一、numpy简介
1.1 定义:
numpy(numeric python)NumPy系统是Python的一种开源的数值计算扩展,它的核心是ndarray对象。
1.2 功能:
1.功能强大的N维数组对象,各种派生对象(如掩码数组和矩阵)
2.精密广播功能函数
3.集成c++和Fortran代码的工具
4.数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
1.3 NumPy数组 和 原生Python Array(数组)之间的重要区别:
1.numpy数组创建时长度固定,而python数组对象可动态增加。更改numpy数组会创建一个新的数组并删除原来的数组。
2.numpy数组的元素数据类型都必须相同,如果不同,它会统一合适的数据类型。优先级:str>float>int。python对象可以不同。
3.NumPy 数组有助于对大量数据进行高级数学和其他类型的操作。通常,这些操作的执行效率更高,比使用Python原生数组的代码更少。
二、数据类型对象
2.1 定义
数据类型对象(numpy.dtype类的实例)描述了如何解释与数组项对应的固定大小的内存块中的字节。 它描述了数据的以下几个方面:
1.数据类型(整型、浮点型、Python对象等)。
2.数据的大小(例如整数中有多少字节)。
3.数据的字节顺序(little-endian 小端法或 big-endian大端法)。
4.如果数据类型是结构化数据类型,则是其他数据类型的集合(例如,描述由整数和浮点数组成的数组项)。
∙ \bullet∙ 结构的 “字段” 的名称是什么,通过这些名称可以访问它们。
∙ \bullet∙ 每个 字段 的数据类型是什么,以及
∙ \bullet∙ 每个字段占用内存块的哪一部分。
5.如果数据类型是子数组,那么它的形状和数据类型是什么。
2.2 构造数据类型
语法:
numpy.dtype(object, align, copy) # object - 要转换为的数据类型对象
# align - 如果为 true,填充字段使其类似 C 的结构体。
# copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
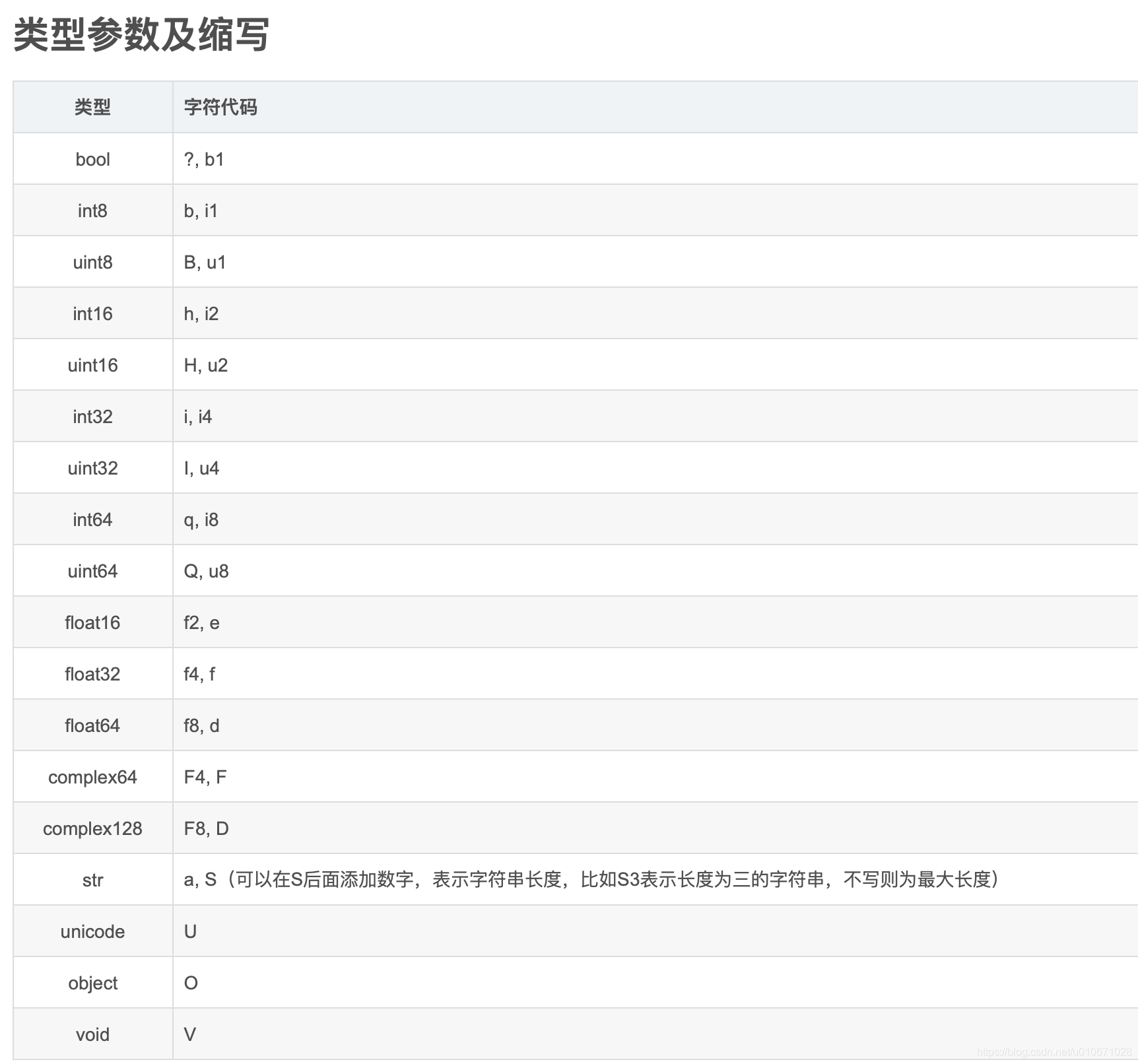
2.3 数据类型的字符表示
三、ndarray数组对象属性
1.1内存布局:
以下属性包含有关数组内存布局的信息:
| 方法 | 描述 |
|---|---|
| ndarray.flags | 有关数组内存布局的信息。 |
| ndarray.shape | 数组维度的元组。 |
| ndarray.strides | 遍历数组时每个维度中的字节元组。 |
| ndarray.ndim | 数组维数。 |
| ndarray.data | Python缓冲区对象指向数组的数据的开头。 |
| ndarray.size | 数组中的元素数。 |
| ndarray.itemsize | 一个数组元素的长度,以字节为单位 |
| ndarray.nbytes | 数组元素消耗的总字节数。 |
| ndarray.base | 如果内存来自其他对象,则为基础对象 |
1.2 数据类型
| 方法 | 描述 |
|---|---|
| ndarray.dtype | 数组元素的数据类型。 |
1.3 其他属性
| 方法 | 描述 |
|---|---|
| ndarray.T | 转置数组。 |
| ndarray.real | 数组的真实部分。 |
| ndarray.imag | 数组的虚部。 |
| ndarray.flat | 数组上的一维迭代器。 |
| ndarray.ctypes | 一个简化数组与ctypes模块交互的对象。 |
1.4 数组接口
| 方法 | 描述 |
|---|---|
| array_interface | 数组接口的Python端 |
| array_struct | 数组接口的C语言端(C-side) |
1.5 外部函数接口
| 方法 | 描述 |
|---|---|
| ndarray.ctypes | 一个简化数组与ctypes模块交互的对象。 |
四、创建数组对象
2.1 填充方式
| 方法 | 参数 | 描述 |
|---|---|---|
