垃圾收集器
综述
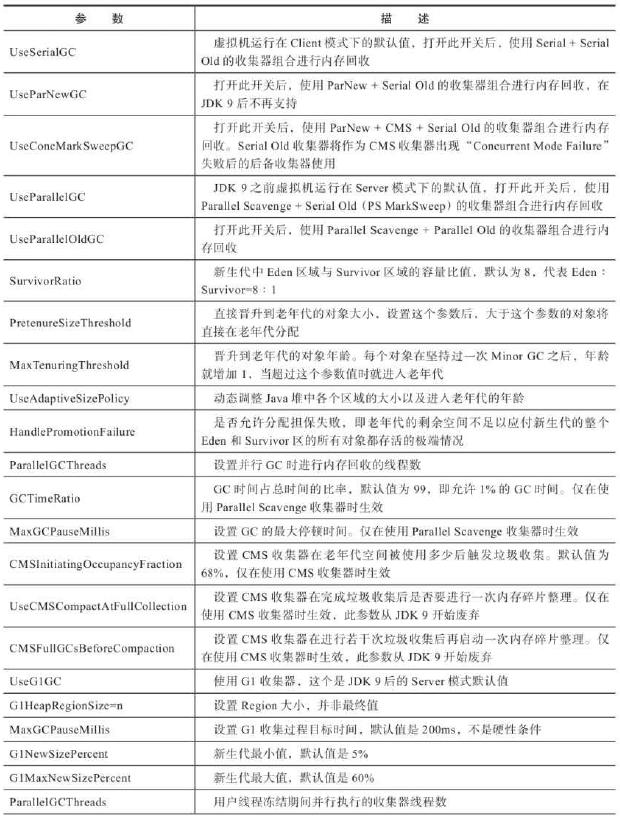
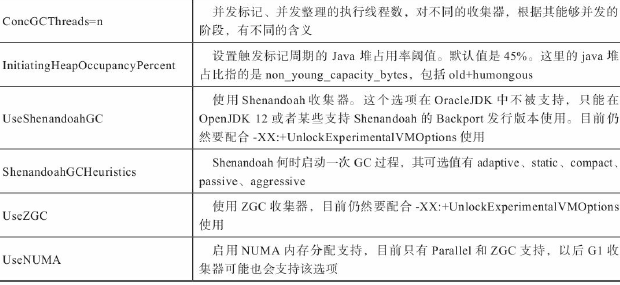
《Java虚拟机规范》中对垃圾收集器应该如何实现并没有做出任何规定,下图为作用在不同分代的收集器,连线表示可以搭配使用,连线中间的JDK9表示已经取消该组合
衡量垃圾收集器的三项最重要的指标是:内存占用(Footprint)、吞吐量(Throughput)和延迟(Latency)
新生代收集器
新生代收集器都采用的是标记-复制算法
Serial
单线程工作(指在GC时必须暂停其他线程,直到它收集结束),其简单高效,内存消耗小,适用于内存资源受限的环境,是HotSpot在Client模式下的默认收集器
ParNew
ParNew实际上是Serial的多线程并行版本,除了同时使用多线程进行gc外,其他都一样,在JDK7之前首选的新生代收集器(原因之一是其可以和CMS配合)
Parallel Scavenge
类似ParNew,也是并行收集,其目标是达到一个可控制的吞吐量(运行用户代码时间与处理器消耗时间之比)
- 停顿时间越短,越适合需要与用户交互或需要保证服务响应质量的程序
- 吞吐量越高,可高效率地利用CPU资源,尽快完成程序的运算任务,适合在后台运算而不需要太多交互的分析任务
Parallel Scavenge可通过
- -XX:MaxGCPauseMillis:控制最大gc停顿时间
- -XX:GCTimeRatio:垃圾收集时间占总时间的比率,相当于吞吐量的倒数,默认为99,即最大允许1%[1/(1+99)]的gc时间
- -XX:+UseAdaptiveSizePolicy:根据系统运行情况动态调整新生代、老年代等以提供最合适的停顿时间或最大吞吐量
老年代收集器
Serial Old和Parallel Old采用标记-整理,CMS采用标记-清除
Serial Old
Serial Old是Serial老年代版本,同样是单线程,主要也是用于Client模式下的虚拟机
在Serve模式下,与Parallel Scavenge搭配,或作为CMS发生Concurrent Mode Failure时的后背预案
Parallel Scavenge收集器架构中本身有PS MarkSweep收集器来进行老年代收集,其和Serial Old几乎一样
Parallel Old
Parallel Old是Parallel Scavenge收集器的老年代版本,支持多线程并发收集
CMS
实现了让垃圾收集线程与用户线程同时工作,目标是获取最短回收停顿时间,运作过程分为四个步骤
- 初始标记:Stop The World,标记GC Roots能直接关联的对象
- 并发标记:遍历对象引用链,可并发进行
- 重新标记:Stop The World,修正在并发标记期间产生变动的对象
- 并发清除:清除删除标记对象,无需移动对象,可并发进行
其缺点有
- 并发阶段虽然不会Stop The World,但会占用线程导致应用变慢,默认启动的回收线程数为(CPU核心数+3)/4,核心越少影响越大
- 无法处理浮动垃圾,并发过程产生的垃圾只能在下次收集
- 不能等老年代快满了再收集,需预留内存(-XX:CMSInitiatingOccupancyFraction)用于程序的并发运行
- 预留内存不足以分配新对象时,会出现Concurrent Mode Failure,此时需Stop The World,启动Serial Old进行老年代收集
CMS基于标记-清除会导致大量碎片,当内存不足以分配大对象时不得不提前触发Full GC
- -XX:+UseCMSCompactAtFullCollection:设置Full GC时是否启动内存碎片整理(无法并发),默认开启
- -XX:CMSFullGCsBeforeCompaction:第n+1次Full GC前会先进行碎片整理(默认为0每次进入Full GC都整理)
全堆收集器G1
