详细使用步骤介绍:
https://www.codenong.com/cs106623370/添加链接描述
Apache(音译为阿帕奇)是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。它快速、可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中。
下载地址:
https://github.com/nlplab/brat/releases/tag/v1.3p1
linux Centos7安装指南:
https://blog.csdn.net/u011440696/article/details/109364035添加链接描述
linux简单版安装指南:
https://www.jianshu.com/p/3a70ee9ad632添加链接描述
1.2如果你在osx或者linux系统上就可以直接按照下面安装
博主是放在一个服务器server上安装,然后通过访问ip的方式来完成标注工作。
一、
先下载,http://brat.nlplab.org/installation.html,brat-v1.3_Crunchy_Frog.tar.gz这个文件
然后解压,运行即可
二、
tar -xf brat-v1.3_Crunchy_Frog.tar
cd brat-v1.3_Crunchy_Frog
./install.sh –u
这里会提示你输入username,可以自己设置,将来标注的时候,支持多人标注。
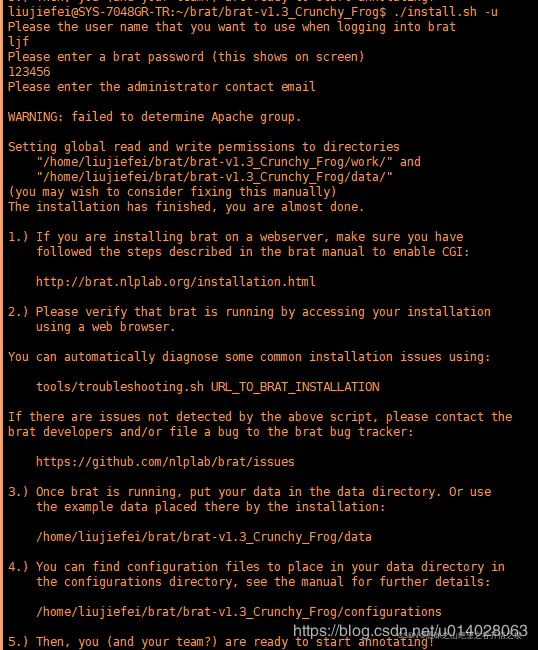
三、
brat本身是不支持中文的,如果在配置文件里定义中文会报错,解决办法是./server/src/projectconfig.py文件的第163行,加上中文支持即可:
def normalize_to_storage_form(t):
"""
Given a label, returns a form of the term that can be used for
disk storage. For example, space can be replaced with underscores
to allow use with space-separated formats.
"""
if t not in normalize_to_storage_form.__cache:
# conservative implementation: replace any space with
# underscore, replace unicode accented characters with
# non-accented equivalents, remove others, and finally replace
# all characters not in [a-zA-Z0-9_-] with underscores.
import re
import unicodedata
n = t.replace(" ", "_")
if isinstance(n, unicode):
ascii = unicodedata.normalize('NFKD', n).encode('ascii', 'ignore')
#n = re.sub(r'[^a-zA-Z0-9_-]', '_', n)
n = re.sub(u'[^a-zA-Z\u4e00-\u9fa5<>,0-9_-]', '_', n)
normalize_to_storage_form.__cache[t] = n
return normalize_to_storage_form.__cache[t]
normalize_to_storage_form.__cache = {}
四、
python standalone.py #(不可用python3)
打开待标注文件后,一定要先登录(右上方的login)
补充说明:
brat默认不支持中文标注,需要手动修改brat主目录/server/src路径下的projectconfig.py文件的第162行代码,注释源代码,然后另起一行加入新代码(修改之后记得重启apache2服务):
