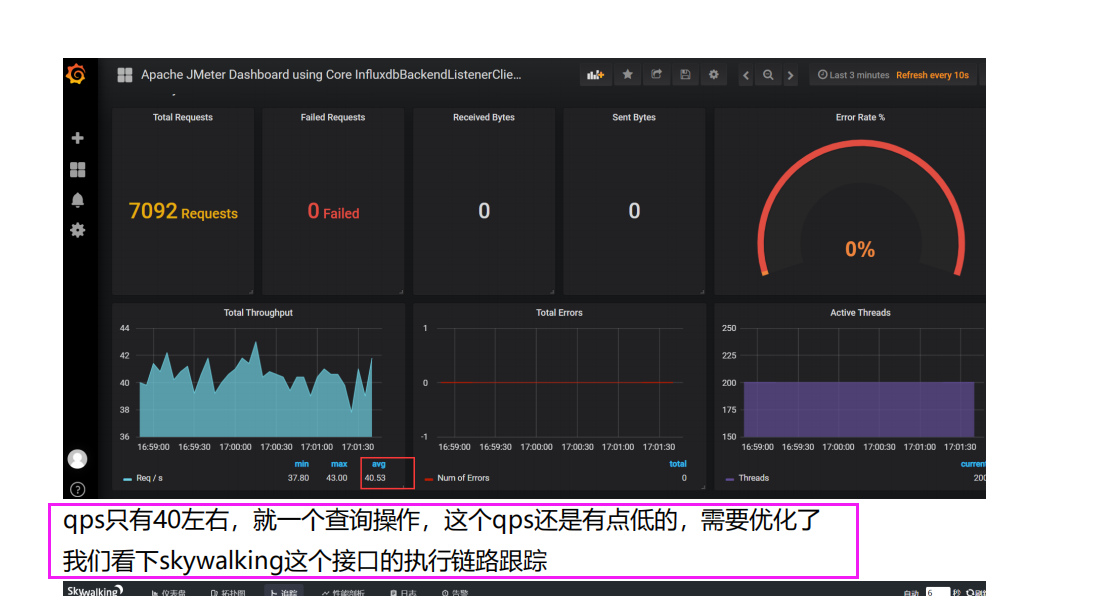
1.Jmeter 压测对应接口(1.压测添加购物车接口 2.压测查询购物车 3.全链路压测创建订单) 查询压测计划以及压测报告做分析 ,如何提升系统的并发qps
2.压测环境
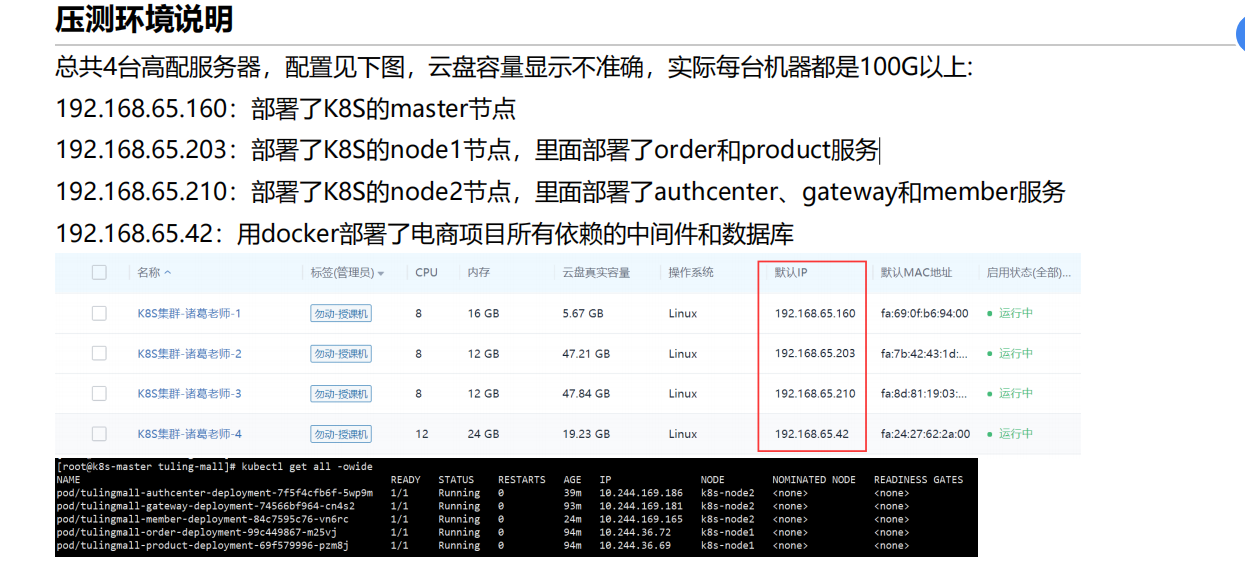
