以下程序的目的很简单:就是在屏幕空间中查找视图质心坐标。然后用这个坐标来定位粘贴靶位点。
# Finds view centroid coordinates in screen space.
logging.info(' > finding projected point...')
view_arr = np.array(view.convert('L'))
screen_arr = np.array(screen.convert('L'))##把两张图片存储成数组,并传入函数
# logging.info(f'{view_arr.shape}, {screen_arr.shape}')
x, y = screenpoint.project(view_arr, screen_arr, False)
调用logging写错误日志就显得很专业……
import numpy as np
import cv2
import logging
MIN_MATCH_COUNT = 6#定义全局变量
FLANN_INDEX_KDTREE = 0 # kdtree建立索引方式的常量参数,获取flann匹配器
sift = cv2.xfeatures2d.SIFT_create()#实例化的sift函数
def project(view, screen, debug=False):
kp_screen, des_screen = sift.detectAndCompute(screen, None)#找出图像中的关键点同时计算关键点对应的sift特征向量, kp表示生成的关键点,screen表示输入的灰度图,dst表示输出的sift特征向量,通常是128维的。
##检测关键点 计算描述符
kp_view, des_view = sift.detectAndCompute(view, None)
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
#第一个是index-Params。配置要使用的算法。
##使用ELANN算法&KDtree(K-NN匹配近邻法)
###使用5棵k-d
search_params = dict(checks=50)
#第二个是Search-Params。指定递归遍历的次数。
##checks指定索引树要被遍历的次数。值越高结果越准确,但是消耗的时间也越多。
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des_screen, des_view, k=2)
Lowe’s algorithm
**Lowe’s算法:**为了进一步筛选匹配点,来获取优秀的匹配点,这就是所谓的“去粗取精”。一般会采用Lowe’s算法来进一步获取优秀匹配点。
为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,SIFT的作者Lowe提出了比较最近邻距离与次近邻距离的SIFT匹配方式:取一幅图像中的一个SIFT关键点,并找出其与另一幅图像中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离得到的比率ratio少于某个阈值T,则接受这一对匹配点。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。显然降低这个比例阈值T,SIFT匹配点数目会减少,但更加稳定,反之亦然。
Lowe推荐ratio的阈值为0.8,但作者对大量任意存在尺度、旋转和亮度变化的两幅图片进行匹配,结果表明ratio取值在0. 4~0. 6 之间最佳,小于0. 4的很少有匹配点,大于0. 6的则存在大量错误匹配点,所以建议ratio的取值原则如下:
- ratio=0. 4:对于准确度要求高的匹配;
- ratio=0. 6:对于匹配点数目要求比较多的匹配;
- ratio=0. 5:一般情况下。
Fast Library for Approximate Nearest Neighbors
FLANN它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集是它的效果要好于BFMatcher。
KDtree
随机k-d树算法(The Randomized k-dimensionality Tree Algorithm)属于快速近似NN匹配(FAST APPROXIMATE NN MATCHING)的一种。随机k-d森林在许多情形下都很有效,其中的具体划分树有两种。
a. Classic k-d tree
找出数据集中方差最高的维度,利用这个维度的数值将数据划分为两个部分,对每个子集重复相同的过程。
b. Randomized k-d tree
建立多棵随机k-d树,从具有最高方差的N_d维中随机选取若干维度,用来做划分。在对随机k-d森林进行搜索时候,所有的随机k-d树将共享一个优先队列。增加树的数量能加快搜索速度,但由于内存负载的问题,树的数量只能控制在一定范围内,比如20,如果超过一定范围,那么搜索速度不会增加甚至会减慢。
5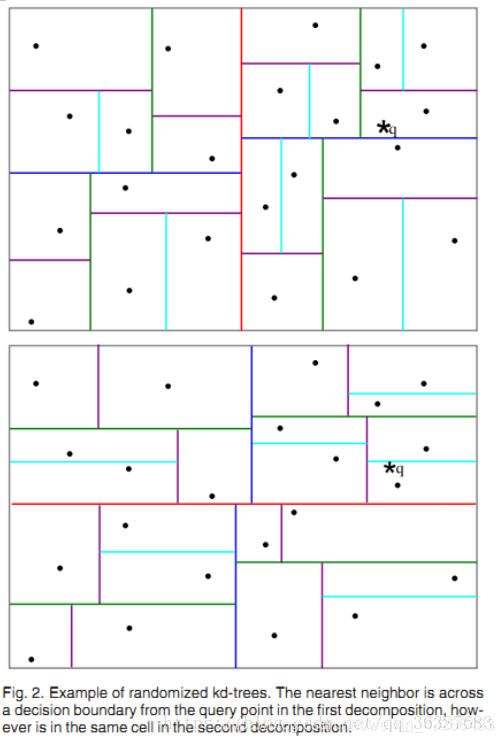
一般遵循以下规律构造:
①各层节点交替划分各维空间
根节点划分x坐标
其儿子划分y坐标
其孙子划分z坐标
…
②每一层的区域中,按该层划分的坐标排序,选取其中位数作为划分点进行划分
切点作为父节点,左边的点划分到左子树中,右边的点划分到右子树中
③逐层划分,直至划分区域无节点
类似于一种快排。
(感谢博主的解释)
另:FlannBasedMatcher简称最近邻近似匹配。是一种近似匹配方法,并不追求完美!,因此速度更快。当然也可以通过调整FlannBasedMatcher的参数来提高匹配的精度或者提高算法速度,但是相应地算法速度或者算法精度会受到影响。
# Store all good matches as per Lowe's ration test按照劳氏定量测试储存所有好的集合
## Lowe's algorithm,获取优秀匹配点
#### 寻找距离近的放入good列表
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
# 如果足够多good 就筛选
if len(good) < MIN_MATCH_COUNT:
logging.debug("ScreenPoint: Not enough matches.")
