背景
当数据量比较大且分布不均匀时,对数据进行JOIN操作很容易造成数据倾斜,因为在JOIN的执行阶段会将JOIN KEY相同的数据分发到同一个task任务上处理,如果某个key上的数据量比较多,会导致该task执行的时间比其他的task执行时间长。具体表现为:大部分的task任务都已经执行完成,但只有少数的几个task一直处于运行当中。
数据量不大的情况下,一般不会出现数据倾斜的问题。但当数据量巨大时,数据倾斜的现象就会非常普遍。比如电商网站在大促时期,某些店铺的PV远远大于普通店铺的PV,某些热门商品的PV也远远大于一些长尾商品的PV,这个时候如果进行维表的JOIN,很容易导致数据倾斜。
JOIN数据倾斜的场景
维表JOIN
当JOIN的维表数据量较小时(可以通过参数配置不超过多大),可以使用map端join,避免分发引起数据倾斜。
空值
当JOIN的两个表数据量都很大,且数据倾斜是有空key造成的,可以将空key处理成随机值,避免分发到同一个task。
热点KEY
当JOIN的两个表的数据量都很大,且是有热点key导致的数据倾斜(某个key对应的数据量非常大),可以将热点key与非热点key分别处理,再合并数据即可。
方案
map端JOIN
Join倾斜时,如果某路输入比较小,可以采用Mapjoin避免倾斜。Mapjoin的原理是将Join操作提前到Map端执行,这样可以避免因为分发Key不均匀导致数据倾斜。但是Mapjoin的使用有限制,必须是Join中的从表比较小才可用。所谓从表,即Left Outer Join中的右表,或者Right Outer Join中的左表。
map端join适用于当一张表很小(可以存在内存中)的情况,即可以将小表加载至内存。Hive从0.7开始支持自动转为map端join,具体配置如下:
SET hive.auto.convert.join=true; -- hivev0.11.0之后默认true
SET hive.mapjoin.smalltable.filesize=600000000; -- 默认 25m
SET hive.auto.convert.join.noconditionaltask=true; -- 默认true,所以不需要指定map join hint
SET hive.auto.convert.join.noconditionaltask.size=10000000; -- 控制加载到内存的表的大小
也可以使用 map join hint的方式进行手动指定:
SELECT /*+ MAPJOIN(c) */ * FROM orders o JOIN cities c ON (o.city_id = c.id);
一旦开启map端join配置,Hive会自动检查小表是否大于hive.mapjoin.smalltable.filesize配置的大小,如果大于则转为普通的join,如果小于则转为map端join。
关于map端join的原理,如下图所示:
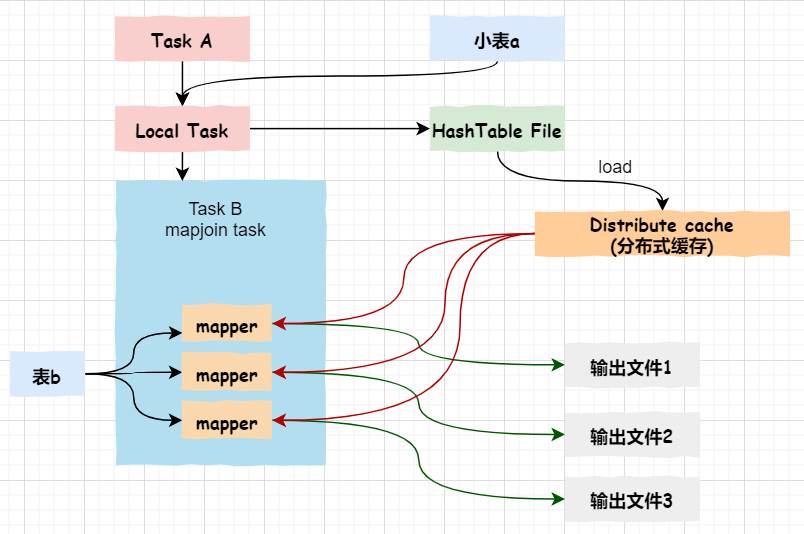
首先,Task A(客户端本地执行的task)负责读取小表a,并将其转成一个HashTable的数据结构,写入到本地文件,之后将其加载至分布式缓存。
然后,Task B任务会启动map任务读取大表b,在Map阶段,根据每条记录与分布式缓存中的a表对应的hashtable关联,并输出结果
注意:map端join没有reduce任务,所以map直接输出结果,即有多少个map任务就会产生多少个结果文件。
空值数据倾斜
如果是因为空值导致数据倾斜,且JOIN的两张表数据量都很大,此时无法使用Mapjoin,可以将空值处理成随机值。因为空值是无法关联上,只是分发到了一处,因此给予随机值即不会影响关联也能避免聚集。当然我们也可以提前对空值进行过滤。
SELECT ...
