Synchronized
用法
synchronized可用来给对象和方法或者代码块加锁,当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。
synchronized有三种应用方式:
作用于实例方法,当前实例加锁,进入同步代码前要获得当前实例的锁;
作用于静态方法,当前类加锁,进去同步代码前要获得当前类对象的锁;
作用于代码块,对括号里配置的对象加锁。
锁升级
在说锁升级前时先要简单介绍下对象内存结构,可以分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。
Mark Word用来存储对象的 identity hash code, Thread ID, GC年代, 偏向锁状态, 锁状态信息. 其中的很多状态和信息会随着当前对象的锁状态发生变化而变化. 所以接下来就根据锁的状态为主轴, 列出Mark Word的信息变化.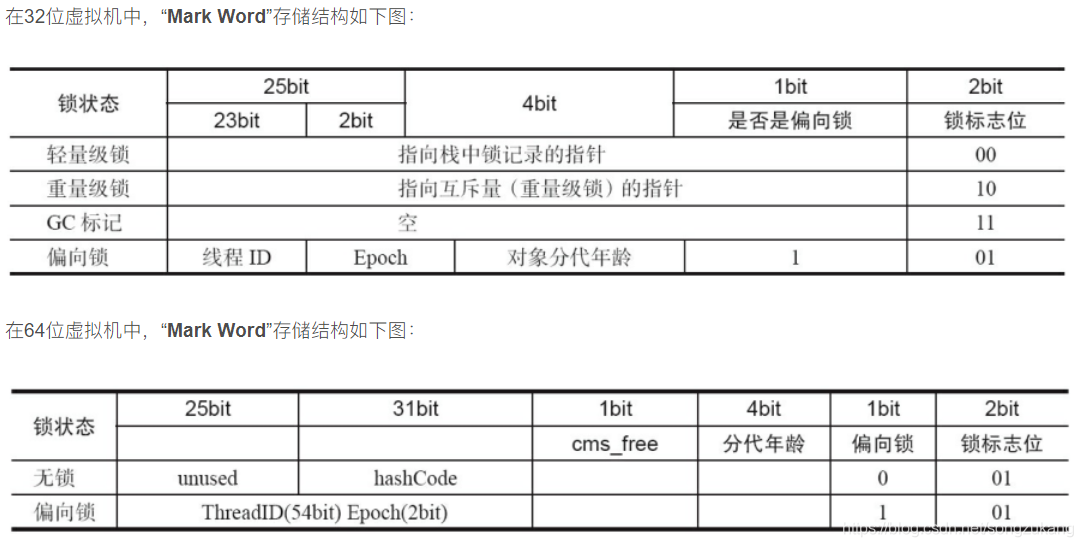
那么以下段代码为例,分析下Java SE 1.6中锁的状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态
synchronized (lock) {
// do something
}
这段代码会有4种情况
情况一:只有Thread#1会进入临界区; (偏向锁状态)
情况二:Thread#1和Thread#2交替进入临界区; (轻量级锁)
情况三:大量线程同时进入临界区。 (重量级锁)
情况四:无线程同时进入临界区。 (无锁状态)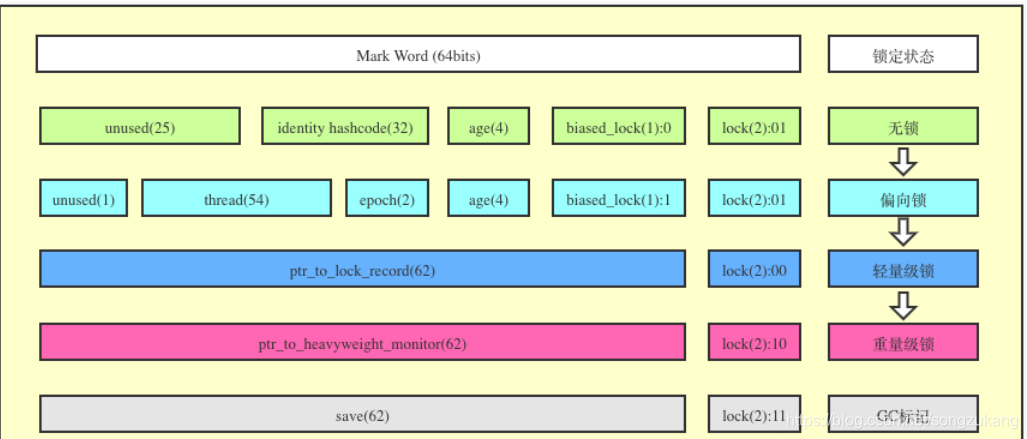
无锁
当new出对象后, 并且没有线程锁定当前对象时. 当前对象就处于无锁状态.