我们此时是单节点环境压测,我可以单压一个pod,看到这个pod的qps,我就可以估算比如说你到时候部署5台pod的qps是多少,细节还得边亚边看
我们此时的环境是100个用户线程 每一个线程 往服务端快速的发送1w个请求
这就是我们的压测计划 来看看我们这边各个环境的变化
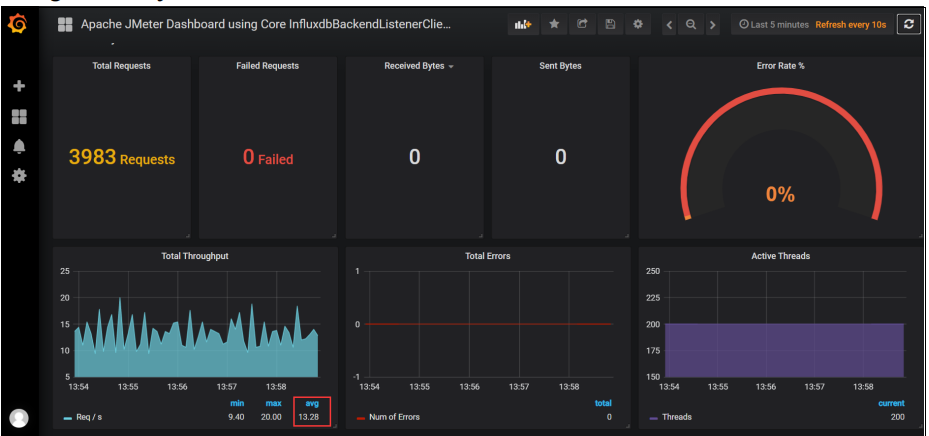
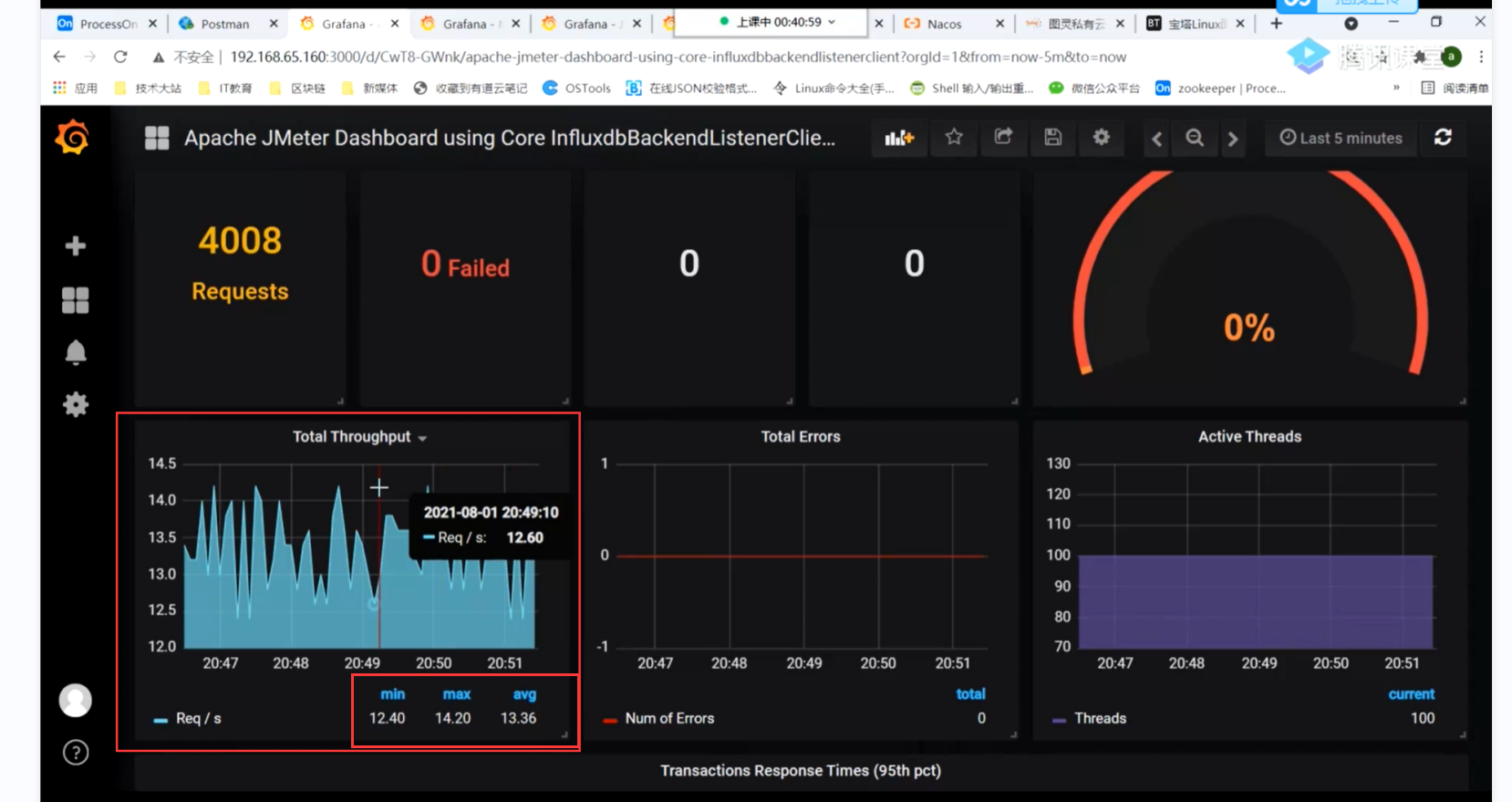
