1、select in select 第五题
数据表
题目

答案
SELECT name, CONCAT(ROUND(population/(SELECT population FROM world WHERE name = 'Germany')*100), '%')
FROM world
WHERE continent = 'Europe'
两个新关键字1、round:用来删除数字中的小数位数
2、concat:CONCAT函数用于连接两个字符串,形成一个字符串
2、数据表同上 select in select 第6题
题目如下,选出GDP比欧洲每个国家都高的国家

答案如下,(1)all 关键词可以实现变量和列表大小比较
(2)在查询欧洲国家GDP的时候要注意有一些国家的GDP为NUll,这样会导致查出的列表中包含了NUll,因此应该加上GDP>0 进行筛选
SELECT name
FROM world
WHERE gdp > ALL(
SELECT gdp
FROM world
WHERE gdp > 0 AND continent = 'Europe'
)
3、数据表同上 select in select 第7题
此处需要补充知识:关联子查询
连接子查询学废啦!!终于自己没看答案做出来一道题
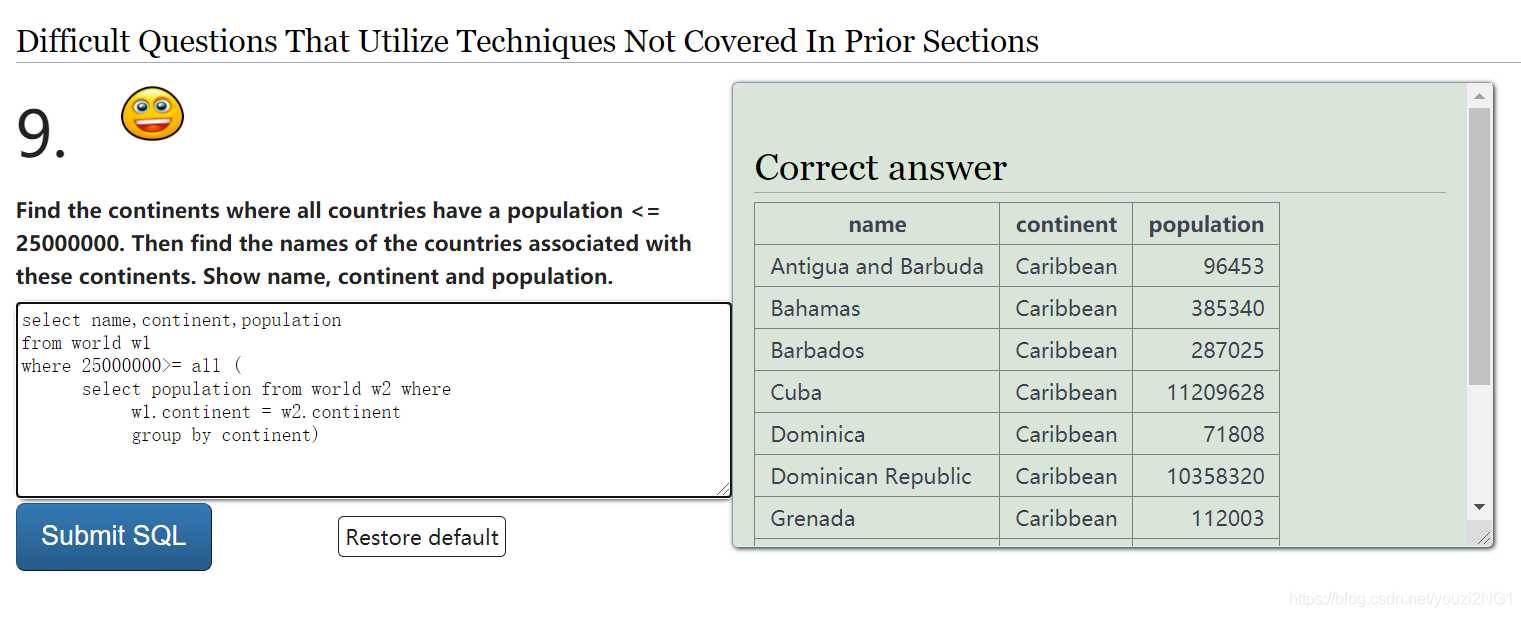
select name,continent,population
from world w1
where 25000000>= all (
select population from world w2 where
w1.continent = w2.continent
)连接子查询的查询逻辑不同于原有的查询,如上述代码,可以理解为先执行select name,continent,population
from world w1 得到一个新的表W1,对应新表中的每一行数据分别按照where条件进行选择是否查出,而where条件中包含了括号中的查询,该查询首先生成一个新的表 w 2,按照和当前判断的W1的这一行中的continent值是否相同进行选择,即: w1.continent = w2.continent,如果相同的话就把他的population拿出来放在一个列表中,这样对w2表进行遍历后得到了当前w1表判断所需的一个list ,然后判断2500000是不是大于这个list中的所有的数。。。。。然后重复执行w2 中的下一行数据可以继续查询啦。
程序实际内部处理的时候应该不会不像我说的这么麻烦,但是个人觉得这样理解就好多了。嘻嘻。
版权声明:本文为youzi2NG1原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。