Percentile and Quantile Estimation of Big Data: The t-Digest。
kibana中Percentile Ranks,使用了t-Digest算法来算这些。从以下网页获知。
percentile-rank-aggregation
关于T-Digest
摘抄于
【Spark Summit East 2017】Spark中的草图数据和T-Digest
本讲义出自Erik Erlandson在Spark Summit East 2017上的演讲,大型数据集的草图概率分布的算法是现代数据科学的一个基本构建块,草图在可视化、优化数据编码、估计分位数以及数据合成等不同的应用中都有应用之地,T-Digest是一个通用的的草图的数据结构,并且非常适合于map-reduce模式,演讲中演示了Scala原生的T-Digest草图算法实现并证实了其在Spark的可视化展示、分位数估计以及数据合成的作用。

在kibana中,T-Digest的计算结果如下: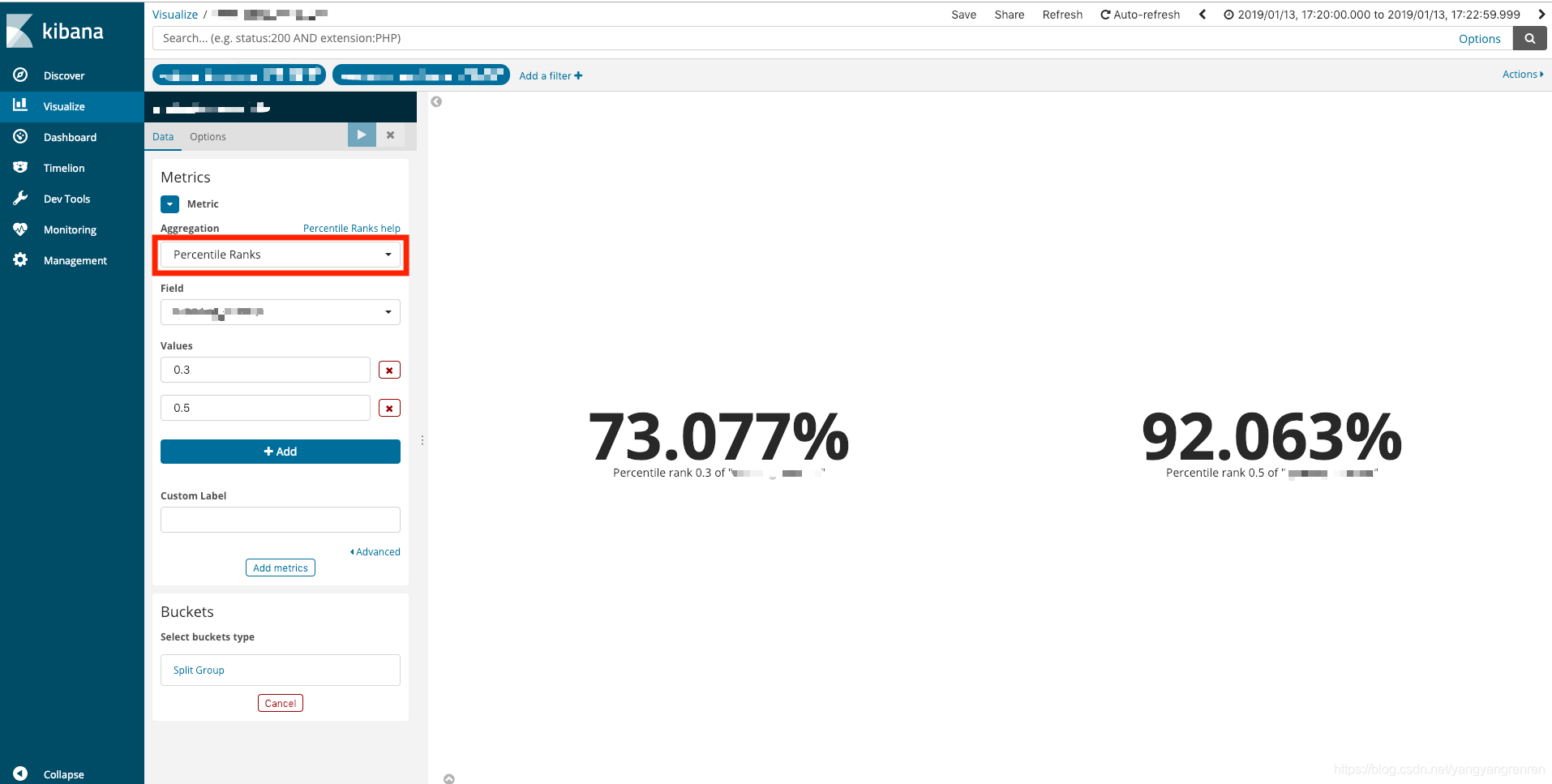
根据https://github.com/CamDavidsonPilon/tdigest
使用tdigest算法,验证结果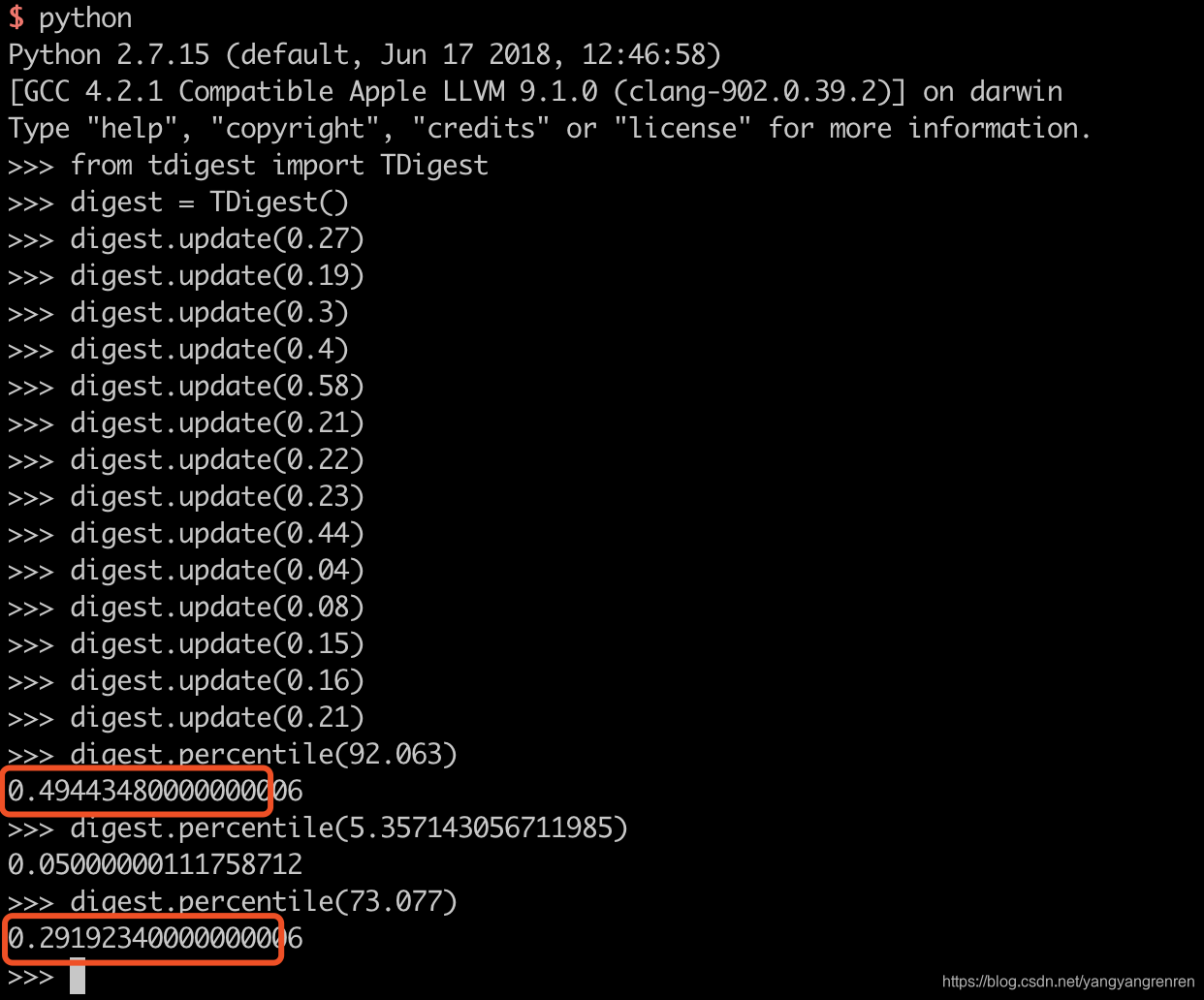
是一致的。
并非小于0.5的个数是13,占据总数14,比例是13/14=92.857%的值。
92.063%是Percentile Ranks的对应0.5计算结果。
版权声明:本文为yangyangrenren原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。