我们通过jmeter的压测的数据发送到grafana 可以看到jmeter压测的平均qps
当然也可以通过我们的Jmeter来看实时的
1.压测添加购物车接口--分析压测过程中出现的问题以及解决思路
在压测过程中我们需要注意的是
1.jmeter的压测报告
2.grafana的数据 qps (收集jmeter)
2. 各个web应用的jvm情况
3. 包括我们redis的监控情况
4. 检测服务器的cpu使用率 内存信息 包括你的带宽使用 磁盘使用率 检测你具体的操作系统的资源情况
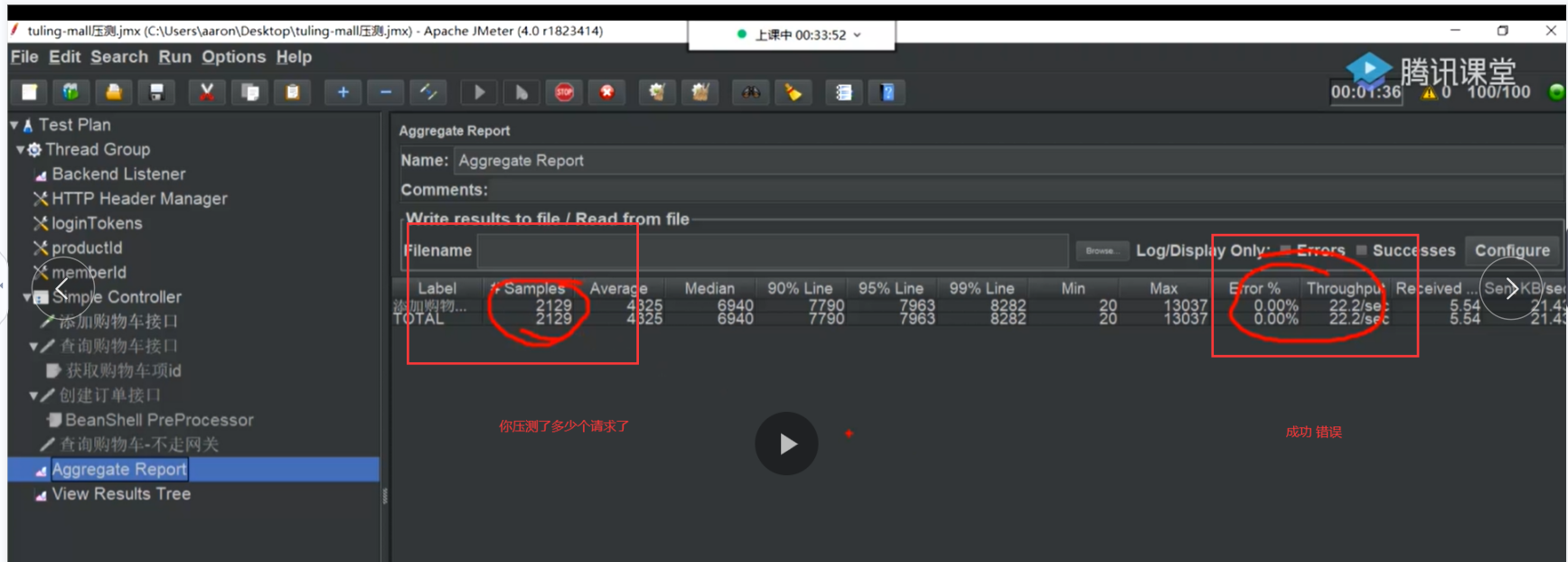
压我们的添加购物车 的接口 来看看我们的上述的执行情况,我们现在只压单节点pod,短时间内的压测,让qps稳定下来我就开始分析问题
压我们的添加购物车 的接口 时候qps低只有13,我们此时需要定位问题
