,d.dname,count(e.empno) from dept d,emp e
where d.deptno=e.deptno(+) group by d.deptno,d.dname;
--(方式二)上述语句的通用数据库写法(left join方式)
select d.deptno,d.dname,count(e.empno) from dept d left join emp e
on d.deptno=e.deptno group by d.deptno,d.dname;
-- 自连接查询(查询的2张表是同一张表,一般是该表的字段之间存在上下级关系)
select e.ename || ' 的老板是: '|| b.ename from emp e,emp b
where e.mgr=b.empno;
-- 删除操作(DDL)
delete from emp where empno=0000;
--清空表数据(DML)
truncate table myemp;
TCL事务操作
-- 保存点savepoint
savepoint a;
-- 回滚到a之前
rollback a;
commit;
视图
- 视图是一个或多个表组成的虚拟表,视图是一个逻辑的概念,视图中没有存储真实的数据,真正的数据还是存储在基表中,一般出于对基本的安全性和常用的查询语句会建立视图
-- 创建视图
CREATE [OR REPLACE] VIEW <视图名>
AS SELECT语句
-- 删除视图
DROP VIEW <view_name> ;
同义词
-- 语法
CREATE SYNONYM <synonym_name> for <tablename/viewname...>
【示例】
--管理员 授权用户itcast创建同义词的权限
grant create synonym to itcast;
--创建私有同义词
create synonym syn_emp for emp;
create synonym syn_v_emp for v_emp;--为视图v_emp创建私有同义词(别名)
--使用私有同义词
select empno,ename from syn_emp;
update syn_emp set ename='itcast5' where empno='1234';
--删除同义词
drop synonym syn_emp;
------------------------------------------------
-- 创建公有同义词的语句
CREATE PUBLIC SYNONYM <synonym_name> for <tablename/viewname...>;
索引的创建
-- 语句
CREATE [UNIQUE] INDEX <index_name> ON <table_name>(字段 [ASC|DESC]);
【说明】
UNIQUE --确保所有的索引列中的值都是可以区分的。
[ASC|DESC] --在列上按指定排序创建索引。
-- 删除索引
DROP INDEX <index_name>;
序列
- 序列就是oracle提供一个产生数值型值的机制,通常用于表的主键值,序列只能保证唯一,不能保证连续
语法:
CREATE SEQUENCE <sequencen_name>
[INCREMENT BY n]
[START WITH n]
[MAXVALUE n][MINVALUE n]
[CYCLE|NOCYCLE]
[CACHE n|NOCACHE];
INCREMENT BY n --表示序列每次增长的幅度;默认值为1.
START WITH n --表示序列开始时的序列号。默认值为1.
MAXVALUE n --表示序列可以生成的最大值(升序).
MINVALUE n --表示序列可以生成的最小值(降序).
CYCLE --表示序列到达最大值后,在重新开始生成序列.默认值为 NOCYCLE。
CACHE n--允许更快的生成序列.预先生成n个序列值到内存(如果没有使用完,那下次序列的值从内存最大值之后开始;所以n不应该设置太大)
分区表
分区表通过对分区列的判断,把分区列不同的记录,放到不同的分区中。分区完全对应用透明。Oracle的分区表可以包括多个分区,每个分区都是一个独立的段(SEGMENT),可以存放到不同的表空间中。查询时可以通过查询表来访问各个分区中的数据,也可以通过在查询时直接指定分区的方法来进行查询
分区表的优点:
(1)由于将数据分散到各个分区中,减少了数据损坏的可能性;
(2)可以对单独的分区进行备份和恢复;
(3)可以将分区映射到不同的物理磁盘上,来分散IO;
(4)提高可管理性、可用性和性能。
- 分区的类型
1)范围分区
2)散列分区
3)列表分区
4)复合分区(范围-散列分区,范围-列表分区)
5)间隔分区
6)系统分区
- 分区表的创建
-- 范围分区的创建
create table myemp
( empno number(4) primary key,
ename varchar2(10),
hiredate date,
sal number(7,2),
deptno number(2)
)
partition by range(sal)
(
partition p1 values less than(1000),
partition p2 values less than(2000),
partition p3 values less than(maxvalue)
);
-------------------------------------------------
-- 列表分区的创建(列表分区明确指定了根据某字段的某个具体值进行分区,而不是像范围分区那样根据字段的值范围来划分的)
create table myemp2
( empno number(4) primary key,
ename varchar2(10),
hiredate date,
sal number(7,2),
deptno number(2)
)
partition by list(deptno)
(
partition dept10 values(10),
partition dept20 values(20),
partition dept30 values(30),
partition deptx values(default)
);
版权声明:本文为LIUERTOU原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。