FROM (
SELECT *
FROM tbl1
WHERE ds = '${cur_date}'
) a
LEFT OUTER JOIN (
SELECT *
FROM tbl1
WHERE ds = '${cur_date}'
) b
ON coalesce(a.id,rand() * 9999) = b.id -- 通过coalesce对空值进行随机分发,避免聚集
热点Key数据倾斜
案例介绍
假设有下面两张表,一张事实表,一张维表:
事实表:fact_tbl
数据量:100MB
其中一个字段名是:code_id
99MB的数据对应的code_id为100
只有1MB的数据对应的code_id是均匀分布的
维表:dim_tbl
数据比较大,不能进行Map端join
code_id可以唯一约束一条记录
如果将上面两个表进行join:
SELECT *
FROM fact_tbl f
LEFT JOIN dim_tbl d
ON f.code_id = d.code_id
我们会注意到99%的reduce任务会快速运行结束,但是会有一个reduce任务运行的时间特变长(因为code_id=100对应的了99MB的数据),这也就是上面提到的数据倾斜。
方案1:分开查询
以上面的例子,可以分开进行查询,如下:
查询1:排出热点key数据
SELECT *
FROM fact_tbl f
LEFT JOIN dim_tbl d
ON f.code_id = d.code_id
WHERE f.code_id <> 100
查询2:单独计算热点key
SELECT *
FROM fact_tbl f
LEFT JOIN dim_tbl d
ON f.code_id = d.code_id
WHERE f.code_id = 250
AND d.code_id = 250
缺点
需要写两次SQL
如果原始的查询SQL非常复杂,分开写两次会非常麻烦
如果需要修改SQL,需要同时修改两个地方
方案2:Skew Join
SkewJoin Hint可以通过自动或手动方式获取两张表的热点key,分别计算热点数据和非热点数据的Join结果并合并,加快Join的执行速度。
我们可以通过配置Skew Join 优化,如下:
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=500000;
set hive.skewjoin.mapjoin.map.tasks=10000;
set hive.skewjoin.mapjoin.min.split=33554432;
hive.optimize.skewjoin
是否开启skew join优化,当开启参数时,在进行查询的时候会识别数据倾斜的key,首先将这些key存储在HDFS的临时文件上,在接下来的map-reduce过程中,再去处理这些数据倾斜的key(启动map端join专门计算这个特殊值)
hive.skewjoin.key
告诉hive这个join的skew key是什么,即如何判断哪个key是数据倾斜的key。根据该参数的配置值,比如默认100000,那么就认为超过100000条记录的值就是数据倾斜的key。
Skew Join的具体过程如下图所示:
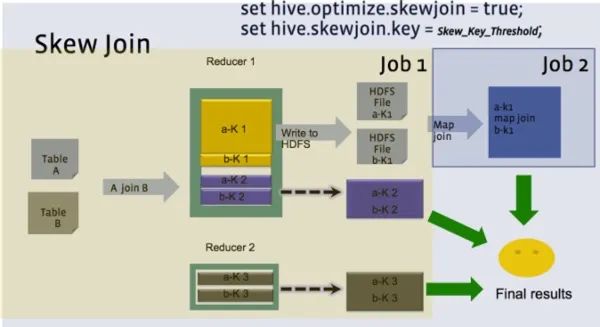
大致的步骤为:现将引起数据倾斜的key分别写入到HDFS的临时文件中,如上图的HDFS File a-K1与HDFS File b-K1,对倾斜key的数据执行map端join;对其他分部均匀的key正常执行join任务,最后将两份join的数据进行合并。