先用top 基于服务器的监控资源查看cpu,发现web,以及网关的cpu使用率正常
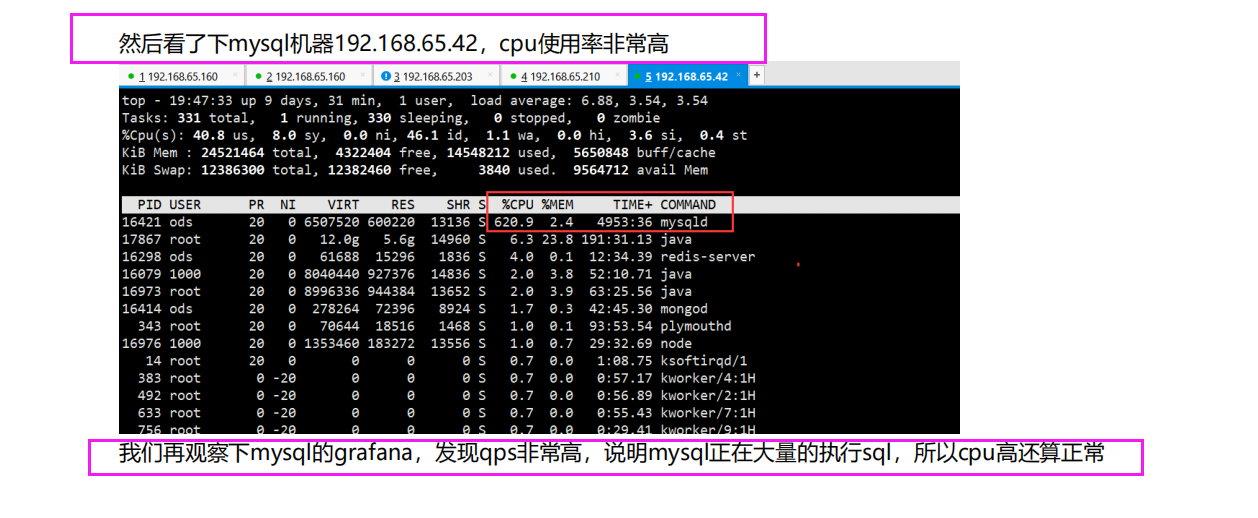
但是此时数据库所在的服务器cpu飙升
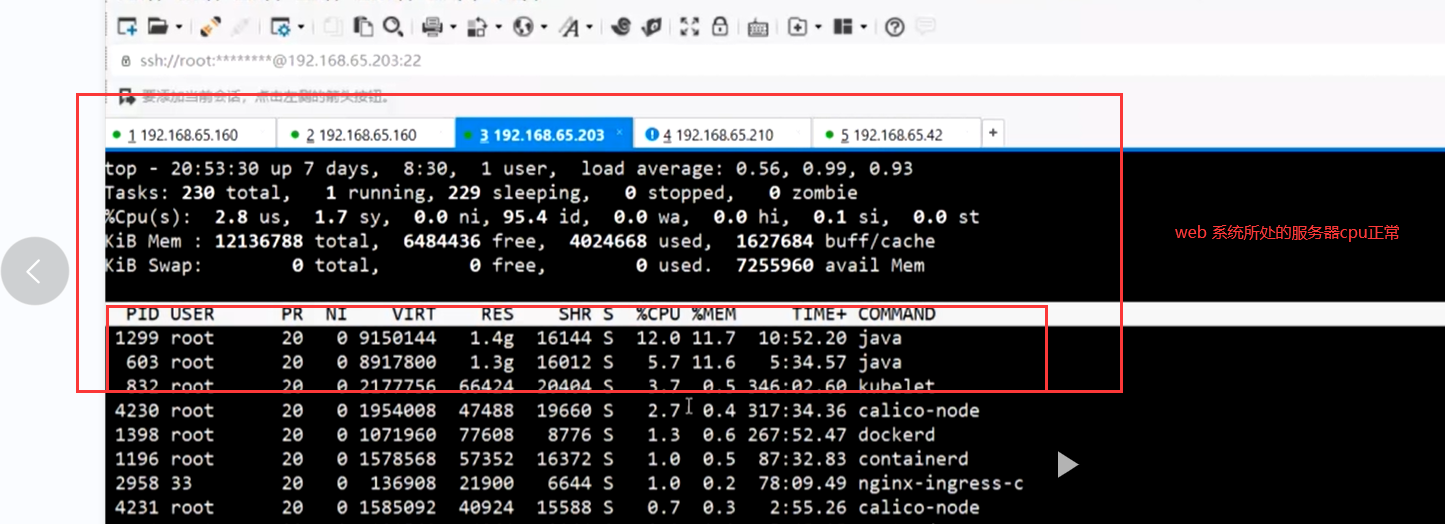
但是mysql 所处的服务器cpu到1100%了
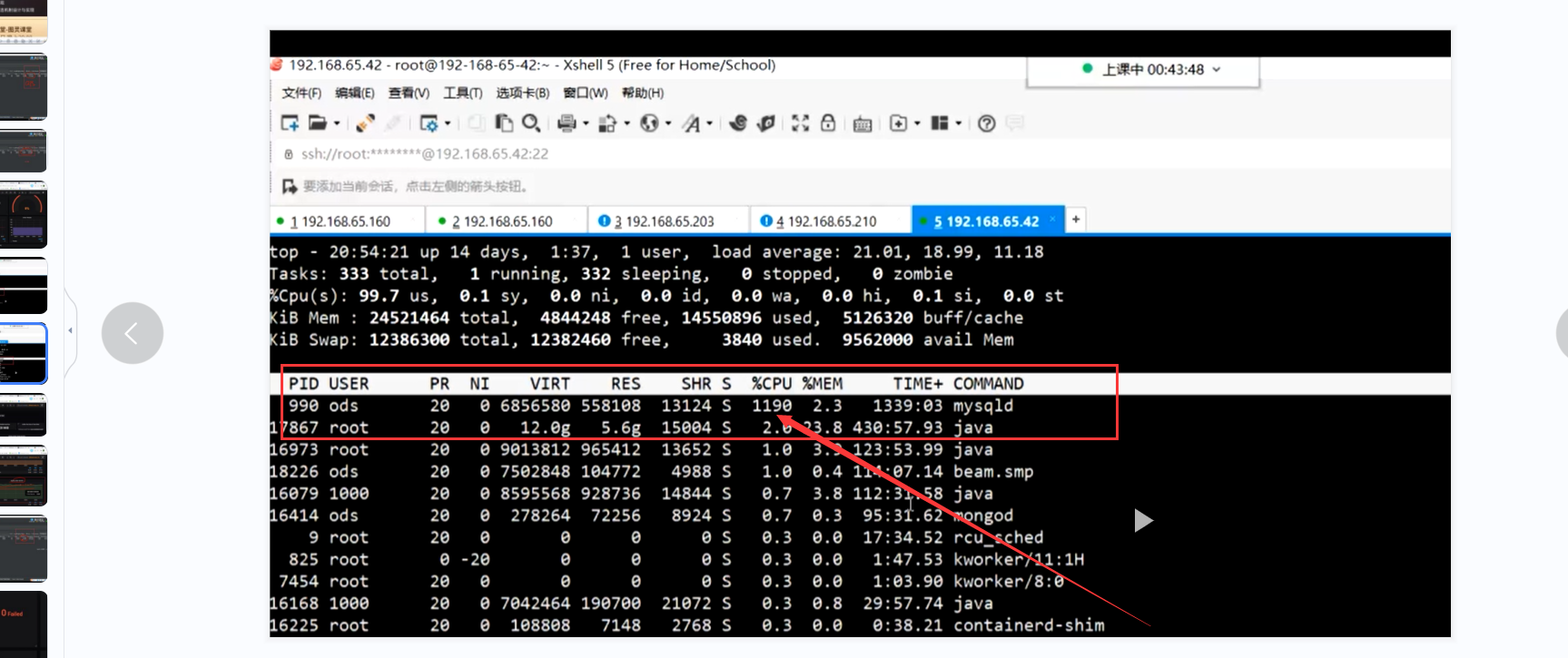