| numpy.random.randint(low, high=None, size=None, dtype=int) | size可以是整数也可以是元组 | 返回元素为low~high间的数组 |
| np.random.randn(d0, d1, …, dn) | 元素个数 | 返回标准正态分布的样本 |
| np.random.normal(loc=0.0, scale=1.0, size=None) | loc:均值 scale:方差 size :形状 | 返回创建的正态分布的随机样本 |
| np.random.permutation(x) | x即使产生元素的个数也是元素的范围 | 产生x个元素且范围为0~x的一维数组 |
| np.zeros(shape, dtype=float, order=‘C’) | 返回给定形状和类型的新数组,用0填充 | |
| np.zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None) | a为数组对象 | 返回一个与a形状相同,用0填充的数组 |
| np.ones(shape, dtype=None, order=‘C’) | 返回一个指定形状并用1填充的数组 | |
| np.ones_like(a, dtype=None, order=‘K’, subok=True, shape=None) | 返回给定形状和类型的新数组,用1填充 | |
| np.full(shape, fill_value, dtype=None, order=‘C’) | 返回一个指定形状并用指定值填充的数组 | |
| np.full_like(a, fill_value, dtype=None, order=‘K’, subok=True, shape=None) | 返回一个指定形状并用指定值填充的数组 | |
| numpy.eye(N,M = None,k = 0,dtype = <class’float’>,order =‘C’,*,like = None ) | N,M为行列,k表示偏移,默认为0主对角线 | 返回一个二维数组,对角线上值为1,其他位置为零。 |
2.2 从现有数据创建
| 方法 | 参数 | 描述 |
|---|---|---|
| numpy.ndarray(shape,dtype = float,buffer = None,offset = 0,strides = None,order = None ) | 数组对象表示固定大小项的多维同构数组 | |
| numpy.array(object,dtype = None,*,copy = True,order =‘K’,subok = False,ndmin = 0,like = None ) | 创建一个数组 |
2.3 数值范围
| 方法 | 参数 | 描述 |
|---|---|---|
| numpy.arange([ 开始,] 停止,[ step,] dtype = None,*,like = None ) | 返回给定间隔内的均匀间隔的值。一维数组 | |
| np.linspace(start,stop,num=50,endpoint=True, retstep=False,dtype=None,axis=0,) | 返回一个等差数组 |
五 ndarray对象方法
| 方法 | 描述 |
|---|---|
| ndarray.reshape(shape[, order]) | 返回包含具有新形状的相同数据的数组 |
| a.astype(dtype, order=‘K’, casting=‘unsafe’, subok=True, copy=True) | 改变对象的数据类型,返回一个副本 |
| a.sort(axis=-1, kind=None, order=None) | 在原数组上进行排序 |
六、numpy函数
6.1 数学函数
| 方法 | 参数 | 描述 |
|---|---|---|
| numpy.max(a, axis=None, out=None, keepdims=, initial=< no value>, where=< no value>) | axis=None返回整个数组最大值,axis=0按列返回最大值,axis=1按行返回最大值 | 返回数组最大值沿某几个轴 |