1
2
# n = re.sub(r'[^a-zA-Z0-9_-]', '_', n)
n = re.sub(u'[^a-zA-Z\u4e00-\u9fa5<>,0-9_-]', '_', n)
如果已经配置了支持中文,但是仍然报不支持的字符的问题,可能是你的配置里面有中文标点符号,要么全部改成英文标点,要么修改上面的正则,如下(修改之后记得重启apache2服务):
1
2
# n = re.sub(r'[^a-zA-Z0-9_-]', '_', n)
n = re.sub(u'[^a-zA-Z\u4e00-\u9fa5<>\u2014-\uff1b,0-9_-]', '_', n)
如果修改之后,仍然有字符问题,请检查配置文件的编码格式是否是UTF-8,且是标准的UTF-8,而不是带BOM的UTF-8,具体可以使用Notepad++打开文件再编码选项中查看和转换
五
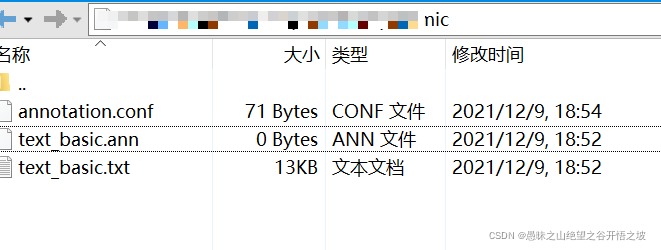
首先,在brat项目的data目录下新建一个project目录,然后在brat项目的主目录下找到以下文件,复制到project目录:
主目录:/var/www/html/brat
project目录:/var/www/html/brat/data/project
要复制的文件:
670a9144f3747d92fcf542851d8a4f64.png
我们来看一下这几个文件分别是做什么的。
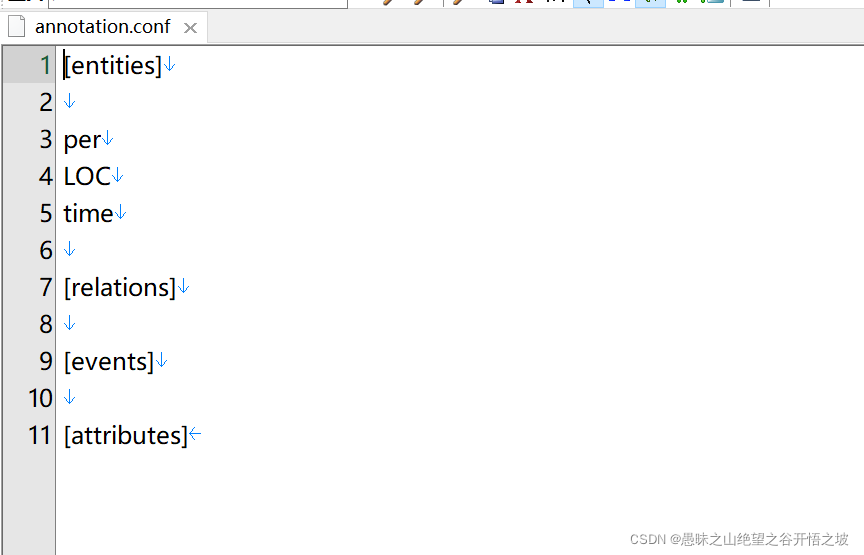
annotation.conf
这个是配置文件,内容如下:
复制代码
[entities]
Definition of entities.
Format is a simple list with one type per line.
时间
地点
人名
组织名
公司名
产品名
复制代码
visual.conf
这也是配置文件,可以配置不同的类别用不同的颜色显示,找到如下段落,更新内容:
复制代码
[drawing]
时间 bgColor:yellow
地点 bgColor:blue, fgColor:white
人名 bgColor:deepskyblue
组织名 bgColor:green, fgColor:white
公司名 bgColor:purple, fgColor:white
产品名 bgColor:pink
复制代码
mayun.txt
这是我们要标注的原文件,里面的内容片段如下(这里已经根据句号进行过分句处理,是因为不希望每个训练样本太长,建议控制在500字符内):
1964年9月10日,马云出生在杭州。
幼年的马云在人们的眼中是典型的坏孩子:叛逆、倔强、爱打架、逞强、顽皮淘气。
马云的父亲虽然是典型的江南人,但脾气却很火暴,马云从小在父亲拳脚下长大。
马云是看金庸的武侠小说长大的,行侠仗义、打抱不平的“侠义”情结在少年马云的内心深处早已生根、萌芽。
mayun.ann是一个空文件,使用brat对mayun.txt的标注结果,会记录在ann文件中。
此时我们通过浏览器访问brat项目界面,打开project目录下的mayun.txt文件(记得要先登录),看到的界面如下:
b2bd05f00704a32d3d80f7ec5de64a36.png
然后我们选择目标实体,比如“马云”,进行实体类别标注,效果如下:
ea0ececd21081d6b97b3558a5d2c6ea8.png
此时,你可以邀请其他人用他们的帐号登录brat,也打开这个txt,和你一起标注。
标注之后,再看看ann文件内容,如下:
2dc58df482a2a62efb150dd6b6e21ba0.png
T1,T2所在的列,表示标注的类型和序号,比如如果是标注的实体间的关系会用R表示,这里因为只讨论命名实体,不涉及实体间的关系,所以只要知道这个T表示什么就可以了;
人名,公司名所在列表示标注词汇的实体类别;
第三、四列是标注词汇在整个txt中的起始和(结束索引+1)
最后一列是就是标注的词汇列
7.添加用户
实现标注时,可以多个用户登录进行标注。
编辑文档:
vim /var/www/html/brat/config.py
1
修改对应的行,增加用户名和密码:
