Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
摘要
本文研究只在image-level监督下学习语义分割。目前流行的解决方法是使用分类器生成的目标localization maps作为监督,致力于让localization maps捕捉更完整的目标内容。和以前只关注图像内(intra-image)的信息不同的是,我们设置了跨图像语义关系对综合目标图形挖掘的值。为了实现这一点,两个neural co-attentions被纳入分类器以互补地捕捉跨图像语义相似性和相差性。在实践中,给定一对训练图像,一个co-attention强制分类器识别co-attentive目标的共同语义,然而另一个,被称为对比co-attention,驱动分类器从其他非共同的对象中识别未共享的语义。这帮助分类器发现目标图案,更好地在图像区域内分割。除了促进目标图案的学习,co-attention可以利用其他相关图像的内容以改善localization map推理,因此最终优化语义分割学习。更本质上,我们的算法提供了一个融合的框架,可以很好地处理不同的WSSS设置,如(1)只用精确的image-level监督学习WSSS,(2)额外的简单single-label数据和(3)额外的噪音数据。它在所有这些设置上设置了最新技术,很好地展示了它的有效性和通用性。我们的方法在比赛中排名第一。
1 Introduction
最近,基于现代深度学习的语义分割模型通过海量的人工标注数据训练,得到了很好的表现。然而,全监督学习范例要求大量的复杂标注,受此限制。人们提出许多新方法在弱监督下实现语义分割,这些弱监督包括bounding boxes,scribbles,points和image-level标注等。其中,使用image-level标注实现语义分割是突出且诱人的,它要求用最少的标注,是本文的研究对象。
为了只用image-level标注解决WSSS任务,目前流行的方法是基于网络可视化技术,它们把用于分类的最显著区域激活。这些方法使用image-level标注训练分类网络,其class-activation maps派生出伪真值进一步监督pixel-level语义学习。然而,训练出来的分类器被证明过度关注有辨识度的部分,而不是整个目标,这一问题成了这一领域关注的重点。人们探索了多种解决方案,通常采用:图像级操作,如region hiding and erasing,拓展初始激活区域的regions growing策略,从深度特征收集多尺度内容以加强feature-level。
这些工作得到了更好的结果,证明了WSSS有分辨度的目标图案挖掘是重要的。然而,如Fig. 1所示,他们基本只使用单个图像的信息来做图案挖掘,忽略了弱监督数据之间的丰富的语义信息。例如,通过image-level标注,不仅可以识别每个单独图像的语义,也可以识别cross-image语义关系,即两张图像之间是否分享了某些语义,是不是也应该作为cues用于目标图案挖掘。基于此,我们不仅仅依赖于图像内的信息,我们进一步提出跨图像语义关系对综合目标图形挖掘的值,使得class-activation map推理更加有效(见Fig. 1(b-c))。尤其是,我们的分类器配备了可区分的co-attention机制,可解决训练图像对之间的语义同质性和差异理解。具体来说,分类器中学习了两种类型的co-attentions。前者旨在捕捉跨图像共同语义(cross-image common semantics),使得分类器更好地将共同的语义标签放在co-attention区域上。后者被称为对比co-attention,关注剩余的部分,不共享的语义,帮助分类器更好地分离不同目标的语义图案。这两个co-attentions以合作和互补的方式工作,共同使分类器更全面地理解目标图案。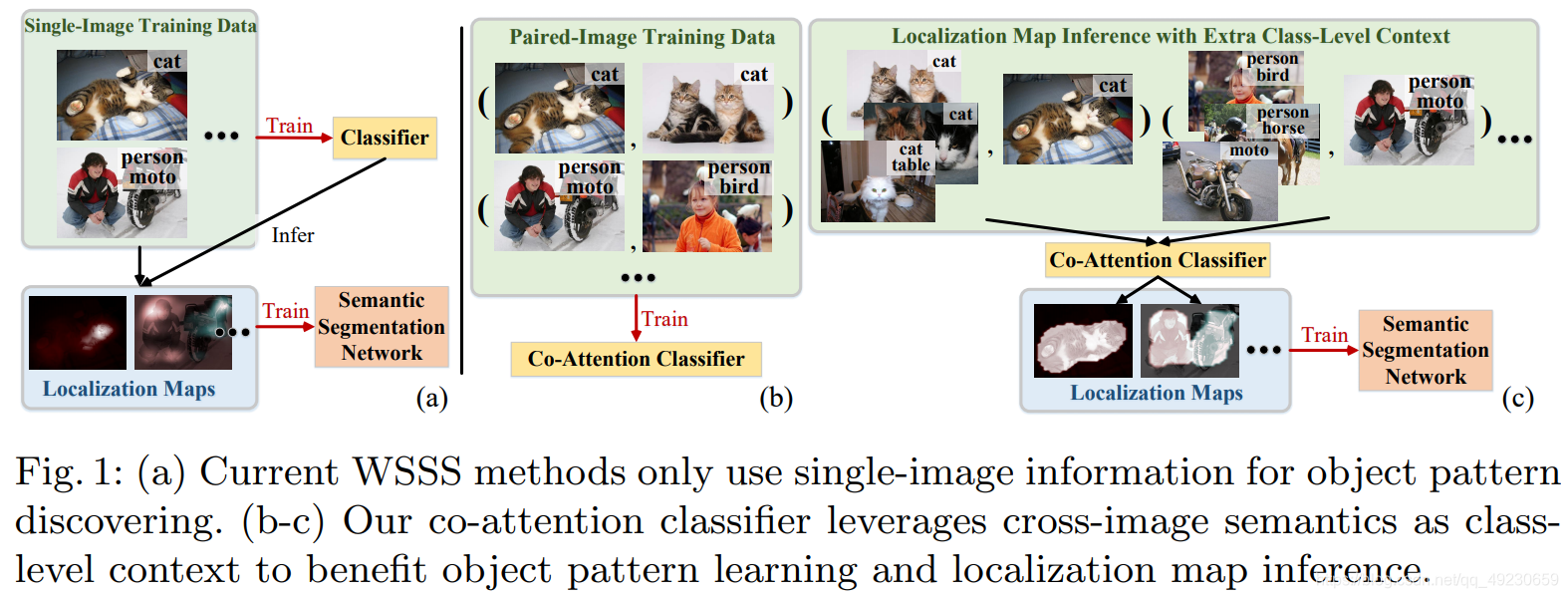