发现问题 此时数据库cpu严重超载,再继续压测的话数据库就直接宕机了
可能数据库这边有性能问题 我这边需要做优化,通过grafana监控mysql得知
可能有慢查询,并且mysql此时的qps才100多
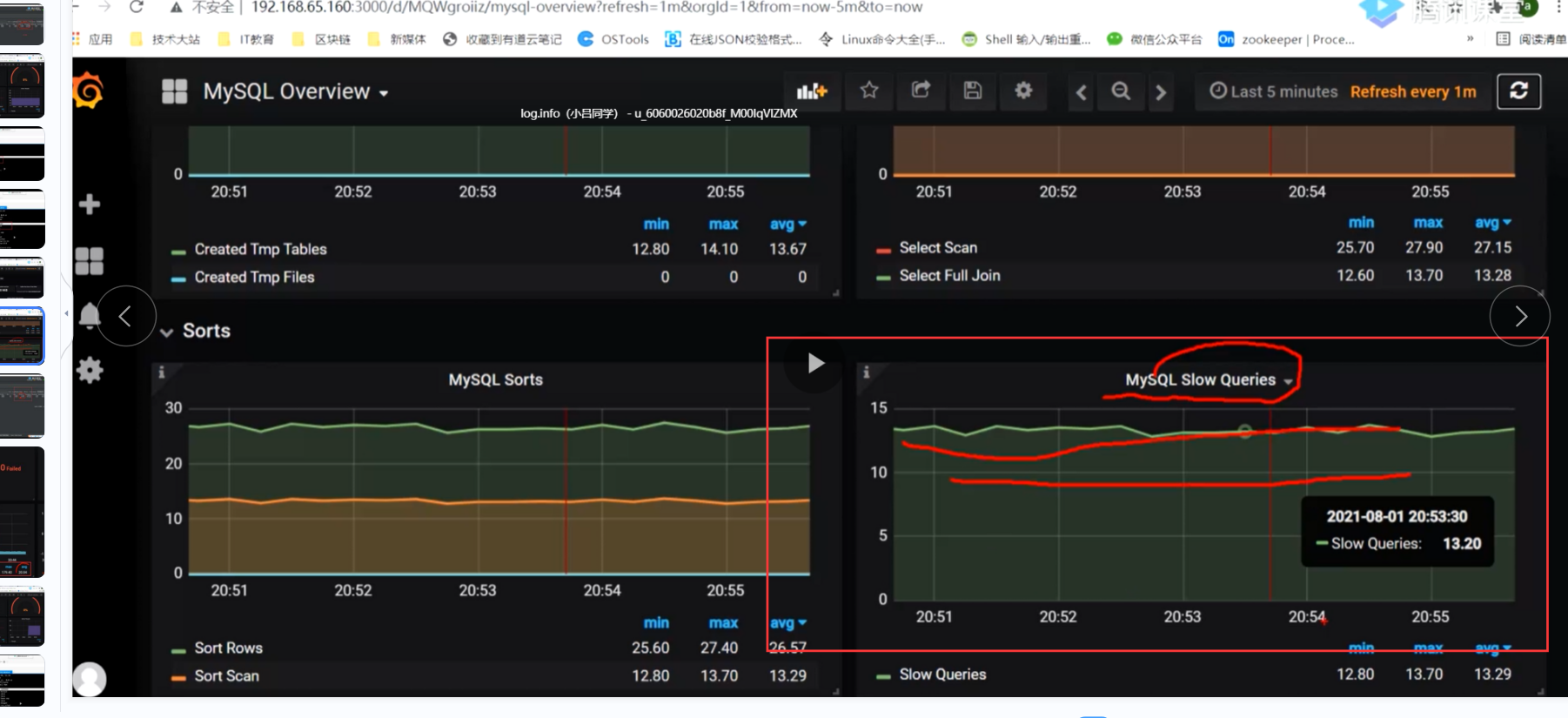
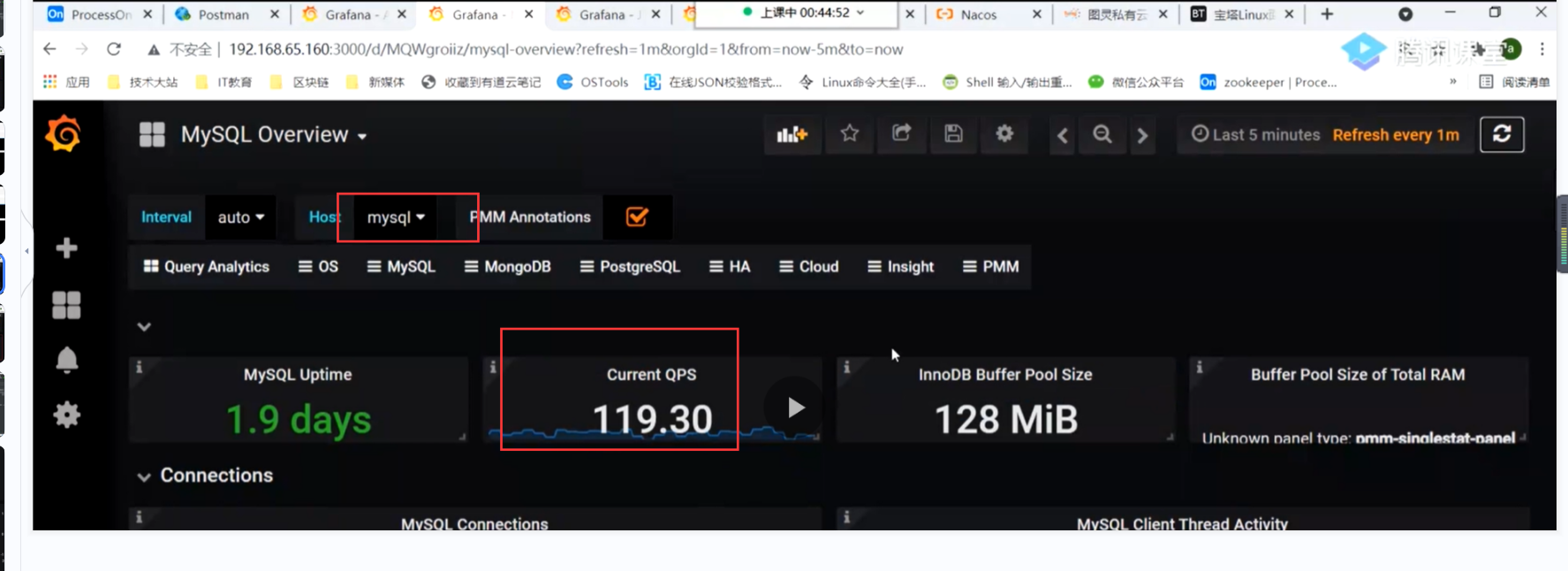