在JDK 9 取代Parallel Scavenge+Parallel Old,成为Server模式下的默认收集器,开创了面向局部收集设计思路和基于Region的内存布局形式
- 将堆分为大小相等的Region(-XX:G1HeapRegionSize)
- Region可扮演新生代的Eden、Survivor或老年代
- Humongous用来存储超过Region容量一半的对象,超过整个Region容量的对象放在N个连续的Humongous
- 用优先级列表记录Region的垃圾价值(即回收所获得的空间大小以及回收所需时间的经验值)
- 根据信息统计衰减均值,在停顿时间(-XX:MaxGCPauseMillis,默
认200毫秒)优先处理回收价值收益最大的Region - 跨Region引用存储在各自的哈希卡表,key为别的Region起始地址,Value为卡表索引号集合
- 采用原始快照(SATB)保证并发
- 用两个TAMS指针记录并发时的内存分配地址,若回收速度赶不上分配速度,需要Stop The World及Full GC
G1的运行过程分为4个步骤:
- 初始标记:Stop The World(与Minor GC同步),标记GC Roots直接关联的对象,修改TAMS
- 并发标记:遍历对象引用链,将并发时变动的对象记录到SATB
- 最终标记:Stop The World,处理SATB
- 筛选回收:Stop The World,更新Region统计信息,计算价值,根据停顿时间选择回收集,用复制算法回收,不会产生内存碎片
低延迟收集器
可在任意可管理的堆容量下,实现垃圾收集的停顿不超过十毫米
Shenandoah
Shenandoah只包含在OpenJDK中,很多地方都类似与G1,除了以下
- 支持并发的整理算法
- 默认不使用分代收集
- 用连接矩阵代替记忆集,其是二维表格,若Region N有
对象指向Region M,就在表格的N行M列中打上一个标记
运行过程分为9个步骤:
- 初始标记:Stop The World,标记GC Roots直接关联的对象
- 并发标记:遍历对象引用链,将并发时变动的对象记录到SATB
- 最终标记:Stop The World,处理SATB,选择回收集
- 并发清理:清理无任何存活对象的Region
- 并发回收:将回收集存活对象复制到空Region,通过读屏障和Brooks Pointer转发地址解决并发移动
- 初始引用更新:Stop The World,建立线程集合点,确保对象移动已完成
- 并发引用更新:将堆中旧地址修改为移动后的新地址,无需搜索引用链,按照地址线性搜索
- 最终引用更新:Stop The World,修正GC Roots中的引用
- 并发清理:清理回收集的Region
Brooks Pointer在原有对象结构最前面新增引用字段,在不处于并发移动时指向自己,移动时只需要修改该指针
Brooks Pointer在并发写入可能导致写到旧对象,需采用CAS(Compare And Swap)进行同步
ZGC
基于Region内存布局,不设分代(无跨代引用),使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-整理算法
ZGC的Region具有动态创建和销毁,以及动态容量
- 小型Region:2MB,存放小于256KB的对象
- 中性Region:32MB,存放大于等256KB但小于4MB的对象
- 大小Region:动态容量,为2MB的整数倍,存放4MB及以上的对象,只会存放一个,不会重分配
染色指针将信息记录在引用对象的指针上,将64位地址的第19-22位用于存储四个标志信息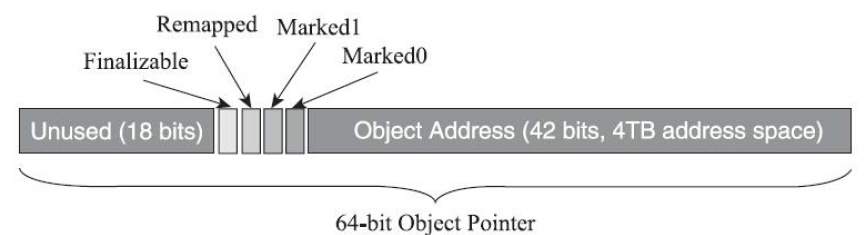
表示其引用对象的三色标记状态、是否进入重分配集(即被移动过)、是否只能通过finalize()访问到,但导致ZGC能够管理的内存不可以超过4TB(242)
染色指针的好处有:
- Region的存活对象被移走后,该Region可立即释放和重用(因为指针自愈),而不必等所有指向该Region的引用都被修正后才能清理