除了优化目标图案学习,我们的co-attention提供了一个高效的工具,用于推断精确的localization map(见Fig. 1©)。给定一张训练图像,一个相关图像的集合(即共享某种语义)被co-attention用来捕捉丰富的信息,生成更精确的localization maps。另一个优点是由于训练图像对的使用,我们基于分类学习范例的co-attention带来了一个有效的数据增广策略。总之,我们的co-attention在分类器训练阶段和localization map推理阶段促进了目标发掘。这使得我们可以获得更精确的伪pixel-level标注,以便用于最后语义分割学习。
我们的算法是一个统一且优雅的框架,很好地适用于不同的WSSS设置。最近,为了克服WSSS缺少人工额外标注的固有限制,我们努力从其他现有数据集中容易获得的简单单类数据或低廉的网络爬取数据中寻求额外的图像级监督。虽然他们在某种程度上改善了效果,但复杂的技术,如energy function optimization, heuristic constraints和curriculum learning需要处理域间隙和数据噪声,这些问题会限制效果。然而,由于分类器训练和目标图推理中成对图像数据的使用,我们的方法对噪音有很好的宽容度。另外,我们的方法也自然地处理了域间距,因为co-attention有效地解决了domain-shared object pattern learning并实现了领域适应作为co-attention参数学习的一部分。我们做了相关实验,获得了不错的结果。
我们的contributions有以下三点。(1)我们得到了跨图像语义相关性对于完整目标图案学习以及对象位置推断的值,这是通过在配对训练样本上工作的co-attention分类器实现的。(2)我们的co-attention分类器用更加互补的方式挖掘语义cues。除了单图像语义外,它还分别通过co-attention和对比的co-attention从跨图像语义相似性和差异中挖掘互补监督。(3)我们的方法足够通用,可以通过精确的图像级监督学习 WSSS,或者使用额外的简单单标签,甚至是嘈杂的网络爬虫数据。它优雅地解决了不同 WSSS 设置的固有挑战,并稳定地显示出期望的结果。
2 Related Work
3 Methodology
Problem Setup. 在这里,我们遵循当前流行的 WSSS pipeline:给定一组带有图像级标签的训练图像,首先训练分类网络以发现相应的有辨识度的目标区域。训练样本上得到的目标localization maps被提炼为伪掩码,以进一步监督语义分割网络的学习。
Our Idea. 与之前单独处理每个训练图像的大多数工作不同,我们探索跨图像语义关系作为类级别上下文,以更全面地理解目标图案。为实现这一目的,我们设计了两个neural co-attention。一个驱动分类器从co-attention的目标区域学习通用语义,而另一个强制分类器关注其余目标进行非共享语义分类。
3.1 Co-attention Classification Network
我们把训练数据记为I = { ( I n , l n ) } \mathcal{I}=\{(I_n,l_n)\}I={(In,ln)},其中I n I_nIn是第n张训练图像,l n ∈ { 0 , 1 } K l_n\in\{0,1\}^Kln∈{0,1}K是K个语义类别相应的的真实图像标注。如Fig. 2(a)所示,图像对,即( I m , I n ) (I_m,I_n)(Im,In)作为训练分类器的样本,采样自I \mathcal{I}I。在把I m , I n I_m,I_nIm,In喂入分类器的卷积embedding部分之后,得到相应的特征图,F m ∈ R C × H × W F_m\in\mathbb{R}^{C×H×W}Fm∈RC×H×W和F n ∈ R C × H × W F_n\in\mathbb{R}^{C×H×W}Fn∈RC×H×W。