USER_PASSWORD = {
'admn': 'admin',
'test': 'test',
# (add USERNAME:PASSWORD pairs below this line.)
}
3.2 增加用户(这个一般不需要)
官方文档:If you want to add additional users, you can edit the config.py file, which contains further instructions.
找到config.py 对应的行,增加:
USER_PASSWORD = { 'admn': 'admin', 'test': 'test', # (add USERNAME:PASSWORD pairs below this line.) }
重新启动后,使用test就可以登录了
注意:当前用户只能针对自己的标注进行修改,并不能修改其他人进行的标注
https://www.jianshu.com/p/3a70ee9ad632
https://blog.csdn.net/u011440696/article/details/109364035
https://www.cnblogs.com/anai/p/11474460.html
https://www.i4k.xyz/article/XP1990/111604515
3.3 导入collection
导入文件的时候,必须要文件符合:文件名.xxx和文件名.ann 一一对应的格式即可
直接将包含txt数据集的文件夹放置到安装文件下一个data的目录下,然后使用命令:
find 文件夹名称 -name ‘*.txt’|sed -e ‘s|.txt|.ann|g’|xargs touch
其意思是对每个txt文件都创建一个空的标引文件.ann,因为BRAT是要求的collection中,每个txt文件是必须有一个对应的.ann文件的,方便放置标引内容,这个ann文件的格式也挺规范
将要标注的文件导入项目中data/路径下即可,可以查看其中examples文件下以及tutorials文件下帮助文档。
3.4具体标注配置
brat通过配置文件来决定对语料的标注可以满足何种任务,包括四个文件
annotation.conf: annotation type configuration
visual.conf: annotation display configuration
tools.conf: annotation tool configuration
kb_shortcuts.conf: keyboard shortcut tool configuration
一般只需要修改annotation.conf即可,该文件用于对标注的数据结构进行配置,典型的配置如下:
每个文件需要包含四类模块:entities、relations、events、attributes。各个模块都可以定义为空,其中
entities用来定义标注的实体名称,其格式为每行一个实体类型,比如:人名、地名、英雄名、技能名等,可以采用tab来增加二级标注,如下面的实体标注中技能下的二级标注战斗技能等。

relations用来定义实体间的关系,格式为每行定义一种关系,第一列为关系类型,随后是用逗号分隔的ArgN:实体名,用来表示关系的各个相关者。比如例子中,同盟关系是存在于英雄之间
events用来定义事件,每行定义一类事件,第一列为事件名,随后是用逗号分隔的Participant:实体名,用来表示事件的各个参与者。比如例子中,1v1事件需要多个英雄参加
attributes用来定义属性,每行一个属性,第一列为属性名,随后是用逗号分隔的Arg:<模块类型>, Value:属性值,注意属性值可以有多个,比如例子中,定义了实体类型可以有攻击力,值从1-3
[entities]
英雄
北欧英雄
希腊英雄
技能
战斗技能
生活技能
采矿
种地
种白菜
种大米
[relations]
同盟Arg1:英雄, Arg2:英雄
拥有Arg1:英雄, Arg2:技能
[events]
1v1Participant1:英雄, Participant2:英雄
[attributes]
攻击力Arg:, Value:1|2|3|4|5
选中要标注的文本,会弹出窗口,选中标注label,然后完成标注
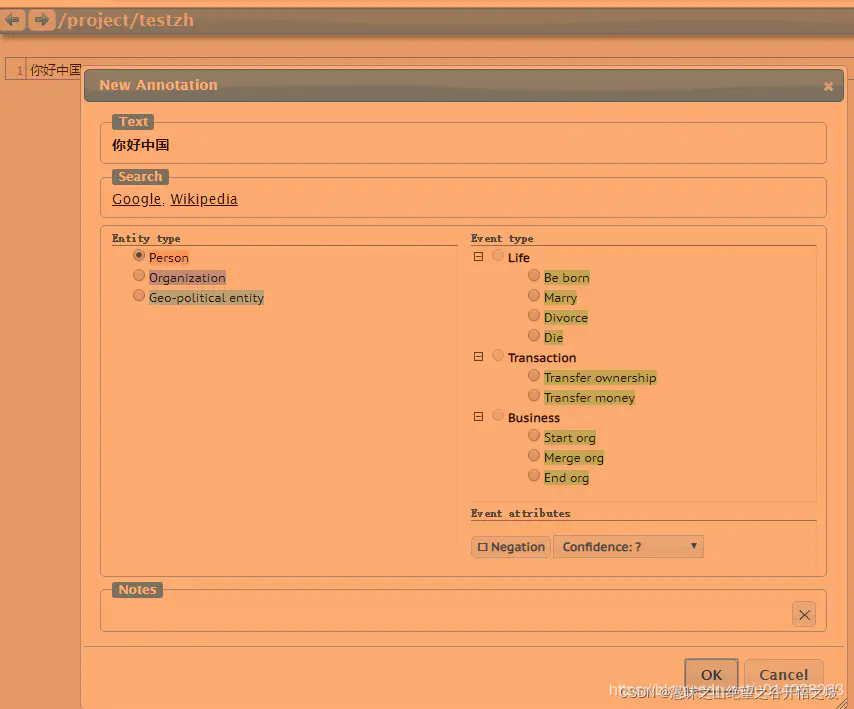
标注配置
