什么是模型融合?
模型融合:先产生一组学习器,再用某种方法将他们结合起来,从而达到加强模型的效果。
- 按照个体学习器的关系,模型融合技术分为两类:
- 个体学习器间不存在强依赖关系,采用并行化分法(代表有的:Bagging方法和随机森林)
- 个体学习器间存在强依赖关系,采用串行生成的序列化方法(代表的有:Boosting方法)
模型融合时常用到的算法有哪些?
Bagging方法和随机森林
- Bagging方法
- 从训练集抽样得到的每个基模型所需要的子训练集,并行地训练一堆 基模型,对其结果综合得到最终的预测结果。
- 采用自助采样法,即又放回的采样(每次的采
- 样集和原始的训练集不同,和其他采样集也不同,这样就可以得到多个弱学习器)
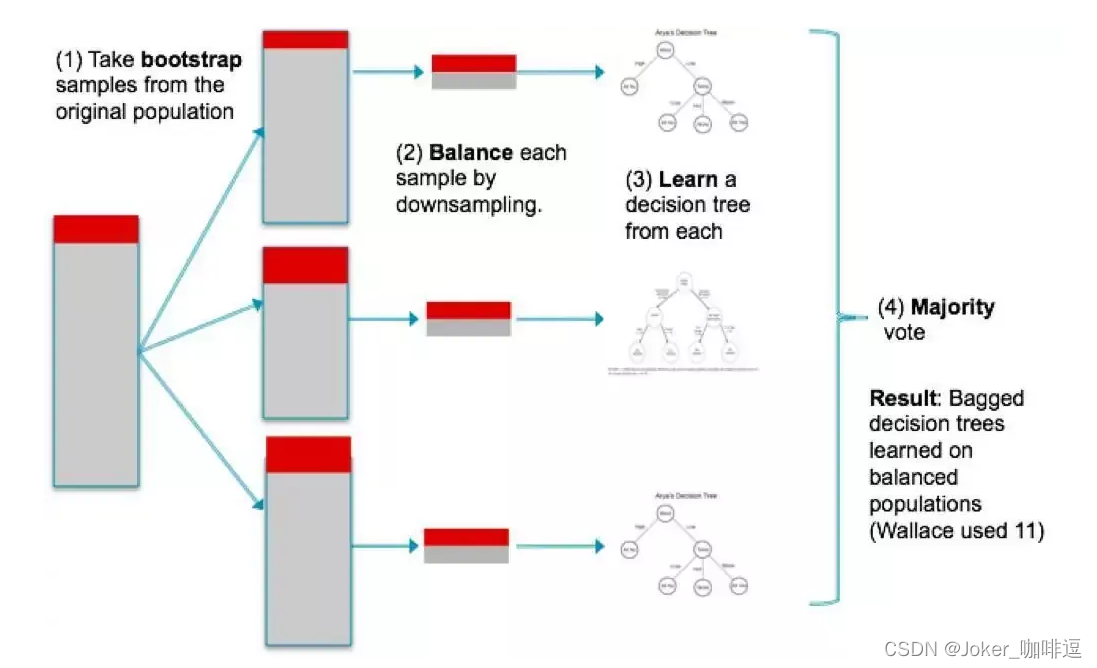
- 随机森林
- 随机:数据采样随机,特征选择随机;森林:很多决策树并行在一起
- 随机森林是对Bagging方法的改进,改进之处有两点:①基本学习器限定为决策树②引入了随机属性选择
- Bagging方法
Boosting方法
AdaBoost算法 :
对于Adaboost算法来说,先想想两个问题:① 每一轮如何改变训练数据的权值?
②如何将弱分类器组合成一个强分类器?答:
①AdaBoost的做法:提高被前一轮弱分类器分错样本的权值,降低被正确分类的权 值。以便,没有被分类正确的样本在下一轮收到更多关注。
②AdaBoost采取加权多数表决方法:加大误差率小的弱分类器的权值,减小误差率大的弱分类器的权值
总的来说:要降低分对样本的权值,提高分对(误差率小)的弱分类器的权值对于AdaBoost算法还有一个解释:
AdaBoost算法是 模型为加法模型、损失函数为指数损失函数、学习算法为向前分步算法 的二分类学习方法提升树算法:
- 以决策树为基函数的提升方法是提升树,是以分类树或回归树为基本分类器的提升方法。对分类问题决策树是分类二叉树,对回归问题决策树是回归二叉树。
- 提升方法:采用加法模型(基模型的线性组合)、向前分步算法
梯度提升树算法:
- 是对提升树算法的改进。提升树算法只适用于误差函数为指数函数和平方误差,而对于一般的损失函数,梯度提升算法可以将损失函数的负梯度在当前模型的值作为残差的近似值。
Stacking模型
- 特点:准确率可以达到很高,但速度可以很慢。(暴力刷结果,不择手段)
- 过程:
①将各种各样的训练好的基分类器分别对训练集预测
②将第 j 个基分类器对第 i 个训练样本的预测值作为新的训练集中的第 i 个样本的第 j 个特征值(即:将训练好的的基分类器作为新的训练集的特征值)
③最后基于新的模型进行预测
Voting
- 硬投票:对多个模型直接进行投票,少数服从多数。
- 软投票:原理和硬投票相同,只是给不同模型设定了不同权重,进而区别不同模型的重要程度。
版权声明:本文为m0_51370744原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。