我们首先分别把F m , F n F_m,F_nFm,Fn送入class-aware fully convolutional layer φ ( ⋅ ) \varphi(\cdot)φ(⋅)生成class-aware activation maps,即S m = φ ( F m ) ∈ R K × H × W S_m=\varphi(F_m)\in\mathbb{R}^{K×H×W}Sm=φ(Fm)∈RK×H×W和S n = φ ( F n ) ∈ R K × H × W S_n=\varphi(F_n)\in\mathbb{R}^{K×H×W}Sn=φ(Fn)∈RK×H×W。然后,我们在S m , S n S_m,S_nSm,Sn上使用GAP得到I m , I n I_m,I_nIm,In的class score向量s m ∈ R K s_m\in\mathbb{R}^Ksm∈RK和s n ∈ R K s_n\in\mathbb{R}^Ksn∈RK。最后,sigmoid cross entropy(CE) loss被用来作为监督:
L b a s i c m n ( ( I m , I n ) , ( l m , l n ) ) = L C E ( s m , l m ) + L C E ( s n , l n ) , = L C E ( G A P ( φ ( F m ) ) , l m ) + L C E ( G A P ( φ ( F n ) ) , l n ) \mathcal{L}_{basic}^{mn}((I_m,I_n),(l_m,l_n))=\mathcal{L}_{CE}(s_m,l_m)+\mathcal{L}_{CE}(s_n,l_n), \\=\mathcal{L}_{CE}(GAP(\varphi(F_m)),l_m)+\mathcal{L}_{CE}(GAP(\varphi(F_n)),l_n)Lbasicmn((Im,In),(lm,ln))=LCE(sm,lm)+LCE(sn,ln),=LCE(GAP(φ(Fm)),lm)+LCE(GAP(φ(Fn)),ln)
到目前为止,分类器是以标准方式学习的,即仅使用个体图像信息进行语义学习。我们可以像一些工作一样直接用activation maps监督下一阶段的语义分割学习。然而,我们的分类器额外使用了co-attention机制进一步挖掘cross-image语义,以最终更好地定位目标。
Co-Attention for Cross-Image Common Semantics Mining. 我们的co-attention同时参与了两张图像,即I m , I n I_m,I_nIm,In,捕捉他们的相关性。我们首先计算F m , F n F_m,F_nFm,Fn的亲和矩阵P PP:
P = F m T W P F n ∈ R H W × H W P=F_m^TW_PF_n\in\mathbb{R}^{HW×HW}P=FmTWPFn∈RHW×HW
其中F m ∈ R C × H W F_m\in\mathbb{R}^{C×HW}Fm∈RC×HW和F n ∈ R C × H W F_n\in\mathbb{R}^{C×HW}Fn∈RC×HW被展平成矩阵格式,W P ∈ R C × C W_P\in\mathbb{R}^{C×C}WP∈RC×C是一个可学习的矩阵。亲和矩阵P PP储存了F m , F n F_m,F_nFm,Fn中所有位置对的similarity scores,即P PP的第( i , j ) (i,j)(i,j)个元素提供了F m F_mFm中第i个位置和F n F_nFn中第j个位置之间的similarity。
然后按列对P PP进行归一化,以针对F n F_nFn上每个位置得出F m F_mFm的attention maps,按行归一化则对F m F_mFm上每个位置得出F n F_nFn的attention maps:
A m = s o f t m a x ( P ) ∈ [ 0 , 1 ] H W × H W , A n = s o f t m a x ( P T ) ∈ [ 0 , 1 ] H W × H W A_m=softmax(P)\in[0,1]^{HW×HW},A_n=softmax(P^T)\in[0,1]^{HW×HW}Am=softmax(P)∈[0,1]HW×HW,An=softmax(PT)∈[0,1]HW×HW
其中softmax按列进行。通过这种方式,A n , A m A_n,A_mAn,Am在他们的列中储存co-attention。然后,我们就能够根据F n ( F m ) F_n(F_m)Fn(Fm)的每个位置求得F m ( F n ) F_m(F_n)Fm(Fn)的总attention:
F m m ∩ n = F n A n ∈ R C × H × W , F n m ∩ n = F m A m ∈ R C × H × W F_m^{m\cap n}=F_nA_n\in\mathbb{R}^{C×H×W}, F_n^{m\cap n}=F_mA_m\in\mathbb R^{C×H×W}Fmm∩n=FnAn∈RC×H×W,Fnm∩n=FmAm∈RC×H×W
其中F m m ∩ n , F n m ∩ n F_m^{m\cap n},F_n^{m\cap n}Fmm∩n,Fnm∩nreshape成R C × W × H \mathbb R^{C×W×H}RC×W×H。co-attention特征F m m ∩ n F_m^{m\cap n}Fmm∩n通过F n F_nFn求出,保留了F m , F n F_m,F_nFm,Fn之间的共同语义,定位了F m F_mFm的共享目标。因此,我们可以预料到只有共同语义l m ∩ l n l_m\cap l_nlm∩ln可以安全地从F m m ∩ n F_m^{m\cap n}Fmm∩n中导出,F n m ∩ n F_n^{m\cap n}Fnm∩n也是如此。这种基于co-attention的通用语义分类可以让分类器更完整、更准确地理解目标图案。
更直观的表示请参考Fig. 2,其中I m I_mIm包含了桌子和人,I n I_nIn包含了牛和人。由于co-attention本质上是I m , I n I_m,I_nIm,In之间所有位置对之间的亲和力(affinity)计算,因此co-attention features只会保留共同目标人的语义,即F m m ∩ n , F n m ∩ n F_m^{m\cap n},F_n^{m\cap n}Fmm∩n,Fnm∩n(见Fig. 2(b))。如果我们把F m m ∩ n , F n m ∩ n F_m^{m\cap n},F_n^{m\cap n}Fmm∩n,Fnm∩n喂入class-aware全卷积层φ \varphiφ,生成的class-aware activation maps,即S m m ∩ n = φ ( F m m ∩ n ) ∈ R K × H × W S_m^{m\cap n}=\varphi(F_m^{m\cap n})\in\mathbb R^{K×H×W}Smm∩n=φ(Fmm∩n)∈RK×H×W和S n m ∩ n = φ ( F n m ∩ n ) ∈ R K × H × W S_n^{m\cap n}=\varphi(F_n^{m\cap n})\in\mathbb R^{K×H×W}Snm∩n=φ(Fnm∩n)∈RK×H×W,可以在I m , I n I_m,I_nIm,In中定位共同目标人。在GAP之后,被预测的语义类别(分数)s m m ∩ n ∈ R K s_m^{m\cap n}\in\mathbb R^Ksmm∩n∈RK和s n m ∩ n ∈ R K s_n^{m\cap n}\in\mathbb R^Ksnm∩n∈RK应该是I m , I n I_m,I_nIm,In的共同语义标签l m ∩ l n l_m\cap l_nlm∩ln,人。 通过co-attention的计算,不只是人身上最有辨识度的部分人脸,人的其他部分像胳膊和腿也在F m m ∩ n F_m^{m\cap n}Fmm∩n和F n m ∩ n F_n^{m\cap n}Fnm∩n(见Fig. 2(b))中高亮。但我们设置一般的类别标签,如人作为监督信号,分类器将会意识到F m m ∩ n F_m^{m\cap n}Fmm∩n和F n m ∩ n F_n^{m\cap n}Fnm∩n保存的语义是相关的,且会被识别为人。因此,计算两个相关图像的co-attention明确地帮助分类器关联语义标签和相应的目标区域,并更好地理解不同目标部分之间的关系。它基本上充分利用了训练数据中的上下文。