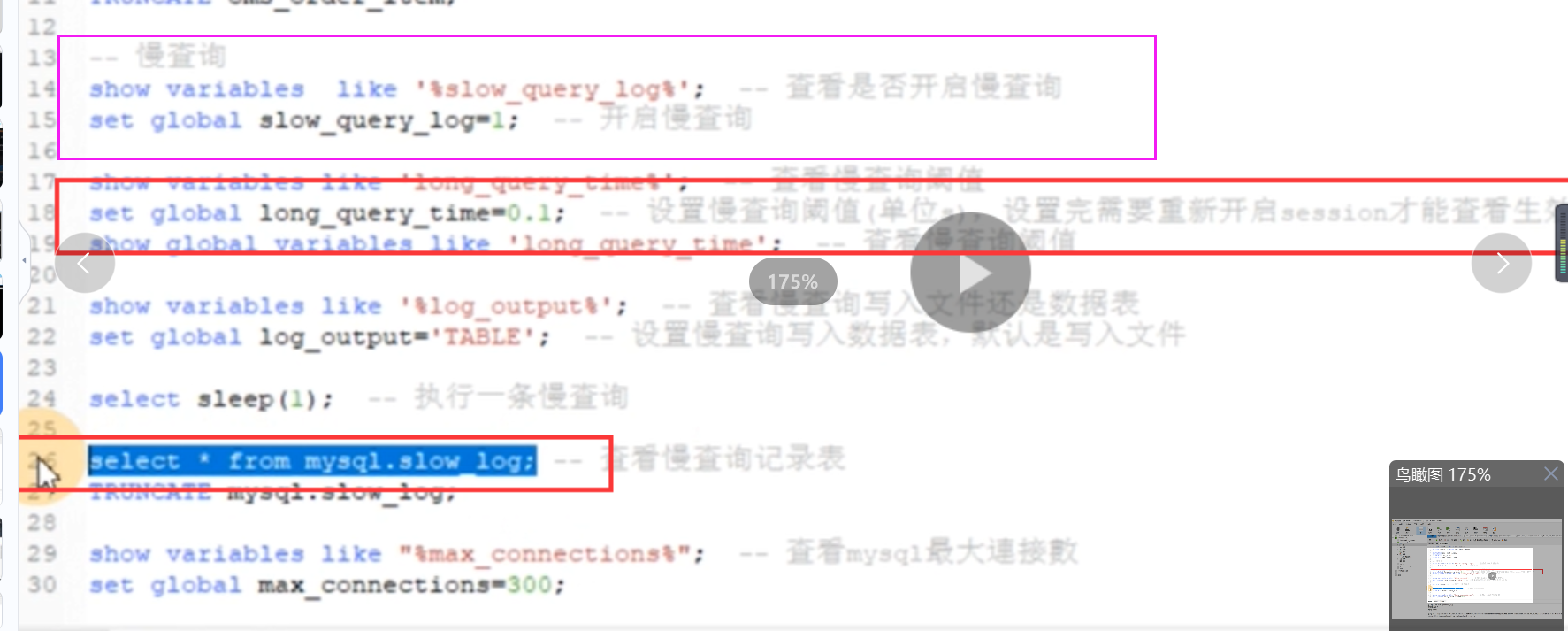
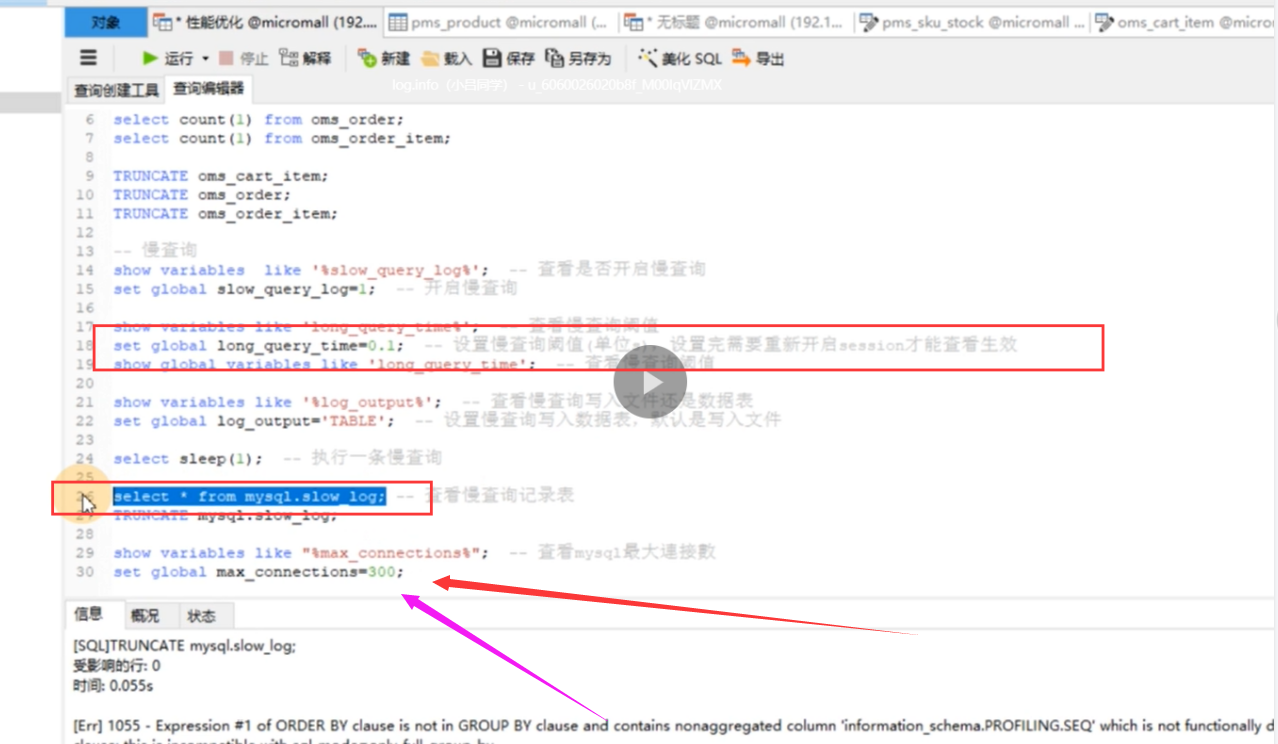
我们可以 通过下列命令查看并且设置mysql有关慢查询的脚本,这里设置100ms以上为慢sql
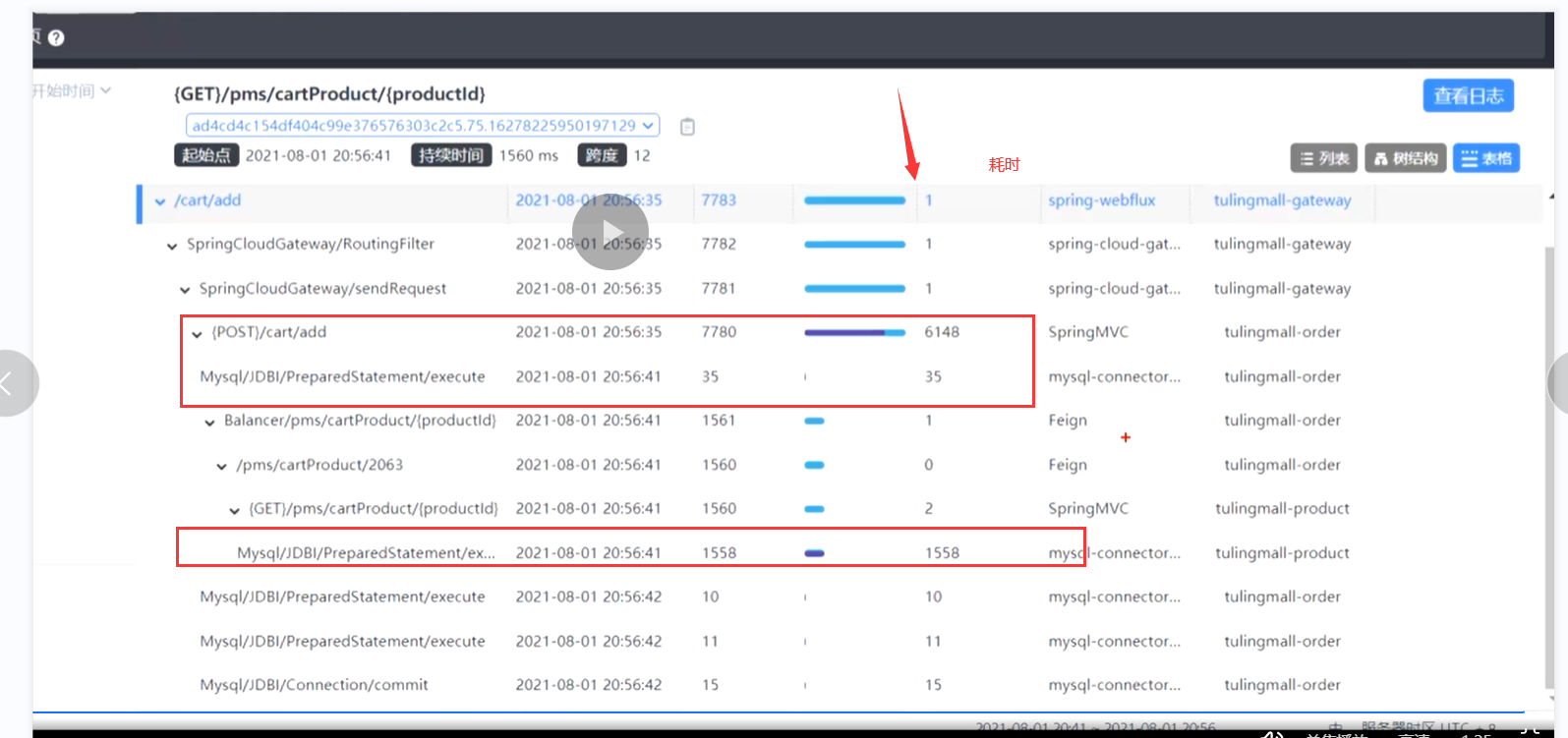
1.配合sky查询当前的链路追踪日志,我们
可以看到该交易的请求时长以及耗时操作