- 减少内存屏障的使用,将记录对象引用变动的写屏障维护到指针中
- 可扩展存储其他信息进一步提高性能
- 实际系统中的地址位是不可随意更改的,需采用多重映射将染色指针转为实际地址
运行分为四个步骤,都可并发,两个阶段中间会存在Stop The World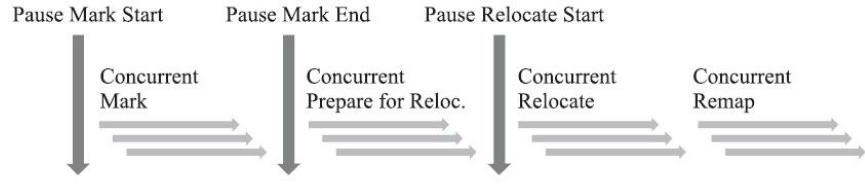
- 并发标记:遍历引用链,更新染色指针中的Marked 0、Marked 1
- 并发预备重分配:将要清理的Region组成重分配集(需扫描所有Region)
- 并发重分配:把重分配集的存活对象复制到新Region,为其中的每个Region维护一个转发表,记录旧对象到新对象的转向关系(指针自愈:若出现并发访问,会被截获并转发到新复制的对象,并修正该引用的值)
- 并发重映射:修正堆中指向重分配集中旧对象的所有引用,并释放重分配表(此步骤合并到并发标记节省一次遍历)
因为ZGC目前不分代,且每次收集扫描所以Region,当收集速度跟不上分配速度时,也会导致错误,解决办法是尽可能增大堆容量(或采用分代)
ZGC支持NUMA(Non-
Uniform Memory Access,非统一内存访问架构),会优先在当前处理器内存上分配对象,避免跨处理器,以保证效率
不收集垃圾——Epsilon
Epsilon不回收垃圾,运行负载极小,适用于只需要短时间运行,在堆耗尽之前退出的应用
收集器的权衡
- 若是数据分析、科学计算类的任务,目标是能尽快算出结果,则关注吞吐量
- 若停顿时间直接影响服务质量,严重的甚至会导致事务超时,则关注延迟
- 还需考虑软硬件、操作系统、CPU、内存、JDK版本及其发行商等
垃圾收集器日志
统一日志框架——Xlog
JDK9之前没有同一框架,日志开关由不同参数决定,JDK 9 后归纳到
-Xlog[:[selector][:[output][:[decorators][:output-options]]]]
selector由Tag和Level组成,可选值为
Tag:gc,add,age,alloc,annotation,aot,arguments,attach,barrier,biasedlocking,blocks,bot,breakpoint,bytecode
Level:Trace,Debug,Info,Warning,Error,Off
decorators可附加日志输出内容,默认为update、level、tags
- time:当前日期和时间
- uptime:虚拟机启动到现在经过秒数
- timemillis:当前时间的毫秒数
- uptimemillis:虚拟机启动到现在经过的毫秒数
- timenanos:当前时间的纳秒数
- uptimenanos:虚拟机启动到现在经过的纳秒数
- pid:进程ID
- tid:线程ID
- level:日志级别
- tags:日志输出的标签集
基本日志命令(JDK9之前和之后)
查看GC基本信息
-XX: +PrintGC
-Xlog: gc
查看gc详细信息
-XX: +PrintGCDetails
-Xlog: gc*
查看gc前后堆、方法区可用容量变化
-XX: +PrintHeapAtGC
-Xlog: gc+heap=debug
查看gc过程中用户线程并发时间以及停顿的时间
-XX: +PrintGCApplicationConcurrentTime -XX: +PrintGCApplicationStoppedTime
-Xlog: safepoint
查看收集器Ergonomics机制(自动设置堆空间各分代区域大小、收集目标等内容,从Parallel收集器开始支持)自动调节的相关信息
-XX:+PrintAdaptiveSizePolicy
-Xlog:gc+ergo*=trace
查看熬过收集后剩余对象的年龄分布信息
-XX:+PrintTenuringDistribution
-Xlog:gc+age=trace
其他JDK9前后命令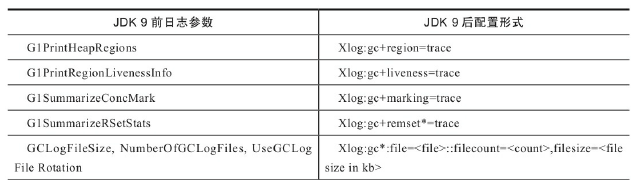

其他