web请求流程:浏览器发送请求的处理
万维网工作方式
万维网是以客户服务器方式工作的。
浏览器就是在用户主机上的万维网客户端程序。
万维网文档所驻留的主机则运行服务器程序,因此这台主机也称为万维网服务器。
客户程序向服务器发送请求,服务器程序向客户端程序送回客户所要的万维网文档。
在一个客户程序主窗口上显示出的万维网文档称之为页面。
怎么标志分布在整个互联网上的万维网文档
万维网使用统一资源定位符URL来标志万维网上的各种文档,并使每一个文档在互联网的范围内具有唯一标识符URL。
URL是什么:
URL,统一资源定位符,是Internet上标准资源的地址,指示资源的位置和用于访问它的协议。
互联网上的每个文件都有一个唯一的 URL。也就是平常说的web网址。
统一资源定位符(URL)是统一资源标识符(URI)的一个下种,统一资源标识符确定一个资源,统一资源定位符不但确定资源还表示出它在哪里。
URL包含以下信息:
- 用于访问的协议
- 服务器的地址(IP地址或者域名)
- 服务器上的端口号
- 资源在服务器目录结构中的位置
- 片段标识符(可选)
<协议>://<主机>:<端口>/<路径>
这里的协议是指使用什么协议来获取该万维网文档。常见的协议是http(超文本传输协议HTTP),其次是ftp(文件传输协议FTP)
在<协议>后面的“?/”是固定的格式。
<主机>指出这个万维网文档在哪一台主机上,这里的<主机>是指该主机在互联网上的域名。
URL里面的字母不区分大小写。
使用HTTP的URL
使用的最多的一种URL。
http://<主机>:<端口>/<路径>
HTTP的默认端口号是80,通常可以忽略。如果忽略<路径>选项,则URL指到互联网上的某个主页。
HTTP相关信息可以参考文档:https://blog.csdn.net/fkaifk522/article/details/106080739
什么是主页
主页可以是以下几种情况之一:
- 一个WWW服务器的最高级别的页面;
- 某一个组织或者部门的一个定制的页面或者目录,从这样的页面可以链接到互联网上的与本组织或部门有关的其他站点;
- 由一个人自己设计的描述他本人情况的WWW页面。
浏览器上网的基本原理
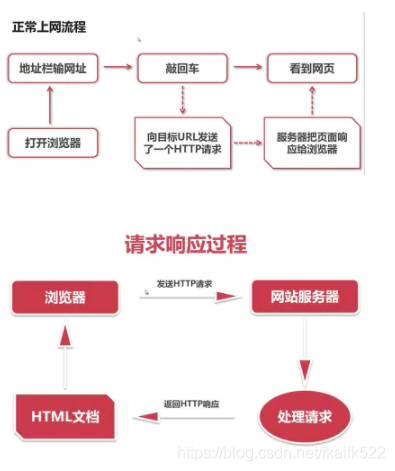
HTML文件是被网络浏览器读取,产生网页的文件。
web请求处理流程图
关于B/S架构相关内容可以查看文档《B/S结构和C/S架构》
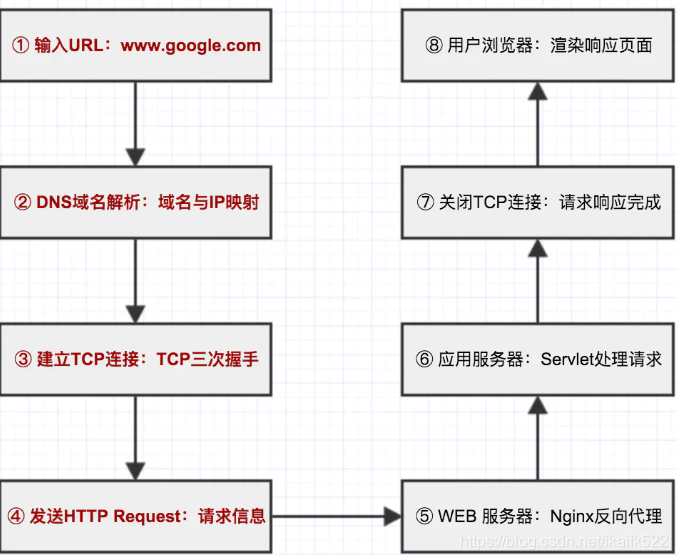
- 浏览器输入URL后回车;
- 浏览器请求DNS把这个域名解析成对应的IP地址;
- 根据IP地址在互联网上找到对应的服务器,建立socket连接,(http是要基于TCP连接基础上的,简单的说,TCP就是单纯建立连接,不涉及任何我们需要请求的实际数据,简单的传输。http是用来收发数据,即实际应用上来的。)
- 客户端进程向这个服务器发起一个HTTP Get请求(HTTP Request请求包);由这个服务器收到请求包,处理请求包,决定返回默认的数据资源给访问的用户,即HTTP Response响应包;
- 在服务器端实际上服务器可能有多台,这时候就需要负载均衡设备来平均分配所有用户的请求;
- 请求的数据存储的位置有多种,分布式缓存或者静态文件或者数据库。
- 当数据返回到浏览器时,浏览器开始渲染这个Response包里的主体(body),解析数据发现还有一些静态资源时又会发送另外的HTTP请求,这些请求会在CDN上,CDM服务器又会处理这个用户的请求。
- 等收到全部内容后断开与该服务器之间的TCP连接。由客户端解释HTML文档,在客户端屏幕上渲染图形结果;
版权声明:本文为fkaifk522原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。