通过co-attention的计算,不只是人身上最有辨识度的部分人脸,人的其他部分像胳膊和腿也在F m m ∩ n F_m^{m\cap n}Fmm∩n和F n m ∩ n F_n^{m\cap n}Fnm∩n(见Fig. 2(b))中高亮。但我们设置一般的类别标签,如人作为监督信号,分类器将会意识到F m m ∩ n F_m^{m\cap n}Fmm∩n和F n m ∩ n F_n^{m\cap n}Fnm∩n保存的语义是相关的,且会被识别为人。因此,计算两个相关图像的co-attention明确地帮助分类器关联语义标签和相应的目标区域,并更好地理解不同目标部分之间的关系。它基本上充分利用了训练数据中的上下文。
直观地,对于基于co-attention的公共语义分类,I m , I n I_m,I_nIm,In共享的标签l m ∩ l n l_m\cap l_nlm∩ln用作监督学习:
L c o − a t t m n ( ( I m , I n ) , ( l m , l n ) ) = L C E ( s m m ∩ n , l m ∩ l n ) = L C E ( G A P ( φ ( F m m ∩ n ) ) , l m ∩ l n ) + L C E ( G A P ( φ ( F n m ∩ n ) ) , l m ∩ l n ) \mathcal{L}_{co-att}^{mn}((I_m,I_n),(l_m,l_n))=\mathcal L_{CE}(s_m^{m\cap n},l_m\cap l_n) \\ =\mathcal L_{CE}(GAP(\varphi(F_m^{m\cap n})),l_m\cap l_n)+\mathcal L_{CE}(GAP(\varphi(F_n^{m\cap n})),l_m\cap l_n)Lco−attmn((Im,In),(lm,ln))=LCE(smm∩n,lm∩ln)=LCE(GAP(φ(Fmm∩n)),lm∩ln)+LCE(GAP(φ(Fnm∩n)),lm∩ln)
Contrastive Co-Attention for Cross-Image Exclusive Semantics Mining. 除了上述探索跨图像共同语义的co-attention之外,我们还提出了一种对比的co-attention来挖掘配对图像之间的语义差异。co-attention和对比的co-attention互补地帮助分类器更好地理解目标的概念。
正如Fig. 2(a)所示,对于I m , I n I_m,I_nIm,In,我们首先从它们的co-attention特征中推导出与类别无关的co-attention,co-attention特征即F m m ∩ n F_m^{m\cap n}Fmm∩n和F n m ∩ n F_n^{m\cap n}Fnm∩n:
B m m ∩ n = σ ( W B F m m ∩ n ) ∈ [ 0 , 1 ] H × W , B n m ∩ n = σ ( W B F n m ∩ n ) ∈ [ 0 , 1 ] H × W B_m^{m\cap n}=\sigma(W_BF_m^{m\cap n})\in[0,1]^{H×W},B_n^{m\cap n}=\sigma(W_BF_n^{m\cap n})\in[0,1]^{H×W}Bmm∩n=σ(WBFmm∩n)∈[0,1]H×W,Bnm∩n=σ(WBFnm∩n)∈[0,1]H×W
其中σ ( ⋅ ) \sigma(\cdot)σ(⋅)是sigmoid激活函数,参数矩阵W B ∈ R 1 × C W_B\in\mathbb R^{1×C}WB∈R1×C学习公共语义集合,由一个1 × 1 1×11×1的卷积层生成。B m m ∩ n , B n m ∩ n B_m^{m\cap n},B_n^{m\cap n}Bmm∩n,Bnm∩n是类别无关的,并突出显示I m , I n I_m,I_nIm,In的全部共同目标区域,基于我们导出的对比的co-attentions:
A m m \ n = 1 − B m m ∩ n ∈ [ 0 , 1 ] H × W , A n n \ m = 1 − B n m ∩ n ∈ [ 0 , 1 ] H × W A_m^{m\n}=1-B_m^{m\cap n}\in[0,1]^{H×W},A_n^{n\m}=1-B_n^{m\cap n}\in[0,1]^{H×W}Amm\n=1−Bmm∩n∈[0,1]H×W,Ann\m=1−Bnm∩n∈[0,1]H×W