annotation.conf
# 实体
[entities]
# 每行一个实体类型 ,每行开头TAB键可定义类的层级结构
# 在类型名称之前添加“!”来禁用实体选择对话框中的条目,即该类型将出现在结构的类型层次结构中,但无法选择。
Living-thing
Person
Animal
Plant
!Nonliving-thing
Building
Vehicle
# 关系
[relations]
# 基础语法 关系名称 Arg1:TYPE1,Arg2: TYPE2
Family Arg1:Person, Arg2:Person
Employment Arg1:Person, Arg2:Organization
# “|”分隔符列出所有可能的类型
Located Arg1:Person, Arg2:Building|City|Country
Located Arg1:Building, Arg2:City|Country
Located Arg1:City, Arg2:Country
# 通过<REL-TYPE>设置关系的symmetric(对称)和transitive(传递)属性,单独或同时使用均可。
# “symmetric-transitive”定义等价关系
Equiv Arg1:Person, Arg2:Person, <REL-TYPE>:symmetric-transitive
# 定义实体重叠的范围,
# 语法 <OVERLAP> Arg1:TYPE1, Arg2:TYPE2, <OVL-TYPE>:TYPE-SPEC
# TYPE-SPEC 可选值包括 contain, equal 和 cross。
# contain: TYPE1实体范围可包含(完全)TYPE2 实体范围
# equal: TYPE1和TYPE2实体的跨度可以相等
# cross: TYPE1和TYPE2实体的可以相交
<OVERLAP> Arg1:Country, Arg2:Organization, <OVL-TYPE>:contain
<OVERLAP> Arg1:Person, Arg2:Person, <OVL-TYPE>:equal
<OVERLAP> Arg1:<ENTITY>, Arg2:<ENTITY>, <OVL-TYPE>:<ANY>
# 事件
[events]
#语法 事件名称 参数名称:参数类型
Marriage Participant1:Person, Participant2:Person
Bankruptcy Org:Company
# 属性
[attributes]
# 名称 参数
age Arg:Person
Negation Arg:<EVENT>
Confidence Arg:<EVENT>, Value:Possible|Likely|Certain
#<ENTITY>:任何实体类型([entities]部分中出现的任何类型)
#<RELATION>:任何关系类型([relations]部分中出现的任何类型)
#<EVENT>:任何事件类型([events]部分中出现的任何类型)
#<ANY>:任何类型
视觉设置
visual.conf
[labels]
# 定义用户界面中标签类别的显示,如果未再此设置则按annotation.conf中的名称显示。
# 作用:再用户界面中用任意字符显示标签;界面空间有限时可使用缩写
# 第一个词应为annotation.conf中定义的类型
Organization | Organization | Org
Immaterial-thing | Immaterial thing | Immaterial | Immat
[drawing]
# 定义文本意外的视觉设置。
# 语法 ENTITY/RELATION KEY1:VALUE1,KEY2:VALUE2……
# KEY:VALUE对选项说明
# fgColor:任何HTML颜色规范(例如“black”),设置标注标签文字颜色。
# bgColor:任何HTML颜色规范(例如“white”),设置标注标签背景颜色。
# borderColor:任何HTML颜色规范(例如“black”),设置标注标签边框颜色。支持指定“ darken”设置阴影。
# color:任何HTML颜色规范(例如“black”),设置弧线的颜色。
# dashArray:设置为虚线。
Person bgColor:#ffccaa
Family fgColor:darkgreen
