最近公司需要对一批图片进行文字识别,为了方便找到了python的第三方库cnocr来实现
cnocr 简介
一个面向中国ocr的python包,提供了经过训练的模型。 所以安装后可以直接使用。
当前crnn模型的精度约为98.8%。
用法
用法
第一次使用cnocr时,模型文件将自动从 Dropbox到~/.cnocr。
将提取zip文件,默认情况下,您可以在~/.cnocr/models中找到生成的模型文件。 如果自动下载无法正常运行,可以手动下载zip文件 从提取代码为ss81的Baidu NetDisk,并将zip文件放到~/.cnocr。代码可以做其他事情。
预测
提供了三种预测功能。
# 1.CnOcr.ocr(img_fp)
函数cnOcr.ocr (img_fp)可以识别包含多行(或单行)文本的图像中的文本。
输入参数img_fp:图像文件路径;或彩色图像mx.nd.NDArray或np.ndarray,形状为(height, width, 3),
通道应为rgb格式。
返回:List(List(Char)),例如:[['第', '一', '行'], ['第', '二', '行'], ['第', '三', '行']]。
使用案例
#第一种使用方法
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('examples/multi-line_cn1.png')
print("Predicted Chars:", res)
#第二种使用方法
import mxnet as mx
from cnocr import CnOcr
ocr = CnOcr()
img_fp = 'examples/multi-line_cn1.png'
img = mx.image.imread(img_fp, 1)
res = ocr.ocr(img)
print("Predicted Chars:", res)
识别的结果如下图:
安装使用
使用清华源安装 pip install cnocr -i https://pypi.tuna.tsinghua.edu.cn/simple
可能会遇到的问题
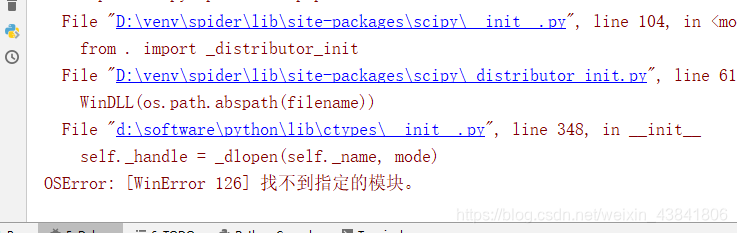
这个是因为我使用的虚拟环境中一些模块和安装的模块有冲突导致一直找不到库,
解决方法:
从新建一个虚拟环境进行安装使用

这个是它需要的依赖版本不匹配,但是不影响具体识别使用
官网地址 :https://www.cnpython.com/pypi/cnocr
版权声明:本文为weixin_43841806原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。