| numpy.min(a, axis=None, out=None, keepdims=< no value>, initial=< no value>, where=< no value>) | 最小值 | |
| numpy.sum(a, axis=None, dtype=None, out=None, keepdims=< no value>, initial=< no value>, where=< no value>) | 求和 | |
| np.add.reduce(arr) | 对数组进行求和,比np.sum更快 | |
| np.cumsum(arr) | 求和,比sum更快 | |
| numpy.mean(a, axis=None, dtype=None, out=None, keepdims=< no value>) | 沿指定轴计算算术平均值。 | |
| numpy.power(*args, **kwargs) | 求幂次方 | |
| np.sqrt(*args, **kwargs) | 求开方 | |
| numpy.var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=) | 计算沿指定轴的方差。 | |
| numpy.std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=) | 计算沿指定轴的标准差。 | |
| np.dot(a,b)or @ | 矩阵的乘法 | |
| np,seed() | 随机数种子,可以限定随机结果的一个整数,不同种子得到的随机结果不同,相同的种子得到的随机结果一定相同 | |
| np.meshgrid() | 从坐标向量返回坐标矩阵。 |
6.2 文件相关
| 方法 | 参数 | 描述 |
|---|---|---|
| numpy.fromfile(file, dtype=float, count=-1, sep=’’, offset=0) | 读取文件 | |
| numpy.tofile(file, dtype=float, count=-1, sep=’’, offset=0) | 保存文件 | |
| numpy.savetxt() | ||
| numpy.loadtxt() | ||
| np.genfromtxt() | 加载文本文件,并按指定方式处理缺失值 |
6.3 其他
| 方法 | 参数 | 描述 |
|---|---|---|
| np.sort(a, axis=-1, kind=None, order=None) | kind选择排序方式{‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’} | 产生新的数组进行排序,默认按行排序,对原数组无影响,浪费空间 |
| np.argsort(a, axis=-1, kind=None, order=None) | 返回对数组进行排序的索引 | |
| numpy.copy(a, order=‘K’, subok=False) | 深拷贝,复制一份内容相同,地址不同的备份 | |
| numpy.argmax(a, axis=None, out=None) | 返回沿轴的最大值的索引 | |
| numpy.nonzero(a) | a为数组 | 返回a数组所有非零元素的下标 |
| numpy.pad(array, pad_width, mode=‘constant’, constant_values=0,**kwargs) | 填充一个数组 | |
| numpy.diag(v,k=0) | v为对角线元素,k为元素位置 | 构造以v为对角线的数组 |
| numpy.unravel_index(indices, shape, order=‘C’) | indices为元素的顺序,shape数组的形状 | 返回一个indices在数组中的位置元组 |
| np.tile(A, reps) | A为数组对象,reps为每个轴上A的重复次数 | 以A来构造数组 |
| np.intersect1d(ar1, ar2, assume_unique=False, return_indices=False) | 找出数组的公共元素 | |
| np.unique(arr) | 找到数组单独的元素 | |
| np.allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False) | 判断数组是否相同,允许一定误差 | |