# <SPAN_DEFAULT>和<ARC_DEFAULT>用于定义未设置的标签和弧线默认样式。
SPAN_DEFAULT fgColor:black, bgColor:lightgreen, borderColor:darken
ARC_DEFAULT color:black, dashArray:-, arrowHead:triangle-5
#设置多值属性的显示,如在annotation.conf中设置了属性“Confidence Arg:<EVENT>, Value:L1|L2|L3”
Confidence glyph:(1)|(2)|(3), position:left
Confidence dashArray:-|3-3|3-6
工具配置
tools.conf
[options]
# 设置句子切分,分词,标注验证,和日志记录
# Tokens tokenizer:VALUE,其中VALUE=
# whitespace:按源文本中的空格字符分割(仅)
# ptblike:模拟Penn Treebank标记化
# mecab:使用MeCab执行日语标记化
# Sentences splitter:VALUE,其中VALUE=
# regex:基于正则表达式的句子拆分
# newline:由源文本中的换行符分隔(仅)
# Validation validate:VALUE,其中VALUE=
# all:执行完整验证
# none:不执行任何验证
# Annotation-log logfile:VALUE,其中VALUE=
# <NONE>:无注释记录
# NAME:登录到文件名(例如“ /home/brat/work/annotation.log”)
Tokens tokenizer:whitespace
Sentences splitter:regex
Validation validate:all
Annotation-log logfile:/home/brat/work/annotation.log
[normalization]
# BRAT使用SimString进行近似字符串匹配,配置normalization前需安装SimString,参照主页说明(http://chokkan.org/software/simstring/)
# 语法 DBNAME DB:DBPATH, <URL>:HOMEURL, <URLBASE>:ENTRYURL
# DBNAME:数据库名称,字符只能包含 大小写字母、数字、“-”、“_”
# DBPATH:可选项。相对于brat服务根目录的服务器上DB数据的文件系统路径。如果DBPATH未设置,则系统假定可以在给定的默认位置找到数据库DBNAME。
# HOMEURL:设置normalization资源的主页,用于标识资源DBNAME和在UI中提供链接以访问资源。
# URLBASE:可选项。设置URL模板,“%s”作为占位符可直接生成资源中改条目的链接。需要
Wiki DB:dbs/wiki, <URL>:http://en.wikipedia.org, <URLBASE>:http://en.wikipedia.org/?curid=%s
UniProt <URL>:http://www.uniprot.org/, <URLBASE>:http://www.uniprot.org/uniprot/%s
[search]
# 设置标注对话框中可用的搜索服务
Google <URL>:http://www.google.com/search?q=%s
Wikipedia <URL>:http://en.wikipedia.org/wiki/%s
[annotators]
# 设置可从BRAT调用的自动标注服务
SNER-CoNLL tool:Stanford_NER, model:CoNLL, <URL>:http://example.com:80/tagger/
[disambiguators]
# 设置可从BRAT调用的自动语义类别(标注类别)消歧服务
simsem-MUC tool:simsem, model:MUC, <URL>:http://example.com:80/simsem/%s
键盘快捷键配置
kb_shortcuts.conf
# 键 标注类型
P Person
O Organization
F Family

勾选这个,上传的字体会更加清晰。