一、基础语法
1、Scala与Java的关系
- Scala是基于Java虚拟机,也就是JVM的一门编程语言
- 所以Scala的代码,都必须经过编译为字节码,然后交由Java虚拟机运行
- Scala和Java是可以无缝操作的,Scala可以任意调用Java的代码
2、安装
- 官方下载: http://www.scala-lang.org/download/
- 在windows命令行内即可直接键入scala,打开scala命令行,进行scala编程。

3、解释器
- REPL: Read(取值)->Evaluation(求值)->Print(打印)->Loop(循环)。
Scala解释器也被称为REPL,会快速编译Scala代码为字节码,然后交给JVM执行。 - 计算表达式: 在Scala>命令行内,键入Scala代码,解释器会直接返回结果,如果没有指定变量来存放这个值,默认值为res,而且会显示结果的数据类型,比如Int、Double、String等。
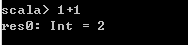
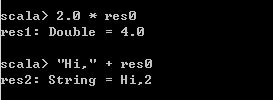
- 内置变量: 在后面可以继续使用res这个变量,以及它存放的值。
- 自动补全: Tab键
4、声明变量
1)val变量(常量)
可以声明变量用来存放表达式的计算结果,值无法改变,但是可以继续使用
2)var变量(变量)
声明变量,值可以改变,通常不建议使用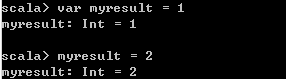
在Java的大型复杂系统的设计和开发中,也使用了类似的特性,我们通常会将传递给其他模块 / 组件 / 服务的对象,设计成不可变类(Immutable Class)。在里面也会使用java的常量定义,比如final,阻止变量的值被改变。从而提高系统的健壮性(robust,鲁棒性)和安全性。
3)指定类型
声明变量可以手动指定类型,如果不指定会自动根据值进行类的推断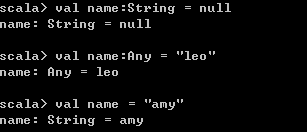
4)声明多个变量
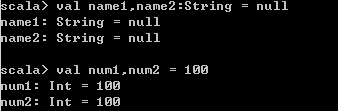
5、数据类型与操作符
1)基本数据类型
Byte、Char、Short、Int、Long、Float、Double、Boolean
- Scala与Java的基本数据类型大致相同,但是没有基本数据类型与包装类型的概念,统一都是类。
- Scala自己会负责基本数据类型和引用类型的转换操作
- 使用以上类型,直接就可以调用大量函数
2)类型的加强板类型
- Scala类使用很多加强类给数据类型增加了上百种增强的功能或函数。
- String类通过StringOps类增强了大量的函数
#例:取相同的字母
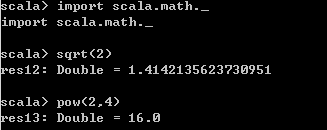
- Scala还提供了RichInt、RichDouble、RichChar等类型,RichInt就提供了to函数,1.to(10),此处Int先隐式转换为RichInt,然后再调用其to函数
3)基本操作符
- scala的算术操作符与java的算术操作符也没有什么区别,比如+、-、*、/、%等,以及&、|、^、>>、<<等。
- 但是,在scala中,这些操作符其实是数据类型的函数,比如1 + 1,可以写做1.+(1)
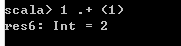
- scala中没有提供++、–操作符,我们只能使用+和-,比如counter = 1,counter++是错误的,必须写做counter += 1.
6、函数调用与apply()函数
1)函数调用方式
如果调用时,不需要传递参数,则Scala允许调用时省略括号
2)apply函数
- Scala中的apply函数是非常特殊的一种函数,在Scala的object中,可以声明apply函数。而使用“类名()”的形式,其实就是“类名.apply()”的一种缩写。通常使用这种方式来构造类的对象,而不是使用“new 类名()”的方式。
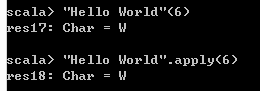
- 例如,“Hello World”(6),因为在StringOps类中有def apply(n: Int): Char的函数定义,所以"Hello World"(6),实际上是"Hello World".apply(6)的缩写。
- 例如,Array(1, 2, 3, 4),实际上是用Array object的apply()函数来创建Array类的实例,也就是一个数组。
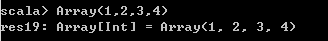
二、条件控制与循环
1、if表达式
1)定义
在Scala中,if表达式是有值的,就是if或者else中最后一行语句返回的值。
- 例如,val age = 30; if (age > 18) 1 else 0