identity hashcode
占用32bits, identity hashcode会根据物理内存地址来生成hashcode, 保证每一个不同内存对象的hashcode都不一样. 对象加锁后, 没有足够的空间来存储hashcode了, 就将hashcode转移到管程Monitor中维护。
age
占用4bits, 代表当前对象此刻被GC的次数. 因为只有4个bit, 所以最大只能到15, 默认情况下就是age达到15这个阈值后GC就会将当前对象从年轻代转移到老年代. 这个age可以根据JVM参数-XX:MaxTenuringThreshold来设置. 绝大部分情况默认都是15次, GC的CMS默认是6次.
biased lock
占用1bit, 通过 0 | 1来判断当前是否为偏向锁状态. 无锁状态为0.
lock
占用2bits, 用来区分轻量级锁, 重量级锁, GC标记和其他状态. 无锁状态为01
偏向锁
偏向锁状态
当对象在无锁状态下, 有一个线程要锁定当前对象时, 锁状态升级到偏向锁. 偏向锁在无线程竞争时, 消除同步达到提高效率的目的.
- hashcode迁移到管程Monitor中管理
- 将biased lock标记位置为1
- 当前要锁定的线程信息存入到thread标记位中
- epoch是一个标记位, 初始值是类中epoch的值. 当一个类的对象发生偏向锁撤销(当前偏向线程A, A执行完后线程B申请锁, 就需要撤销偏向锁再重偏向线程B)的次数超过阈值(XX:BiasedLockingBulkRebiasThreshold)20后, 会对该类对象的锁状态进行批量重偏向, epoch会自增并同步更新所有类对象的Mark Word, 更新后对象中的epoch就和class中的epoch信息不一致了, 这时再有线程申请锁时, 直接进行重偏向CAS替换thread信息.
- 当偏向锁撤销超过阈值(XX:BiasedLockingBulkRevokeThreshold)40次后, 虚拟机认为这个类的对象撤销锁太频繁了直接升级所有类对象的偏向锁锁为轻量级锁.
偏向锁之所以会叫偏向锁就是因为它会保存申请锁的线程信息, 并且之后处理会偏向于存储这些信息的线程. 根据一个没有来源的统计描述绝大多数的锁大部分情况下都是被一个线程所持有, 并且我们日常中大部分使用的锁都是可重入锁. 当同一个线程多次申请当前对象的锁时(偏向锁状态下), cpu只需要判断一下偏向锁保存的线程id是否跟正在申请锁的线程一致, epoch是否和类的epoch保持一致, 如果一致的话就继续保持偏向锁的状态并且不需要做额外的检查切换工作(偏向锁加锁解锁的过程效率极高). 如果不一致, 就看上个线程是否还存活, 如果线程不在了就撤销老的偏向锁进行重偏向. 否则就撤销偏向锁升级到轻量级锁.
轻量级锁
当有超过一个存活线程向当前对象申请锁状态时, 升级为轻量级锁. 轻量级锁在少量线程竞争时, 使用CAS(CAS解析)和自旋等待在用户态消除同步, 通常比直接使用重量级锁效率要高.
- 将lock状态标记为00
- 拷贝Mark Word中的其他数据到持锁线程的锁记录中.
- 将lock record指针指向持锁线程的锁记录上.
1.锁的字节码级别是由两个指令组成, 分别是锁的入口monnitorenter和锁的结束monitorexit. 当线程进入monnitorenter后, 会在自己的线程的栈帧上建立一个锁记录, 并通过CAS机制尝试将锁对象的Mark Word中的信息拷贝到自己的栈帧中, 并将ptr_to_lock_record指针指向自己线程栈帧的锁记录上. 也标志了当前对象现在被该线程锁了.
2.线程退出同步块后将Mark Word再通过CAS还给对象头, 让其他线程知道现在锁空闲了.