| np.array_equal(a1, a2, equal_nan=False) | 判断数组是否相同,不允许误差 | |
| np.ndenumerate(arr) | 枚举 | |
| np.put(a, ind, v, mode=‘raise’) | 用给定值替换数组的指定元素。 | |
| replace | 替换指定内容 |
七、索引和切片
5.1 索引
∙ \bullet∙ 行间接索引:
arr[a1][a2].......[an] # an为第n个轴第an个数据元素
∙ \bullet∙ 行直接索引:
arr[a1,a2,a3, .....,an] # an为第n个轴第an个数据元素
∙ \bullet∙ 列直接索引:
arr[ : ,a1] # a1为第多少列
∙ \bullet∙ 构造新数组再列索引:
arr[[a1,a2,....],n] # 以原来数组的第a1...行构成新的数组,在获取新数组的第n列
∙ \bullet∙ 根据布尔值取数组的数据:
arr[[Ture,False,...]] # 取数组的行,布尔列表的个数和数组的行数要匹配,Ture表示取该行,False表示不取
arr[ :,[Ture,False,...]] # 取数组的列,布尔列表的个数和数组的列数要匹配,Ture表示取该列,False表示不取
5.2 赋值
索引的基础上赋值即可,会覆盖原有位置上的数据。
5.3 切片
∙ \bullet∙ 翻转数组:
arr[: :-1] # 按行翻转数组
arr[:, : :-1] # 按列翻转数组
八、矩阵乘法
numpy.dot(a, b, out=None) # a,b为两个数组,且一个的列等于另一个的行。
# 返回两个矩阵的点积
@
九、数组的计算
逐元素操作
十、广播
∙ \bullet∙ 定义:当数组的形状不相同时,可以通过拓展数组的方式来实现相加、相乘、相处、相减的操作 ,这种机制叫做广播
∙ \bullet∙ 规则:
为缺失的维度补1
缺失元素用已有值补充
∙ \bullet∙ 广播的适用范围:
1.只能单方向拓展
2.补全时若其他各行或列的元素不同,则无法补全
十一、数组的合并(集联)
a1 = array([4, 3, 0, 2, 1])
a2 = array([3, 4, 1, 2, 0])
numpy.hstack((a1,a2)) # array([4, 3, 0, 2, 1, 3, 4, 1, 2, 0])
numpy.vstack((a1,a2)) # array([[4, 3, 0, 2, 1],
[3, 4, 1, 2, 0]])
numpy.concatenate((a1,a2),axis=0) # array([4, 3, 0, 2, 1, 3, 4, 1, 2, 0])
numpy.concatenate((a1,a2),axis=1) # array([[4, 3, 0, 2, 1],
[3, 4, 1, 2, 0]])
注意:
级联的参数必须时元组:一定加中括号或小括号
维度必须相同
形状相符
级联的方向默认是shape中元组里第一个值代表的维度。
十二、数组的切分
b1 = array([[11, 11, 7, 13, 9, 11],
[19, 6, 15, 0, 1, 3],
[ 7, 17, 18, 0, 10, 2],
[16, 5, 17, 0, 0, 8],
[ 9, 7, 18, 19, 10, 6],
[ 7, 3, 17, 3, 10, 6]])
np.split(b1,indices_or_sections=3,axis=0)
[array([[11, 11, 7, 13, 9, 11],
[19, 6, 15, 0, 1, 3]]),
array([[ 7, 17, 18, 0, 10, 2],
[16, 5, 17, 0, 0, 8]]),
array([[ 9, 7, 18, 19, 10, 6],
[ 7, 3, 17, 3, 10, 6]])]
np.hsplit(b1,indices_or_sections=2) # 将原数组按行平均分成两份
np.vsplit(b1,indices_or_sections=3) # 将原数组按列平均分成三份
indices_or_sections可以是一个列表,如[2,3]表示将原数组从头分两份,从尾分三份
切分没有在原数组上进行操作