- 可以将if表达式赋予一个变量,例如,val isAdult = if (age > 18) 1 else 0

- 另外一种写法,var isAdult = -1; if(age > 18) isAdult = 1 else isAdult = 0,但是通常使用上一种写法

2)if表达式的类型推断
由于if表达式是有值的,而if和else子句的值类型可能不同,此时Scala会自动进行推断,取两个类型的公共父类型。
- 表达式的类型是Int,因为1和0都是Int

- if和else的值分别是String和Int,则表达式的值是Any,Any是String和Int的公共父类型

- 如果if后面没有跟else,则默认else的值是Unit,也用()表示,类似于java中的void或者null

3)将if语句放在多行中
默认情况下,REPL只能解释一行语句,但是if表达式通常需要放在多行。
可以使用{}的方式,或者使用:paste和ctrl+D的方式。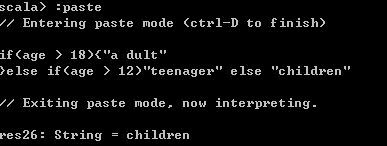
2、语句终结符、块表达式
默认情况下,scala不需要语句终结符,默认将每一行作为一个语句
1)一行放多条语句
如果一行要放多条语句,则必须使用语句终结符
#例:使用分号作为语句终结符
#通常来说,对于多行语句,还是会使用花括号的方式
2)块表达式
指的就是{}中的值,其中可以包含多条语句,最后一个语句的值就是块表达式的返回值。
3、输入和输出
1)print和println
print打印时不会加换行符,而println打印时会加一个换行符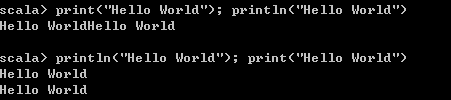
2)printf
格式化
3)readLine
从控制台读取用户输入的数据,类似于java中的System.in和Scanner
4)综合案例
游戏厅门禁
4、循环
1)while do 循环
基本语义与Java相同
2)Scala没有for循环,只能使用while替代for循环,或者使用简易版的for语句
- 简易版for语句

- until,表达式不达到上限

- 对字符串进行遍历,类似于Java的增强for循环

3)跳出循环语句
scala没有提供类似于java的break语句,但是可以使用boolean类型变量、return或者Breaks的break函数来替代使用。
5、高级for循环
1)多重for循环
九九乘法表
2)if守卫:取偶数

3)for推导式:构造集合

三、函数入门
1、函数的定义与调用
在Scala中定义函数时,需要定义函数的函数名、参数、函数体
Scala要求必须给出所有参数的类型,但是不一定给出函数返回值的类型,只要右侧的函数体中不包含递归的语句,Scala就可以自己根据右侧的表达式推断出返回类型。
2、在代码块中定义包含多行语句的函数体
单行的函数:
如果函数体中有多行代码,则可以使用代码块的方式包裹多行代码,代码块中最后一行的返回值就是整个函数的返回值。与Java中不同,不是以return为返回值。
#累加功能:
3、递归函数与返回类型
如果在函数体内递归调用函数自身,则必须手动给出函数的返回类型
#例:斐波那契数列:9 + 8; 8 + 7 + 7 + 6; 7 + 6 + 6 + 5 + 6 + 5 + 5 + 4; …
4、参数
1)默认参数
在Scala中,有时我们调用某些函数时,不希望给出参数的具体值,而希望使用参数自身默认的值,此时就定义在定义函数时使用默认参数。
如果给出的参数不够,则会从左往右依次应用参数。
Java与Scala实现默认参数的区别
Java
public void sayHello(String name, int age) {
if(name == null) {
name = "defaultName"
}
if(age == 0) {
age = 18
}
}
sayHello(null, 0)
Scala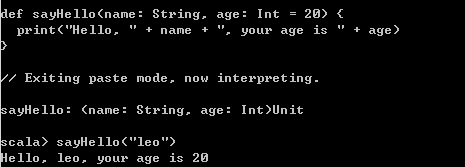
2)带名参数
在调用函数时,也可以不按照函数定义的参数顺序来传递参数,而是使用带名参数的方式来传递。
3)变长参数
在Scala中,有时我们需要将函数定义为参数个数可变的形式,则此时可以使用变长参数定义函数。
使用序列调用变长参数
- 不能将一个已有的序列直接调用变长参数
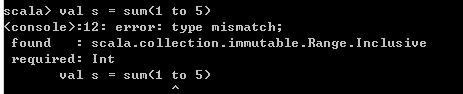
- 需要使用Scala特殊的语法将参数定义为序列,让Scala解释器能够识别

