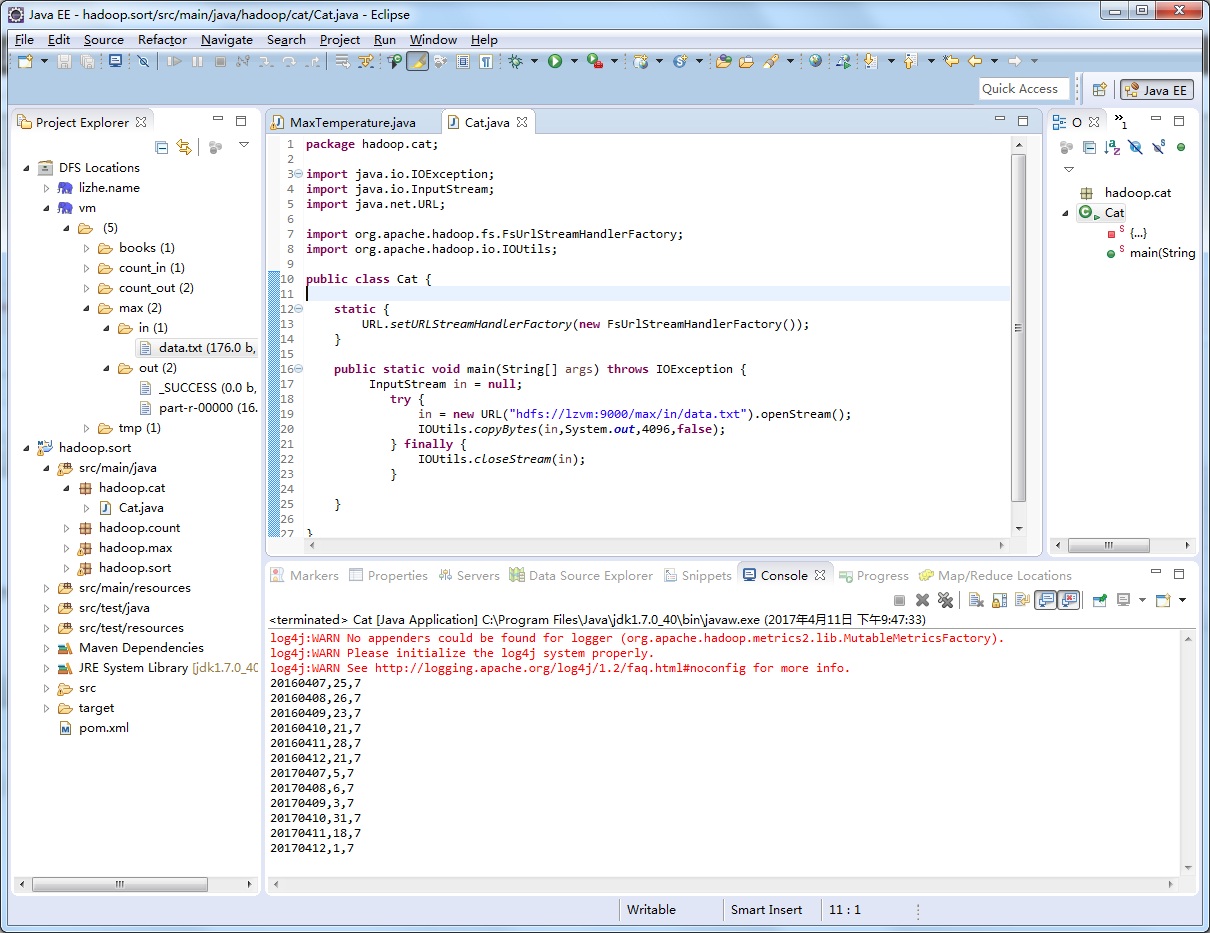
要从Hadoop文件系统读取文件,最简单的方法是使用java.net.URL对象打开数据流
不过使用这种方式需要先让虚拟机识别hadoop的URL数据流, 通过以下静态块实现
不过这种方式也有局限性, 每个java虚拟机只能调用一次这个方法, 因此通常在静态方法中调用
如果你醒目中的其他模块也需要使用这一方法,这种方式可能并不可取
package hadoop.cat;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class Cat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws IOException {
InputStream in = null;
try {
in = new URL("hdfs://lzvm:9000/max/in/data.txt").openStream();
IOUtils.copyBytes(in,System.out,4096,false);
} finally {
IOUtils.closeStream(in);
}
}
}
最后一个参数用于设置是否需要关闭输入流和输出流,因为这里System.out的输出流不需要关闭,而输入流in已经在finally块里手动关闭
所以设置成false
版权声明:本文为weixin_39688378原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。