轻量级锁也是自旋锁, 因为绝大多数情况下线程获得锁和释放锁的过程都是非常短暂的,自旋一定次数之后极有可能碰到获得锁的线程释放锁,所以,轻量级锁适用于那些同步代码块执行很快的场景,这样,线程原地等待很短的时间就能够获得锁了。
注意:锁在原地循环等待的时候,是会消耗CPU资源的。所以自旋必须要有一定的条件控制,否则如果一个线程执行同步代码块的时间很长,那么等待锁的线程会不断的循环反而会消耗CPU资源。默认情况下锁自旋的次数是 10 次。
自适应自旋
在 JDK1.7 开始,引入了自适应自旋锁,修改自旋锁次数的JVM参数被取消,由虚拟机自动调整。自适应意味着自旋的次数不是固定不变的,而是根据前一次在同一个锁上自旋的时间以及锁的拥有者的状态来决定。
如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。
如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。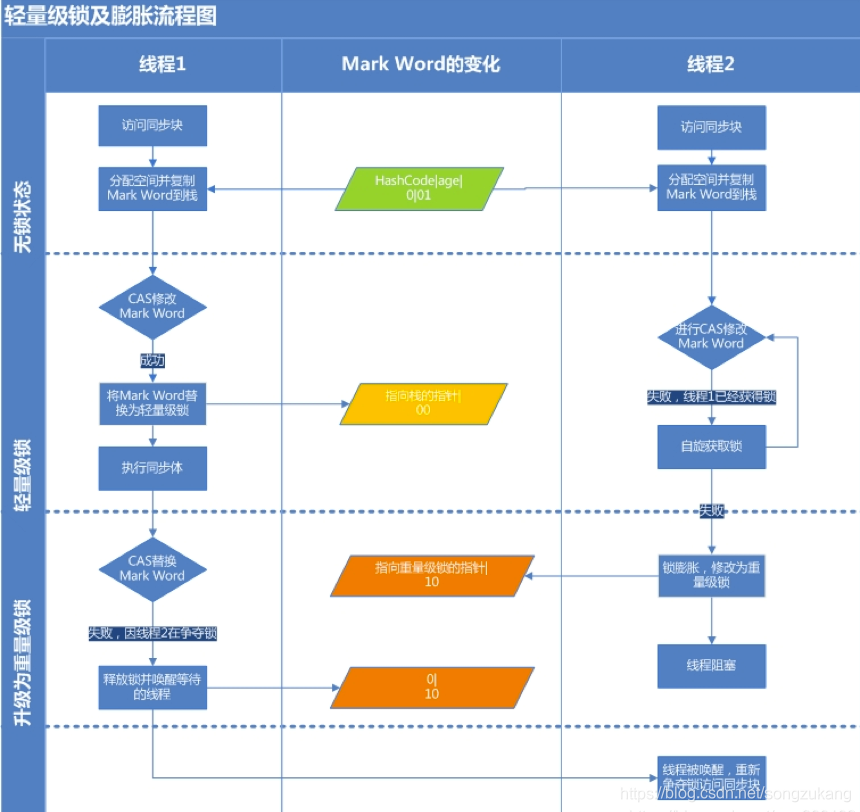
重量级锁
在重量级锁状态下, 对象头中的ptr_to_heavyweight_monitor指针指向管程Monitor对象. 之后线程的锁分配操作就要从用户态移交给内核态去处理, 让cpu通过操作系统级别的互斥量Monitor对象来管理锁, 系统创建一个等待队列, 没获取到锁的线程被系统挂起并在队列中排队, 不再像自旋锁那样不停得消耗额外的资源. 就是因为有内核态操作, 操作系统级调度, 挂起线程这些很重的操作, 所以叫重量级锁.
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步代码块仅存在纳秒级差距 | 如果线程间存在锁竞争,会带来额外的锁撤销消耗 | 适用于只有一个线程访问同步代码块场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁,使用自旋会消耗CPU | 追求响应时间;同步代码块执行时间非常短 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量;同步代码块执行时间较长 |
锁优化和逃逸分析
1.锁优化
主要分为 jvm 层面和代码编程两个方面
jvm:锁消除
编程:减少锁持有的时间,锁分离,减小锁的力度
锁消除
通过jvm逃逸分析实现,
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
从源码中可以看出,append方法用了synchronized关键词,它是线程安全的。
但我们可能仅在线程内部把StringBuffer当作局部变量使用:
public class Demo {
public static void main(String[] args) {
createStringBuffer("sss", "技术");
}
public static String createStringBuffer(String str1, String str2) {
StringBuffer sBuf = new StringBuffer();
sBuf.append(str1);// append方法是同步操作
sBuf.append(str2);
return sBuf.toString();
}
}
上面代码,StringBuffer没有逃逸出createStringBuffer方法,每次调用都会创建新的buffer,所以编译时此处的 synchronized去掉。
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
其中+DoEscapeAnalysis表示开启逃逸分析,+EliminateLocks表示锁消除。
减少锁持有时间
在方法没有必要做同步的时候,就不需要放在锁中,因此在高并发下,等待的时间就会减少,就会提高自旋锁的成功率。
减小锁粒度
将大对象,拆成小对象,大大增加并行度,降低锁竞争。
偏向锁,轻量级锁成功率提高
比如 ConcurrentHashMap 对于竞争的优化,相对于 HashMap。
锁分离(读写分离)
根据功能进行锁分离,比如ReadWriteLock
读多写少的情况,可以提高性能
读写分离思想可以延伸,只要操作互不影响,锁就可以分离
LinkedBlockingQueue(所分离的扩展案例)锁分离的思想在很多场合下都可以使用。
无锁编程(Lock-Free)CAS
2.逃逸分析
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析, -XX:+DoEscapeAnalysis : 表示开启逃逸分析 -XX:-DoEscapeAnalysis : 表示关闭逃逸分析 从jdk 1.7开始已经默认开始逃逸分析.