I m I_mIm的对比的co-attention A m m \ n A_m^{m\n}Amm\n,正如其上标所示,解决那些仅属于I m I_mIm的非共享目标区域,而不是I n I_nIn的,A n n \ m A_n^{n\m}Ann\m也是如此。然后我们就得到了对比的co-attention特征,即每张图像中未共享的语义:
F m m \ n = F m ⊗ A m m \ n ∈ R C × H × W , F n n \ m = F n ⊗ A n n \ m ∈ R C × H × W F_m^{m\n}=F_m\otimes A_m^{m\n}\in\mathbb R^{C×H×W},F_n^{n\m}=F_n\otimes A_n^{n\m}\in\mathbb R^{C×H×W}Fmm\n=Fm⊗Amm\n∈RC×H×W,Fnn\m=Fn⊗Ann\m∈RC×H×W
‘⊗ \otimes⊗’表示元素点乘,其中attention的值沿通道维度复制。然后,我们依次得到class-aware activation maps,即S m m \ n = φ ( F m m \ n ) ∈ R K × H × W , S n n \ m = φ ( F n n \ m ) ∈ R K × H × W S_m^{m\n}=\varphi(F_m^{m\n})\in\mathbb R^{K×H×W},S_n^{n\m}=\varphi(F_n^{n\m})\in\mathbb R^{K×H×W}Smm\n=φ(Fmm\n)∈RK×H×W,Snn\m=φ(Fnn\m)∈RK×H×W,和semantic scores,即s m m \ n = G A P ( S m m \ n ) ∈ R K , s n n \ m = G A P ( S n n \ m ) ∈ R K s_m^{m\n}=GAP(S_m^{m\n})\in\mathbb R^K,s_n^{n\m}=GAP(S_n^{n\m})\in\mathbb R^Ksmm\n=GAP(Smm\n)∈RK,snn\m=GAP(Snn\m)∈RK。至于s m m \ n , s n n \ m s_m^{m\n},s_n^{n\m}smm\n,snn\m,他们去识别非共享目标的类别,即l m \ l n , l n \ l m l_m\l_n,l_n\l_mlm\ln,ln\lm。
与研究共同语义作为促进目标图案挖掘的信息线索的co-attention相比,对比co-attention解决了配对图像之间语义差异的互补知识。Fig. 2(b)展示了一个直观的例子。在计算了I m , I n I_m,I_nIm,In的对比co-attention之后,桌子和牛这两个在它们原始图像中独特的类别被高亮。基于对比co-attention特征,即F m m \ n , F n n \ m F_m^{m\n},F_n^{n\m}Fmm\n,Fnn\m,分类器需要准确识别桌子和牛。当共同的目标被对比co-attention过滤掉时,分类器有机会更多地关注其余图像区域并更有意识地挖掘未共享的语义。这也有助于分类器更好地区分不同目标的语义,因为共享目标和非共享目标的语义被对比co-attention辨别。举个例子,如果牛的一些部分被错误地识别为和人相关,对比co-attention将会把这些部分丢弃到F n n \ m F_n^{n\m}Fnn\m中。然而,F n n \ m F_n^{n\m}Fnn\m中的其余语义可能不足以识别牛。这将强制分类器更好地区分不同的目标。
对于基于非共享语义分类的对比co-attention,监督loss为: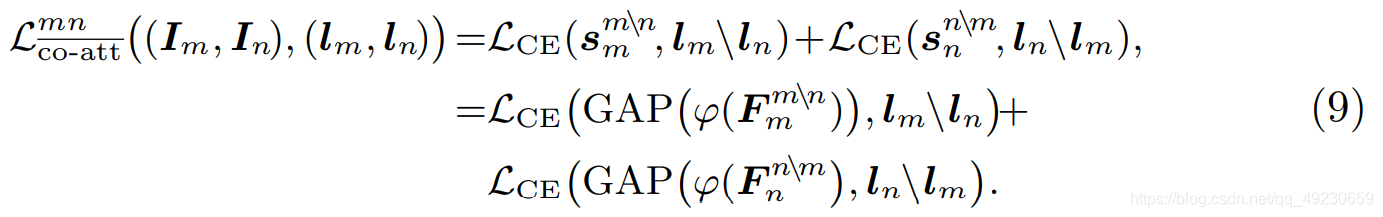
‘\’指的是l n \ l m = l n − l n ∩ l m l_n\l_m=l_n-l_n\cap l_mln\lm=ln−ln∩lm。
