第四章主要讨论如下问题:
1、线性地址空间的构成及其各个部分的用途。(4.1)
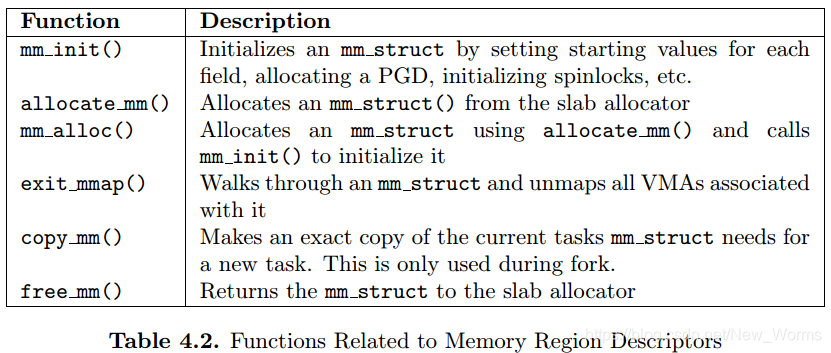
2、与进程相关的结构mm_struct以及mm_struct的配置、初始化和释放。(4.2,4.3)
3、如何创建进程地址空间中的私有区域以及与之相关的函数,同时涉及到与进程相关的异常处理、缺页中断等。
4、介绍内核与用户空间之间如何相互正确地拷贝数据。
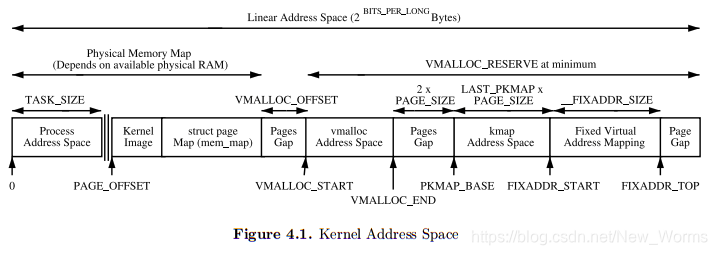
4.1 Linear Address Space
4.2 Managing the Address Space(地址空间的管理)
进程使用的地址空间由mm_struct管理。每个进程地址空间中都包含许多使用中的页面对齐的内存区域。(他们不会重叠,而且表示了一个地址的集合,这个集合包含那些出于保护或其他目的而相互关联的页面。)这些区域由struct vm_area_struct管理。具体而言,一个内存区域可能表示malloc()所使用的进程堆,或是一个内存映射文件(例如共享库),又或者是一块有mmap()分配的匿名内存区域。这些区域中的页面可能还未被分配,或已分配,或常驻内存中,或已被交换出去。
如果一个区域是一个文件的映像,那么它的vm_file字段将被设置。通过vm_file->f_dentry->d_inode->i_mapping可以最终获得这段区域所代表的地址空间内容。