return -1, -1
# 通过距离近的描述符 找到两幅图片的关键点。后有数据存储的解释。
screen_pts = np.float32([kp_screen[m.queryIdx].pt
for m in good]).reshape(-1, 1, 2)
view_pts = np.float32([kp_view[m.trainIdx].pt
for m in good]).reshape(-1, 1, 2)
Homography 单应性
此处引用我的另一篇笔记
计算多个二维点对之间的最优单映射变换矩阵,找到并返回源平面和目标平面之间的转换矩阵H,以便于反向投影错误率达到最小。
h, w = view.shape
M, mask = cv2.findHomography(view_pts, screen_pts, cv2.RANSAC, 5.0)
得到两帧图像中的特征点和单应性矩阵M后,可以
(1)根据相应的计算方法,由前一帧图像四个角的位置,就可以得到变换后四个角对应点的位置。
(2)直接用perspectiveTransform(透视变换)来得到四个角的位置。

透视变换示例图
cv2.perspectiveTransform
Python: cv2.perspectiveTransform(src, m[, dst]) → dst
Parameters:
src – input two-channel or three-channel floating-point array; each element is a 2D/3D vector to be transformed.
dst – output array of the same size and type as src.
m – 3x3 or 4x4 floating-point transformation matrix.
pts = np.float32([[(w - 1) * 0.5, (h - 1) * 0.5]]).reshape(-1, 1, 2)
##使用reshape方法把32 位 float 型的二进制存储数据改为一个不限定行,一列,两层的三维数组!!32位存取数据!!怪不得叫我准备好6.4G内存
###使用三维数组是因为后面需要整理好的数据类型。
dst = cv2.perspectiveTransform(pts, M)# 计算第二张图相对于第一张图的该函数透视变换二维或三维向量。
x, y = np.int32(dst[0][0])
if debug:
img_debug = draw_debug_(x, y, view, screen, M, mask, kp_screen,
kp_view, good)
return x, y, img_debug
else:
return x, y
def draw_debug_(x, y, view, screen, M, mask, kp_screen, kp_view, good):
matchesMask = mask.ravel().tolist()
draw_params = dict(
matchColor=(0, 255, 0), # draw matches in green color
singlePointColor=None,
matchesMask=matchesMask, # draw only inliers
flags=2)
img_debug = cv2.drawMatches(screen, kp_screen, view, kp_view, good, None,
**draw_params)
#获取img_debug空间中的视图质心坐标。
# Get view centroid coordinates in img_debug space.
cx = int(view.shape[1] * 0.5 + screen.shape[1])
cy = int(view.shape[0] * 0.5)
#绘制视图网络
# Draw view outline.
cv2.rectangle(img_debug, (screen.shape[1], 0),
(img_debug.shape[1] - 2, img_debug.shape[0] - 2),
(0, 0, 255), 2)
#绘制连接线
# draw connecting line.
cv2.polylines(img_debug, [np.int32([(x, y), (cx, cy)])], True,
(100, 100, 255), 1, cv2.LINE_AA)
# Draw query/match markers.
cv2.drawMarker(img_debug, (cx, cy), (0, 0, 2
55), cv2.MARKER_CROSS, 30, 2)
cv2.circle(img_debug, (x, y), 10, (0, 0, 255), -1)
return img_debug