More In-Depth Discussion. 人们可以从辅助任务学习的角度解释我们的co-attention分类器,这是在自监督学习领域通过探索固有数据结构中的辅助任务来提高数据效率和鲁棒性的研究。在我们的例子中,我们探索了两个辅助任务,即从图像对中预测共享和不共享的语义,而不是在传统WSSS方法中广泛研究的单图像语义识别任务,以从弱监督中充分挖掘监督信号。通过关注(对比)co-attention特征,而不是仅依赖图像内信息,可以驱动分类器更好地理解跨图像语义(见Fig. 2©)。除此之外,这种策略具有图像共同分割(image co-segmentation)的精神。 由于给出了训练集的图像级语义,关于某些图像共享或不共享某些语义的知识应该用作提示或监督信号,以更好地定位相应的目标。 由于使用配对样本,我们基于co-attention的学习pipeline还提供了一种有效的数据增强策略,其数量接近单个训练图像数量的平方。
3.2 Co-Attention Classifier Guided WSSS Learning
Training Co-Attention Classifier. 我们co-attention分类器整体训练loss由三部分组成: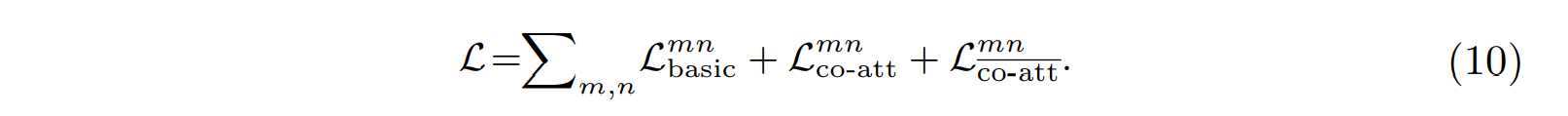
在我们所有的实验中,不同损失项的系数都设置为1。在训练过程中,为了完全利用co-attention去挖掘共同语义,我们用两张图像(I m , I n I_m,I_nIm,In)作为样本,这两张图像至少有一个共同类别,即l m ∩ l n ≠ 0 l_m\cap l_n\neq0lm∩ln=0。
Generating Object Localization Maps. 一旦我们的图像分类器被训练后,我们将其应用于训练数据I = { ( I n , l n ) } n \mathcal I=\{(I_n,l_n)\}_nI={(In,ln)}n以生成相应的对象定位图,这对于语义分割网络训练至关重要。 我们探索了两种不同的策略来生成定位图。
- Single-round feed-forward prediction,单独处理每张训练图像。对于每张训练图像I n I_nIn,运行分类器并直接使用其class-aware activation map(即S n ∈ R K × H × W S_n\in\mathbb R^{K×H×W}Sn∈RK×H×W)作为对象定位图 Ln,就像大多数以前基于网络可视化的方法所做的那样。
- Multi-round co-attentive prediction with extra reference information,这是通过考虑来自其他相关训练图像的额外信息来实现的(见Fig. 1( c))。具体来讲,给定一个训练图像I n I_nIn和相关联的标签向量l n l_nln,以class-wise manner生成它的定位图L n L_nLn。对于标记在I n I_nIn的每个语义类别k ∈ { 1 , ⋯ , K } k\in\{1,\cdots,K\}k∈{1,⋯,K},即l n , k = 1 l_{n,k}=1ln,k=1,l n , k l_{n,k}ln,k是l n l_nln的第k个元素,我们从I \mathcal II中抽样相关图像的集合R = { I r } r \mathcal R=\{I_r\}_rR={Ir}r,它也由标注k进行标注,即l r , k = 1 l_{r,k}=1lr,k=1。然后我们从每个相关图像I r ∈ R I_r\in\mathcal RIr∈R到I n I_nIn计算co-attentive特征F n m ∩ r F_n^{m\cap r}Fnm∩r,得到基于co-attention的class-aware activation map S n m ∩ r S_n^{m\cap r}Snm∩r。给定了R \mathcal RR中所有的class-aware activation map { S n m ∩ r } r \{S_n^{m\cap r}\}_r{Snm∩r}r,它们被整合以仅针对第 k 类去推断定位图,即L n , k = 1 ∣ R ∣ ∑ r ∈ R S n , k m ∩ r L_{n,k}=\frac{1}{|\mathcal R|}\sum_{r\in\mathcal R}S_{n,k}^{m\cap r}Ln,k=∣R∣1∑r∈RSn,km∩r。