使用内存逃逸分析技术,编译器会对代码做如下优化
1.同步省略(锁消除)。如果一个对象被发现只能从一个线程被访问到。那么对于这个对象的操作可以不考虑同步。
2.将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使得指向该对象的指针永远不会逃逸,对象可能是栈分配的时候选的,而不是堆分配
3.分离对象或者标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以访问到。那么对象的部分可以不存储在内存中,而是存储在CPU的寄存器中。
标量替换
在JIT编译阶段,如果经过逃逸分析,发现一个对象不会被外界访问到,那么经过JIT优化之后,就会把这个对象拆解为若干个其中包含的若干个成员变量来代替。这个过程叫标量替换。
public static void main(String[] args) {
alloc();
}
private static void alloc() {
Point point = new Point(1,2);
System.out.println("point.x="+point.x+"; point.y="+point.y);
}
class Point{
private int x;
private int y;
}
以上代码中,point对象没有逃逸出alloc方法,并且point对象可以拆分为标量的。那么,JIT就不会直接创建POINT对象,而是直接使用两个标量int x,int y代替POINT对象。
所以,经过JIT优化之后。
private static void alloc() {
int x = 1;
int y = 2;
System.out.println("point.x="+x+"; point.y="+y);
}
将堆分配转化为栈分配
我们知道,在一般情况下,对象和数组元素的内存分配是在堆内存上进行的。但是随着JIT编译器的日渐成熟,很多优化使这种分配策略并不绝对。JIT编译器就可以在编译期间根据逃逸分析的结果,来决定是否可以将对象的内存分配从堆转化为栈。
我们来看以下代码:
public static void main(String[] args) {
long a1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
alloc();
}
// 查看执行时间
long a2 = System.currentTimeMillis();
System.out.println("cost " + (a2 - a1) + " ms");
// 为了方便查看堆内存中对象个数,线程sleep
try {
Thread.sleep(100000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
private static void alloc() {
User user = new User();
}
static class User {
}
其实代码内容很简单,就是使用for循环,在代码中创建100万个User对象。
我们在alloc方法中定义了User对象,但是并没有在方法外部引用他。也就是说,这个对象并不会逃逸到alloc外部。经过JIT的逃逸分析之后,就可以对其内存分配进行优化。
我们指定以下JVM参数并运行:
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程序打印出 cost XX ms 后,代码运行结束之前,我们使用[jmap][1]命令,来查看下当前堆内存中有1000000个User对象:
➜ ~ jps
2809 StackAllocTest
2810 Jps
➜ ~ jmap -histo 2809
num #instances #bytes class name
----------------------------------------------
1: 524 87282184 [I
2: 1000000 16000000 StackAllocTest$User
在关闭逃避分析的情况下(-XX:-DoEscapeAnalysis),虽然在alloc方法中创建的User对象并没有逃逸到方法外部,但是还是被分配在堆内存中。也就说,如果没有JIT编译器优化,没有逃逸分析技术,正常情况下就应该是这样的。即所有对象都分配到堆内存中。
接下来,我们开启逃逸分析,再来执行下以上代码。
num #instances #bytes class name
----------------------------------------------
1: 524 101944280 [I
2: 6806 2093136 [B
3: 83619 1337904 StackAllocTest$User
从以上打印结果中可以发现,开启了逃逸分析之后(-XX:+DoEscapeAnalysis),在堆内存中只有8万多个StackAllocTest$User对象。也就是说在经过JIT优化之后,堆内存中分配的对象数量,从100万降到了8万。
除了以上通过jmap验证对象个数的方法以外,读者还可以尝试将堆内存调小,然后执行以上代码,根据GC的次数来分析,也能发现,开启了逃逸分析之后,在运行期间,GC次数会明显减少。正是因为很多堆上分配被优化成了栈上分配,所以GC次数有了明显的减少。
总结
所以,如果以后再有人问你:是不是所有的对象和数组都会在堆内存分配空间?
那么你可以告诉他:不一定,随着JIT编译器的发展,在编译期间,如果JIT经过逃逸分析,发现有些对象没有逃逸出方法,那么有可能堆内存分配会被优化成栈内存分配。但是这也并不是绝对的。就像我们前面看到的一样,在开启逃逸分析之后,也并不是所有User对象都没有在堆上分配。
逃逸分析部分转自:http://www.hollischuang.com/archives/2398