clickhouse具有bitmap, 但只支持int, 实测表明groupBitmap()这个agg比直接的count(distinct x)计算要快至少一倍以上, 按之前druid中的测试
经验表明, 全局字典编码后的bitmap的查询性能也远远比普通bitmap好。
通过物化视图对bitmap构建groupBitmapState的中间存储状态, 通过预计算bitmap的并集能减少查询的开销。 并且物化视图的行数远比原始表行数
少, 除了bitmap以外的sum/max/min/avg等计算耗时也呈倍数下降
由于bitmap只支持int类型,所以uid,pid这类long类型的指标需要维护一个全局字典将long类型映射为int类型
流程
- 创建物化视图
CREATE MATERIALIZED VIEW atsplch_rpt.
ads_screen_unique_indicator_view_local on cluster cluster01
ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/{shard}
/atsplch_rpt/ads_screen_unique_indicator_view_local', '{replica}')
partition by dt
ORDER BY (indicator_id,city_id)
SETTINGS index_granularity = 10
POPULATE
AS SELECT
dt,
indicator_id,
city_id,
groupBitmapState(globalDict('pid_cn', indicator_value)) as
indicator_value_count,
maxState(parseDateTimeBestEffort(create_time)) as create_time
FROM atsplch_rpt.ads_screen_unique_indicator_local
GROUP BY dt,indicator_id,city_id;
- 实现globalDictGet(String dictName, UInt64 key)把long型转成int型
在物化视图中使用groupBitmapState(globalDict(‘pid_cn’, indicator_value)) as indicator_value_count构建bitmap - 构建全局字典的存储
在hbase中构建字典表, 比如dict_pid_cn和invert_pid_cn
dict_pid_cn的rowkey是long值, value是int值(全局字典id)
invert_pid_cn的rowkey是int值, value是long值
在每个clickhouse机器启动rocksdb作为字典表缓存, 同样建dict_pid_cn和invert_pid_cn两个表. 当rocksdb中查不到的
时候再去hbase中取或者插入hbase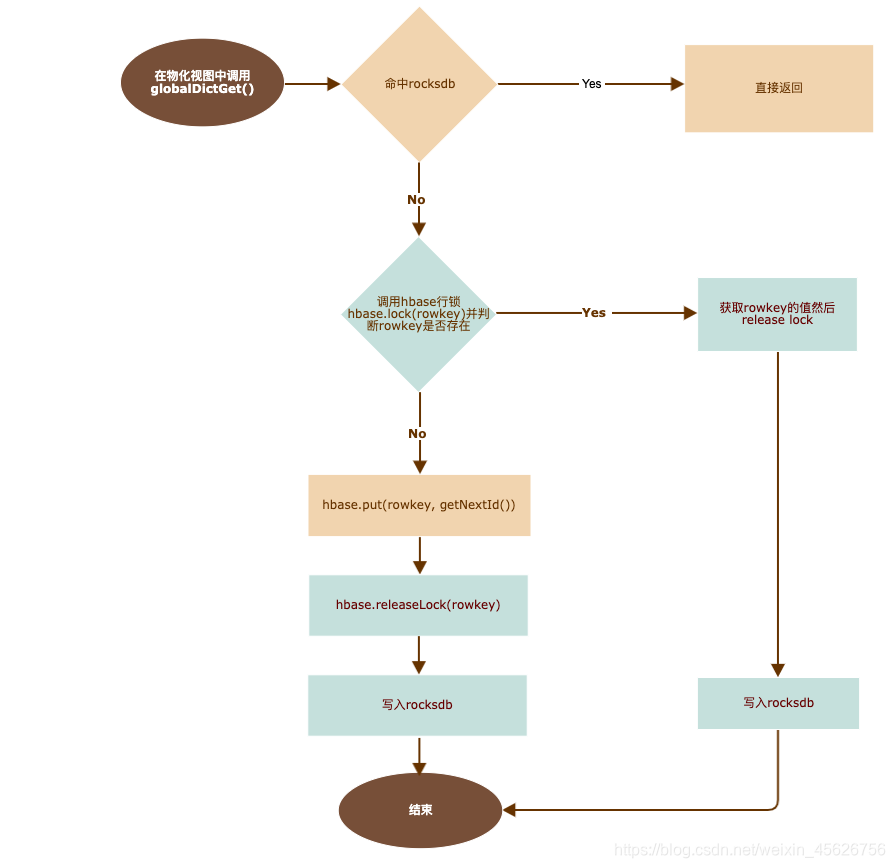
TIPS:
1)、看情况考虑是否使用本地的内存做lru cache
2)、第一次的时候从hive中把存量的值导入到hbase生成初始字典, hive的row_number()可以作为字典值
- 查询的时候使用bitmapCardinality(groupBitmapMerge(indicator_value_count))即是精确去重的值
- 实现globalInvertDictGet(String dictName, UInt32 dictId)从int型反查long, 用来把bitmap导出成array再反转成原始long型
在sql中bitmapToArray(arrayMap(x -> globalInvertDictGet('pid_cn', x)), groupBitmapMerge(indicator_value_count)))
getNextId()的实现
- 只在锁里被调用, 只在出现增量pid的时候被调用
- 只需要保证数据不丢并能够单调递增即可, 并不需要是分布式实现, 应以性能为优先
- 可选方式
redis,memcached
zk的全局counter
mysql+web
hbase的计数器
fusion的加锁的k/v
自定义实现方式
注意事项
- clickhouse扩容的时候新机器需要部署rocksdb并且初始化相关的字典数据
- 实现udf的时候需要注意矢量化或多线程访问rocksdb从而充分利用rocksdb性能
- 需要进行物化视图包含udf与不包含udf情况下的性能对比(物化视图构建延迟)
根据https://github.com/Terark/terarkdb/wiki/Benchmark-TPCH-TerarkDB-vs-RocksDB-B的性能测试表明, rocksdb的随机读为
970K/s/16核, 折合6w/s/core, 以1亿条构建计算需要100000000/60625/60 = 27.49分钟,以8线程访问rocksdb运行需要3.44分钟
官方测试https://github.com/facebook/rocksdb/wiki/Performance-Benchmarks 8核随机读为144737/s折合1.75w/s/core - rocksdb运行在clickhouse本机, 机器数量的限制将会成为物化视图构建的潜在瓶颈
潜在的性能点
使用https://github.com/Terark/terarkdb 代替rocksdb
随机读提升一倍, 以同上场景为例, 8线程需要1.72分钟以简单的rocksdb自同步作为集群, 代替hbase/fusion, 这样这个方案成为了依赖最少的自维护的形式
1)rocksdb存储全局递增id, 由选主的rocksdb生成并同步其他rocksdb
2)当主rocksdb挂掉的时候, 重新选为主的rocksdb需要确认最大的id, 或者类似的机制保证全局递增的id不会回退
3)扩容新机器的时候, 新的rocksdb能够同步到全量的数据不使用本地rocksdb, 使用远程rocksdb集群是否可行, 性能是否可行
不使用rocksdb, 直接使用远程fusion是否可行
潜在的故障点
- 访问hbase超时并反复重试失败
- 全局递增id失效
1)获取到后退了的id导致整体数据错误
2)服务失败, 无法获取到id, 与访问hbase失效同等效果
3)服务崩溃, 不可修复, 无法恢复最大id(需要从所有rocksdb中获取最大id, 重设后恢复id服务)