这里L n , k ∈ R H × W L_{n,k}\in\mathbb R^{H×W}Ln,k∈RH×W和S n , k ( ⋅ ) ∈ R H × W S_{n,k}^{(\cdot)}\in\mathbb R^{H×W}Sn,k(⋅)∈RH×W表示了L n ∈ R K × H × W L_n\in\mathbb R^{K×H×W}Ln∈RK×H×W和S n ( ⋅ ) ∈ R K × H × W S_n^{(\cdot)}\in\mathbb R^{K×H×W}Sn(⋅)∈RK×H×W的第k个channel的特征图。‘∣ ⋅ ∣ |\cdot|∣⋅∣’计算元素。在推断了I n I_nIn的所有注释的语义的类别的定位图之后,我们得到L n L_nLn。
我们在实验中研究了我们这两个定位图生成策略,后者更好,因为它同时使用图像内和图像间语义进行目标推理,并共享训练阶段的相似数据分布。需要注意的是,对比co-attention在这里并没有使用。这是由于对比co-attention特征来自于它的原始图像,在分类器训练时对于增强特征表示学习是有效的,然而对于定位图推理(受跨图像信息限制)没有帮助。相关实验可以在第4章第5节找到。
Learning Semantic Segmentation Network. 在得到了高质量定位图之后,我们为所有训练样本I \mathcal II生成了伪标签,可以用来训练语义分割网络。对于伪真值的生成,我们使用目前最流行的pipeline,利用定位图提取目标类别cues,采用saliency maps得到背景cues。对于语义分割网络,参考一些工作中所说的,我们选择DeepLab-LargeFOV。
Learning with Extra Simple Single-Label Images. 一些最近的工作是从其他现有数据集中探索更简单的单标签图像,以进一步提高 WSSS。尽管需要令人印象深刻的特定网络设计,由于额外使用的数据与目标复杂多标签数据集之间的域差距问题(domain gap),如PASCAL VOC2012。有趣的是,我们基于co-attention的 WSSS 算法提供了一种替代方案,可以自然地解决领域差距的挑战。我们再来回顾一下co-attention的计算,当I m , I n I_m,I_nIm,In来自不同的domain时,参数矩阵W P W_PWP在本质上学习将它们映射到一个统一的公共语义空间,并且co-attentive特征可以捕获域共享语义。因此,根据这样的设置,我们为W P W_PWP学习了三个不同的参数矩阵,对应着I m , I n I_m,I_nIm,In来自这样3种情况:(1)目标语义分割域,(2)单标签图像域,(3)两个不同的域。因此,作为co-attention学习的一部分,可以有效地实现域适应。我们在4.2节做了相关实验。
Learning with Extra Web Images. 目前一些其他的解决弱监督语义分割方法,即利用网络图像作为额外的训练样本。虽然成本低廉,但网络数据基本都有噪音。为了解决这一问题,以前的工作提出了一些有效但复杂的解决方案,如multi-stage training和self-paced learning。我们基于co-attention的WSSS算法可以轻松扩展到此设置并优雅地解决数据噪声。由于我们的co-attention分类器是用成对的图像训练的,而不是以前的方法只依赖于每个图像,我们的模型提供了更强大的训练范式。 此外,在定位图推理过程中,考虑了一组额外的相关图像,提供了更全面和准确的cue,进一步提高了鲁棒性。 我们在4.3节通过实验证明了我们的方法这种设置的效果。
**Network Configuration. ** 根据惯例,我们的图像分类器基于ImageNet预训练的VGG-16.对于VGG-16网络,最后3层全连接层被三个512通道3×3大小的卷积层代替。对于语义分割网络,为了和目前的最优方法公平对比,我们采用ResNet-101版本的Deeplab-LargeFOV结构。
Training Phases of the Co-Attention Classifier and Semantic Segmentation Network. 一些其他训练细节。
Inference Phase of the Semantic Segmentation Network. 其他特性。