struct vm_area_struct {
____struct mm_struct * vm_mm;___/* The address space we belong to. */
____unsigned long vm_start;_____/* Our start address within vm_mm. */
____unsigned long vm_end;_______/* The first byte after our end address
____________________ within vm_mm. */
____/* linked list of VM areas per task, sorted by address */
____struct vm_area_struct *vm_next;
____pgprot_t vm_page_prot;______/* Access permissions of this VMA. */
____unsigned long vm_flags;_____/* Flags, listed below. */
____rb_node_t vm_rb;
____/*
____ * For areas with an address space and backing store,
____ * one of the address_space->i_mmap{,shared} lists,
____ * for shm areas, the list of attaches, otherwise unused.
____ */
____struct vm_area_struct *vm_next_share;
____struct vm_area_struct **vm_pprev_share;
____/* Function pointers to deal with this struct. */
____struct vm_operations_struct * vm_ops;
____/* Information about our backing store: */
____unsigned long vm_pgoff;_____/* Offset (within vm_file) in PAGE_SIZE
____________________ units, *not* PAGE_CACHE_SIZE */
____struct file * vm_file;______/* File we map to (can be NULL). */
____unsigned long vm_raend;_____/* XXX: put full readahead info here. */
____void * vm_private_data;_____/* was vm_pte (shared mem) */
};
struct address_space {
409 ____struct list_head____clean_pages;____/* list of clean pages */
410 ____struct list_head____dirty_pages;____/* list of dirty pages */
411 ____struct list_head____locked_pages;___/* list of locked pages */
412 ____unsigned long_______nrpages;____/* number of total pages */
413 ____struct address_space_operations *a_ops;_/* methods */
414 ____struct inode________*host;______/* owner: inode, block_device */
415 ____struct vm_area_struct___*i_mmap;____/* list of private mappings */
416 ____struct vm_area_struct___*i_mmap_shared; /* list of shared mappings */
417 ____spinlock_t______i_shared_lock; /* and spinlock protecting it */
418 ____int_________gfp_mask;___/* how to allocate the pages */
419 };
4.3 进程地址空间描述符
struct mm_struct {
207 ____struct vm_area_struct * mmap;_______/* list of VMAs */
208 ____rb_root_t mm_rb;
209 ____struct vm_area_struct * mmap_cache;_/* last find_vma result */
210 ____pgd_t * pgd;
211 ____atomic_t mm_users;__________/* How many users with user space? */
212 ____atomic_t mm_count;__________/* How many references to "struct mm_struct" (users count as 1) */
213 ____int map_count;______________/* number of VMAs */
214 ____struct rw_semaphore mmap_sem;
215 ____spinlock_t page_table_lock;_____/* Protects task page tables and mm->rss */
216
217 ____struct list_head mmlist;________/* List of all active mm's. These are globally strung
218 ________________________ * together off init_mm.mmlist, and are protected
219 ________________________ * by mmlist_lock
220 ________________________ */
221
222 ____unsigned long start_code, end_code, start_data, end_data;
223 ____unsigned long start_brk, brk, start_stack;
224 ____unsigned long arg_start, arg_end, env_start, env_end;
225 ____unsigned long rss, total_vm, locked_vm;
226 ____unsigned long def_flags;
227 ____unsigned long cpu_vm_mask;
228 ____unsigned long swap_address;
229
230 ____unsigned dumpable:1;
231
232 ____/* Architecture-specific MM context */
233 ____mm_context_t context;
234 };进程地址空间由mm_struct描述,一个进程只有一个mm_struct结构,且该结构在进程用户空间由多个线程所共享。事实上线程通过任务链表里的任务是否指向同一个mm_struct来判定的。
内核线程只有在vmalloc空间的缺页中断中使用,其他地方不需要,因为内核线程永远不会发生缺页中断或访问用户空间。
mm_struct中有两个引用计数mm_users,mm_count。
211 ____atomic_t mm_users;__________/* How many users with user space? */
212 ____atomic_t mm_count;__________/* How many references to "struct mm_struct" (users count as 1) */
4.4 Memory Regions
内存区域由vm_area_struct来表示。它们各自代表有相同属性和用途的地址集合。
所有区域按地址排序由指针vm_next链接成一个链表;
由rb_node_t vm_rb组成一个红黑树结构,用于在发生缺页中断时搜索VMA以找到一个指定区域。
4.4.1 内存区域的操作
struct vm_operations_struct {
____void (*open)(struct vm_area_struct * area);
____void (*close)(struct vm_area_struct * area);
____struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused);
};
The main operation of interest is thenopage() callback. This callback is used
during a page-fault by do no page(). The callback is responsible for locating the
page in the page cache or allocating a page and populating it with the required data
before returning it.
Most files that are mapped will use a generic vm operations struct()
called generic_file_vm_ops.
2243 static struct vm_operations_struct generic_file_vm_ops = {
2244 nopage: filemap_nopage,
2245 };
4.4.2 有后援文件/设备的内存区域
struct address_space {
struct list_head clean_pages; /* list of clean pages */
struct list_head dirty_pages; /* list of dirty pages */
struct list_head locked_pages; /* list of locked pages */
unsigned long nrpages; /* number of total pages */
struct address_space_operations *a_ops; /* methods */
struct inode *host; /* owner: inode, block_device */
struct vm_area_struct *i_mmap; /* list of private mappings */
struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
spinlock_t i_shared_lock; /* and spinlock protecting it */
int gfp_mask; /* how to allocate the pages */
};
struct vm_area_struct
->vm_file(struct file)
->f_dentry(struct dentry)
->d_inode(struct inode)
->i_mapping(struct address_space)
->a_ops(struct address_space_operations)Periodically, the memory manager will need to flush information to disk. The
memory manager does not know and does not care how information is written to
disk, so the a_ops struct is used to call the relevant functions. It is declared as
follows in <linux/fs.h>
struct address_space_operations {
int (*writepage)(struct page *);
int (*readpage)(struct file *, struct page *);
int (*sync_page)(struct page *);
/*
* ext3 requires that a successful prepare_write() call be followed
* by a commit_write() call - they must be balanced
*/
int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
int (*bmap)(struct address_space *, long);
int (*flushpage) (struct page *, unsigned long);
int (*releasepage) (struct page *, int);
#define KERNEL_HAS_O_DIRECT /* this is for modules out of the kernel */
int (*direct_IO)(int, struct inode *, struct kiobuf *, unsigned long, int);
#define KERNEL_HAS_DIRECT_FILEIO /* Unfortunate kludge due to lack of foresight */
int (*direct_fileIO)(int, struct file *, struct kiobuf *, unsigned long, int);
void (*removepage)(struct page *); /* called when page gets removed from the inode */
};
4.4.3 创建内存区域
mmap()->sys_mmap2()->do_mmap2()->do_mmap_pgoff()
unsigned long do_mmap_pgoff(struct file * file, unsigned long addr, unsigned long len,
unsigned long prot, unsigned long flags, unsigned long pgoff)
{
......