案例:使用递归函数实现累加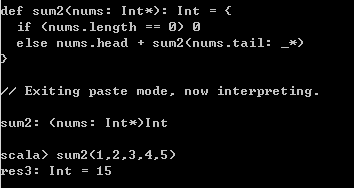
5、过程
在Scala中,定义函数时,如果函数体直接包裹在了花括号里面,而没有使用=连接,则函数的返回值类型就是Unit。这样的函数就被称之为过程。
- 过程通常用于不需要返回值的函数。
- 过程还有一种写法,就是将函数的返回值类型定义为Unit。
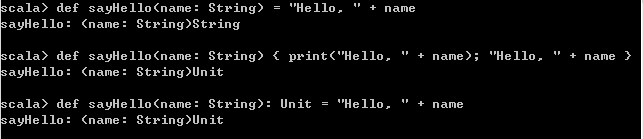
6、lazy值
如果将一个变量声明为lazy,则只有在第一次使用该变量时,变量对应的表达式才会发生计算。这种特性对于特别耗时的计算操作特别有用,比如打开文件进行IO,进行网络IO等。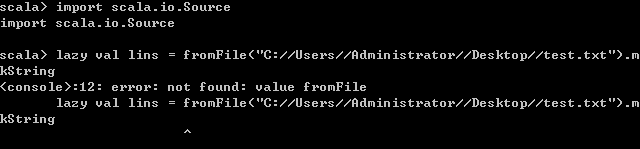
- 即使文件不存在,也不会报错,只有第一个使用变量时会报错,证明了表达式计算的lazy特性。
7、异常
异常处理和捕获机制与Java非常相似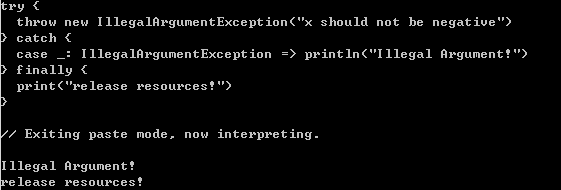
四、数组
1、Array
- 是长度不可改变的数组
- scala和Java都运行在JVM中,双方可以相互调用,因此scala数组底层实际上是Java数组
- 字符串数组在底层就是Java的String[],整数数组在底层就是Java的Int[]
// 数组初始化后,长度就固定下来了,而且元素全部根据其类型初始化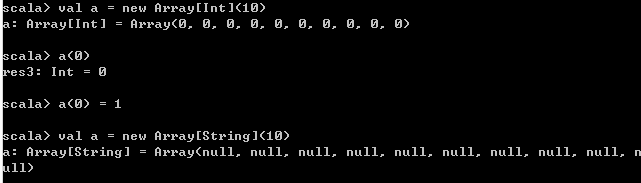
// 可以直接使用Array()创建数组,元素类型自动推断
//可以类型不同
2、ArrayBuffer
- 类似于Java中的ArrayList这种长度可变的集合类
// 如果不想每次都使用全限定名,则可以预先导入ArrayBuffer类
// 使用ArrayBuffer()的方式可以创建一个空的ArrayBuffer
// 使用+=操作符,可以添加一个元素,或者多个元素
// 这个语法必须要谨记在心!因为spark源码里大量使用了这种集合操作语法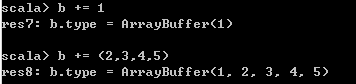
// 使用++=操作符,可以添加其他集合中的所有元素
// 使用trimEnd()函数,可以从尾部截断指定个数的元素
// 使用insert()函数可以在指定位置插入元素
// 但是这种操作效率很低,因为需要移动指定位置后的所有元素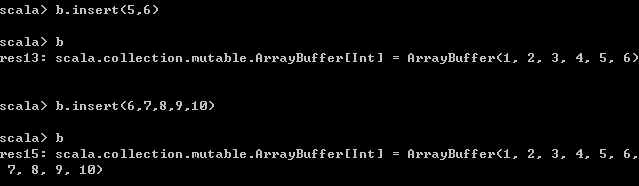
// 使用remove()函数可以移除指定位置的元素
//删除角标是1到3的元素
// Array与ArrayBuffer可以互相进行转换
3、遍历Array和ArrayBuffer
// 使用for循环和until遍历Array / ArrayBuffer
// 使until是RichInt提供的函数
// 跳跃遍历Array / ArrayBuffer
// 从尾部遍历Array / ArrayBuffer
// 使用“增强for循环”遍历Array / ArrayBuffer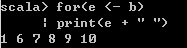
4、数组常见操作
// 数组元素求和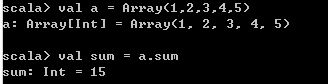
// 获取数组最大值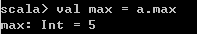
// 对数组进行排序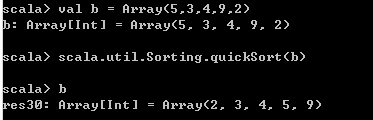
// 获取数组中所有元素内容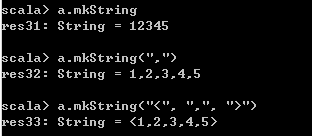
// toString函数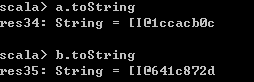
5、使用yield和函数式编程转换数组
// 对Array进行转换,获取的还是Array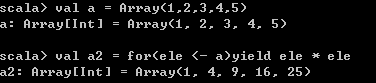
// 对ArrayBuffer进行转换,获取的还是ArrayBuffer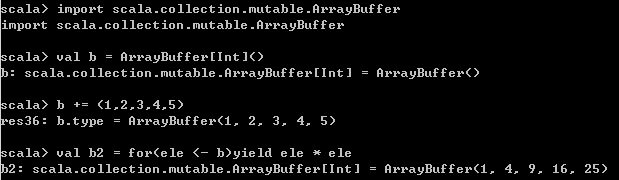
// 结合if守卫,仅转换需要的元素
// 使用函数式编程转换数组(通常使用第一种方式)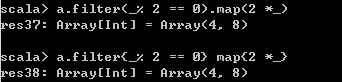
6、算法案例:移除第一个负数之后的所有负数
// 构建数组
// 只要第一个负数,后边的不要了,结果:1, 2, 3, 4, 5, -1
算法案例:移除第一个负数之后的所有负数(改良版)
// 重新构建数组
// 每记录所有不需要移除的元素的索引,稍后一次性移除所有需要移除的元素
// 性能较高,数组内的元素迁移只要执行一次即可
//keepIndexes (0,1,2,3,4,5)
//a(keepIndexes(i))=Array(1,2,3,4,5,-1)

