降维
目的
数据压缩。从而使用较少的计算机内存或磁盘空间,并且让我们加快我们的学习算法。
例如:从二维降到一维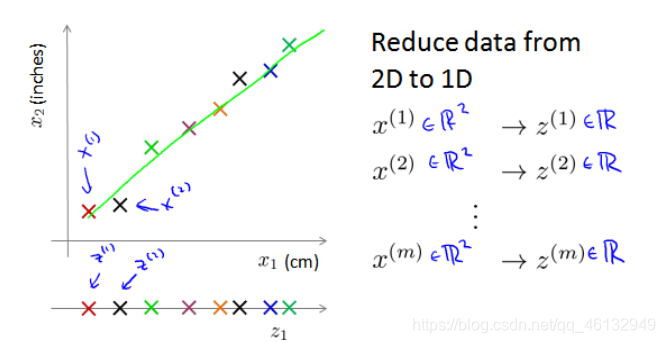
数据可视化。由于多为(例如50维)的数据是不可以进行可视化的,利用降维的方法把它降到2维或3维,就可以可视化了。这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
PCA算法
在 PCA 中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。
步骤:
- 均值归一化。我们需要计算出所有特征的均值,然后令 ?? = ?? − ??。如果特征是在不同的数量级上,我们还需要将其除以标准差 ?2。
- 是计算协方差矩阵(covariance matrix)?:
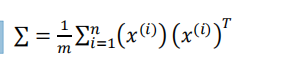
- 计算协方差矩阵?的特征向量
我们可以使用sklearn来实现
from sklearn import datasets
import sklearn.decomposition as sk_decomposition
iris=datasets.load_iris()
iris_X=iris.data
pca=sk_decomposition.PCA(n_components='mle',whiten=False,svd_solver='auto')
#n_components是降维后的特征数(维度)
#whiten:判断是否对降维后的每个数据进行归一化,让方差都为1
#svd_solver奇异值分解的方法,包括{'auto','full','arpack','randomized'}
pca.fit(iris_X)
reduced_X=pca.transform(iris_X)#降维后的数据
print(reduced_X)
print(pca.explained_variance_ratio_)#降维后的各主成分的方差值占总方差值的比例
print(pca.explained_variance_)#降维后的各主成分的方差值
print(pca.n_components)#降维后的特征数
选择主成分的数量

其中,分子为平均均方误差,分母为训练集的方差。我们希望在平均均方误差与训练集方差的比例尽可能小于0.01的情况下选择尽可能小的?值。这就意味着原本数据的偏差有 99%都保留下来了。我们可以从k=1开始,并逐渐增大k值来看上述比例是否小于0.1。
注意:主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
异常检测
原理:通过已有数据集根据所有的特征建立一个概率模型,用于新样本的预测,当新样本的概率小到一定程度时则认为出现异常。
高斯分布(正态分布)

算法

对于给定的数据集 ?(1), ?(2), . . . , ?(?),我们要针对每一个特征计算 ? 和 ?2 的估计值。一旦我们获得了平均值和方差的估计值,给定新的一个训练实例,根据模型计算 ?(?),当?(?) < ?时,为异常。
例:下图是一个由两个特征的训练集,以及特征的分布情况:
下面的三维图表表示的是密度估计函数,?轴为根据两个特征的值所估计?(?)值:
我们选择一个?,将?(?) = ?作为我们的判定边界,当?(?) > ?时预测数据为正常数据,否则为异常。
开发和评价一个异常检测系统
当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建?(?)函数
- 对交叉检验集,我们尝试使用不同的?值作为阀值,并预测数据是否异常,根据 F1 值或者查准率与查全率的比例来选择 ?
- 选出 ? 后,针对测试集进行预测,计算异常检验系统的?1值,或者查准率与查全率之比。

异常检测与监督学习对比

选择特征
- 如果数据的分布不是高斯分布,最好还是将数据转换成高斯分布

- 误差分析:分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
- 将一些相关的特征进行组合,来获得一些新的更好的特征。
多变量高斯分布
当两个变量呈现线性相关时,除了可以构造新的变量,还可以使用多变量高斯分布。
原理:在一般的高斯分布模型中,我们计算 ?(?) 的方法是: 通过分别计算每个特征对应的几率然后将其累乘起来,在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 ?(?)。
例:下图中是两个相关特征,洋红色的线(根据 ε 的不同其范围可大可小)是一般的高斯分布模型获得的判定边界,很明显绿色的 X 所代表的数据点很可能是异常值,但是其?(?)值却仍然在正常范围内。多元高斯分布将创建像图中蓝色曲线所示的判定边界。
我们首先计算所有特征的平均值,然后再计算协方差矩阵:



可见,我们可以通过调整协方差矩阵改变概率分布。
多元高斯分布模型与原高斯分布模型的关系:
可以证明的是,原本的高斯分布模型是多元高斯分布模型的一个子集,如果协方差矩阵只在对角线的单位上有非零的值时,即为原本的高斯分布模型了。
原高斯分布模型和多元高斯分布模型的比较:
m为样本数量,n为特征数量。