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
vm_flags = calc_vm_flags(prot,flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
......
if (file) { /*文件映射*/
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if ((prot & PROT_WRITE) && !(file->f_mode & FMODE_WRITE))
return -EACCES;
/* Make sure we don't allow writing to an append-only file.. */
if (IS_APPEND(file->f_dentry->d_inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/* make sure there are no mandatory locks on the file. */
if (locks_verify_locked(file->f_dentry->d_inode))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
break;
default:
return -EINVAL;
}
} else {/*匿名映射*/
vm_flags |= VM_SHARED | VM_MAYSHARE;
switch (flags & MAP_TYPE) {
default:
return -EINVAL;
case MAP_PRIVATE:
vm_flags &= ~(VM_SHARED | VM_MAYSHARE);
/* fall through */
case MAP_SHARED:
break;
}
}
/* Clear old maps */
munmap_back:
vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent);
......
vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
if (!vma)
return -ENOMEM;
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = protection_map[vm_flags & 0x0f];
vma->vm_ops = NULL;
vma->vm_pgoff = pgoff;
vma->vm_file = NULL;
vma->vm_private_data = NULL;
vma->vm_raend = 0;
if (file) {
......
error = file->f_op->mmap(file, vma);
......
} else if (flags & MAP_SHARED) {
......
error = shmem_zero_setup(vma);
......
}
......
vma_link(mm, vma, prev, rb_link, rb_parent);
......
if (vm_flags & VM_LOCKED) {
mm->locked_vm += len >> PAGE_SHIFT;
make_pages_present(addr, addr + len);
}
return addr;
}4.4.4 查找已映射区域
1、find_vma
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
2、find_vma_prev
/* Same as find_vma, but also return a pointer to the previous VMA in *pprev. */
struct vm_area_struct * find_vma_prev(struct mm_struct * mm, unsigned long addr,
struct vm_area_struct **pprev)
3、find_vma_intersection
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache;
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
rb_node_t * rb_node;
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
struct vm_area_struct * vma_tmp;
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
4..4.5 查找空闲内存区域
get_unmapped_area()首先判断文件系统是否提供对应的处理函数,如果没有提供,则调用find_vma()查找临近的vma,返回对应的addr。如果没有找到,则从TASK_SIZE/3的位置开始搜索地址区间。
unsigned long get_unmapped_area(struct file *file, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags)
{
if (flags & MAP_FIXED) {
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (addr & ~PAGE_MASK)
return -EINVAL;
return addr;
}
if (file && file->f_op && file->f_op->get_unmapped_area)
return file->f_op->get_unmapped_area(file, addr, len, pgoff, flags);
return arch_get_unmapped_area(file, addr, len, pgoff, flags);
}
/*
The parameters passed are the following:
• file The file or device being mapped
• addr The requested address to map to
• len The length of the mapping
• pgoff The offset within the file being mapped
• flags Protection flags
*/
#ifndef HAVE_ARCH_UNMAPPED_AREA
static inline unsigned long arch_get_unmapped_area(struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long
flags)
{
struct vm_area_struct *vma;
if (len > TASK_SIZE)
return -ENOMEM;
if (addr) {
addr = PAGE_ALIGN(addr);
/*find vma() will return the region closest to the requested address.*/
vma = find_vma(current->mm, addr);
if (TASK_SIZE - len >= addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
/* This decides where the kernel will search for a free chunk of vm
* space during mmap's.