算法案例:移除第一个负数之后的所有负数(正负相间)
// 构建数组
// 空数组用来存放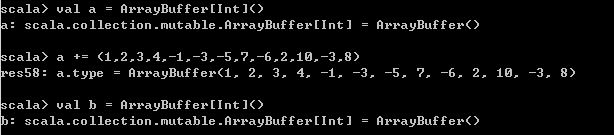
// 每记录所有不需要移除的元素的索引,稍后一次性移除所有需要移除的元素
// 性能较高,数组内的元素迁移只要执行一次即可
五、Map与Tuple
1、创建Map
// 创建一个不可变的Map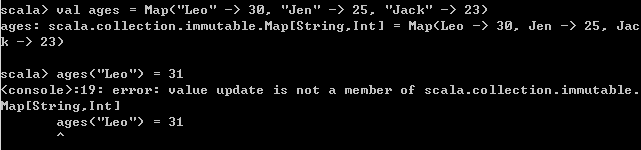
// 创建一个可变的Map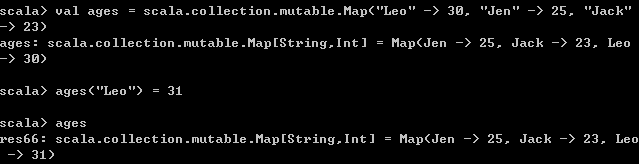
// 使用另外一种方式定义Map元素
// 创建一个空的HashMap
2、访问Map的元素
// 获取指定key对应的value,如果key不存在,会报错
// 使用contains函数检查key是否存在
// getOrElse函数
3、修改Map函数
// 更新Map的元素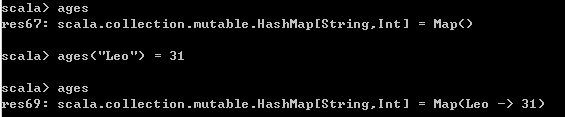
// 增加多个元素
// 移除元素
// 更新不可变的map
// 移除不可变map的元素
- Array和ArrayBuffer可变还是不可变是指的长度
- Map的可变与不可变是指的Map中是值
4、遍历Map
// 遍历map的entrySet
// 遍历map的key
// 遍历map的value
// 生成新map,反转key和value
5、SortedMap和LinkedHashMap
// SortedMap可以自动对Map的key的排序
// LinkedHashMap可以记住插入entry的顺序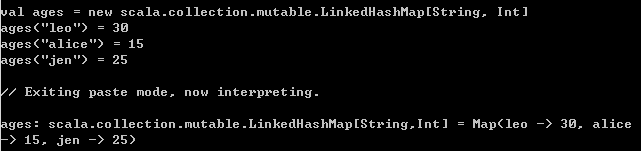
6、Map的元素类型—Tuple
// 简单Tuple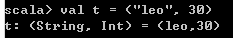
// 访问Tuple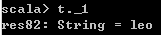
// zip操作(拉链操作)