*
#define TASK_UNMAPPED_BASE (TASK_SIZE / 3)
*/
addr = PAGE_ALIGN(TASK_UNMAPPED_BASE);
for (vma = find_vma(current->mm, addr); ; vma = vma->vm_next) {
/* At this point: (!vma || addr < vma->vm_end). */
if (TASK_SIZE - len < addr)
return -ENOMEM;
if (!vma || addr + len <= vma->vm_start)
return addr;
addr = vma->vm_end;
}
}
#else
extern unsigned long arch_get_unmapped_area(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
#endif
4.4.6 插入内存区域
1、首先调用find_vma_prepare()找到将要插入到两个vma之间的新区域,以及vma在rbtree中的位置。
2、调用vma_link()将新区域插入vma链表。
/* Insert vm structure into process list sorted by address
* and into the inode's i_mmap ring. If vm_file is non-NULL
* then the i_shared_lock must be held here.
*/
void __insert_vm_struct(struct mm_struct * mm, struct vm_area_struct * vma)
{
struct vm_area_struct * __vma, * prev;
rb_node_t ** rb_link, * rb_parent;
__vma = find_vma_prepare(mm, vma->vm_start, &prev, &rb_link, &rb_parent);
if (__vma && __vma->vm_start < vma->vm_end)
BUG();
__vma_link(mm, vma, prev, rb_link, rb_parent);
mm->map_count++;
validate_mm(mm);
}
void insert_vm_struct(struct mm_struct * mm, struct vm_area_struct * vma)
{
struct vm_area_struct * __vma, * prev;
rb_node_t ** rb_link, * rb_parent;
__vma = find_vma_prepare(mm, vma->vm_start, &prev, &rb_link, &rb_parent);
if (__vma && __vma->vm_start < vma->vm_end)
BUG();
vma_link(mm, vma, prev, rb_link, rb_parent);
validate_mm(mm);
}
4.4.7 合并邻接区域
主要是vma_merge()函数实现,但仅两个地方用到
The first is user in sys_mmap(), which calls it if an anonymous region
is being mapped because anonymous regions are frequently mergeable. The second
time is during do_brk(), which is expanding one region into a newly allocated one
where the two regions should be merged.
4.4.8 重映射和移动内存区域
系统调用mremap()->sys_mremap()->do_mremap()
4.4.9 对内存区域上锁
系统调用mlock()->sys_lock()为需要上锁的地址范围创建VMA,并设置VM_LOCKED标志位,然后调用make_pages_present()函数以保证所有的页都在内存中。
系统调用mlockall()实现类似mlock()。
对上锁的内存限制:
1、待锁定的地址范围必须是页面对齐的。
2、待锁定的地址不能超过系统管理员设置的进程限制RLIMIT_MLOCK。
3、每个进程每次只能锁住一半的物理内存。
asmlinkage long sys_mlock(unsigned long start, size_t len)
{
____unsigned long locked;
____unsigned long lock_limit;
____int error = -ENOMEM;
____down_write(¤t->mm->mmap_sem);
____len = PAGE_ALIGN(len + (start & ~PAGE_MASK));
____start &= PAGE_MASK;
____locked = len >> PAGE_SHIFT;
____locked += current->mm->locked_vm;
____lock_limit = current->rlim[RLIMIT_MEMLOCK].rlim_cur;
____lock_limit >>= PAGE_SHIFT;
____/* check against resource limits */
____if (locked > lock_limit)
________goto out;
____/* we may lock at most half of physical memory... */
____/* (this check is pretty bogus, but doesn't hurt) */
____if (locked > num_physpages/2)
________goto out;
____error = do_mlock(start, len, 1);
out:
____up_write(¤t->mm->mmap_sem);
____return error;
}
static int do_mlock(unsigned long start, size_t len, int on)
{
____unsigned long nstart, end, tmp;
____struct vm_area_struct * vma, * next;
____int error;
____if (on && !capable(CAP_IPC_LOCK))
________return -EPERM;
____len = PAGE_ALIGN(len);
____end = start + len;
____if (end < start)
________return -EINVAL;
____if (end == start)
________return 0;
____vma = find_vma(current->mm, start);
____if (!vma || vma->vm_start > start)
________return -ENOMEM;
____for (nstart = start ; ; ) {
________unsigned int newflags;
________/* Here we know that vma->vm_start <= nstart < vma->vm_end. */
________newflags = vma->vm_flags | VM_LOCKED;
________if (!on)
____________newflags &= ~VM_LOCKED;
________if (vma->vm_end >= end) {
____________error = mlock_fixup(vma, nstart, end, newflags);
____________break;
________}
________tmp = vma->vm_end;
________next = vma->vm_next;
________error = mlock_fixup(vma, nstart, tmp, newflags);
________if (error)
____________break;
________nstart = tmp;
________vma = next;
________if (!vma || vma->vm_start != nstart) {
____________error = -ENOMEM;
____________break;
________}
____}
____return error;
}