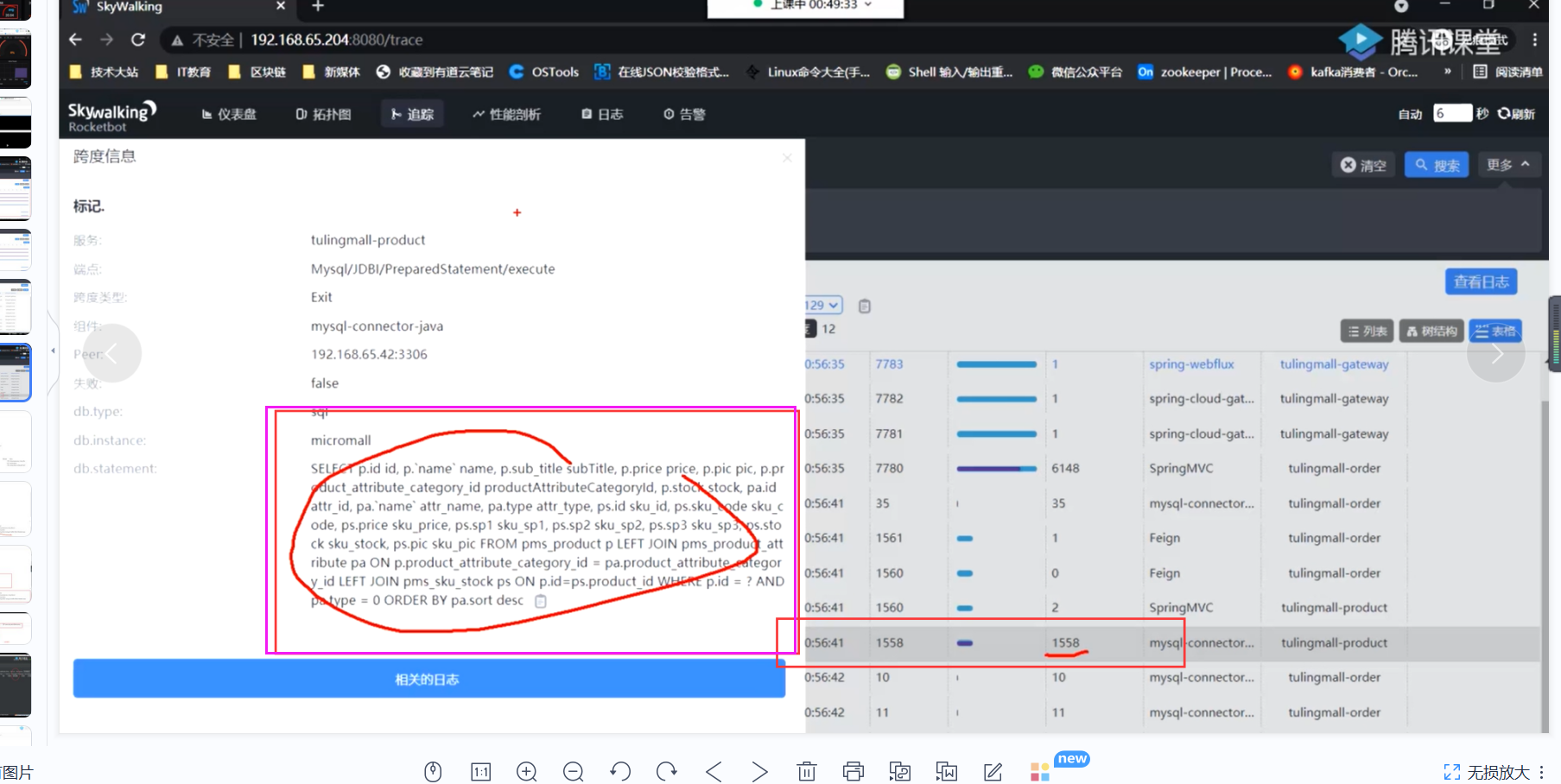
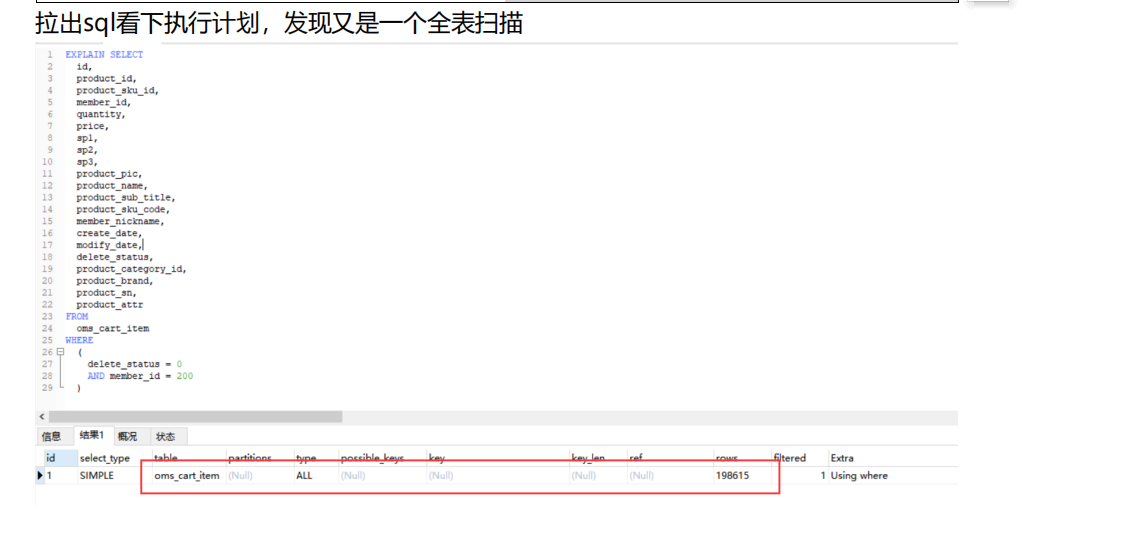
多看几笔交易得出结论 该sql为慢sql,我们需要吧对应的sql 放在
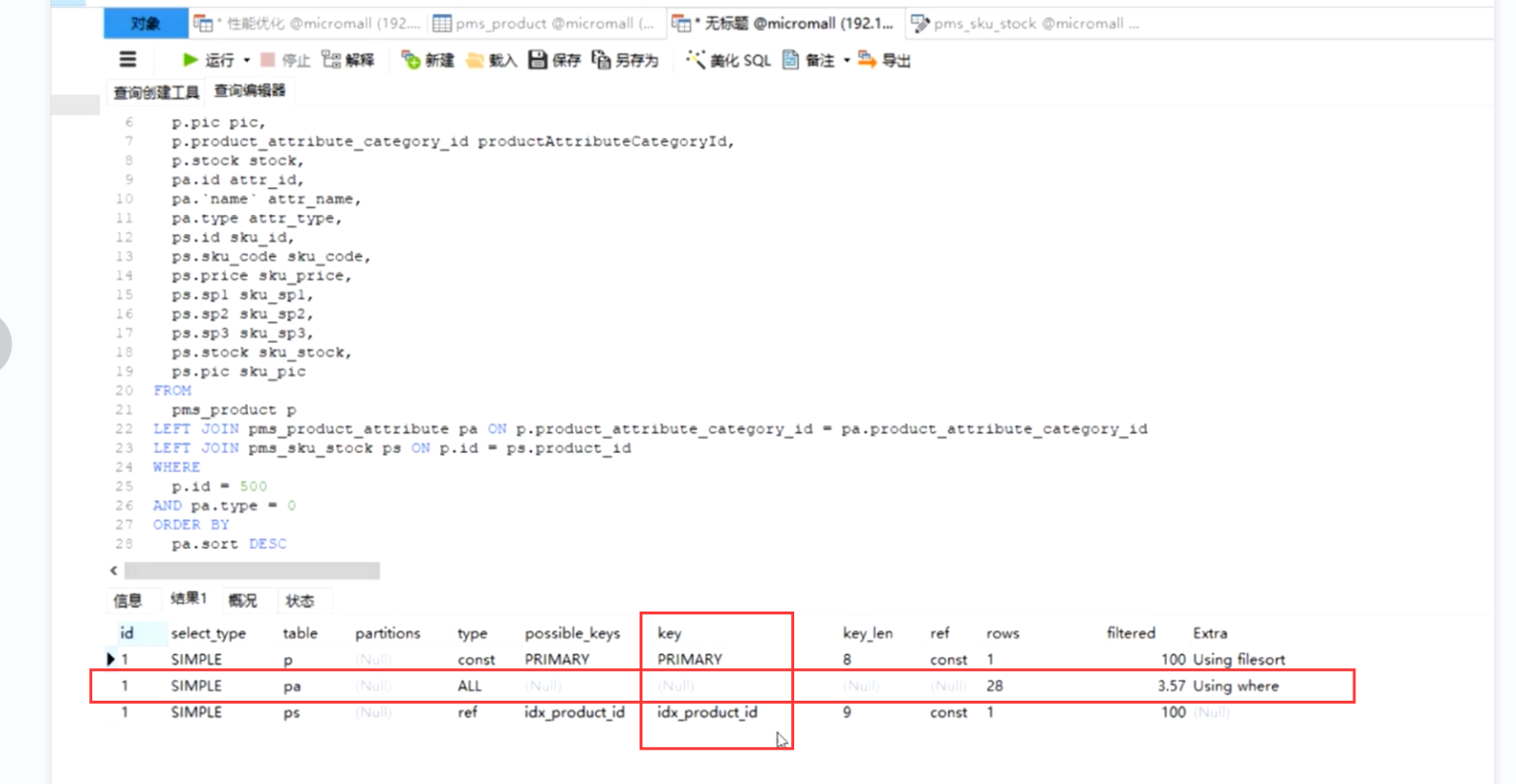
mysql中执行,用explain 查询其执行计划并且分析问题以及改进措施
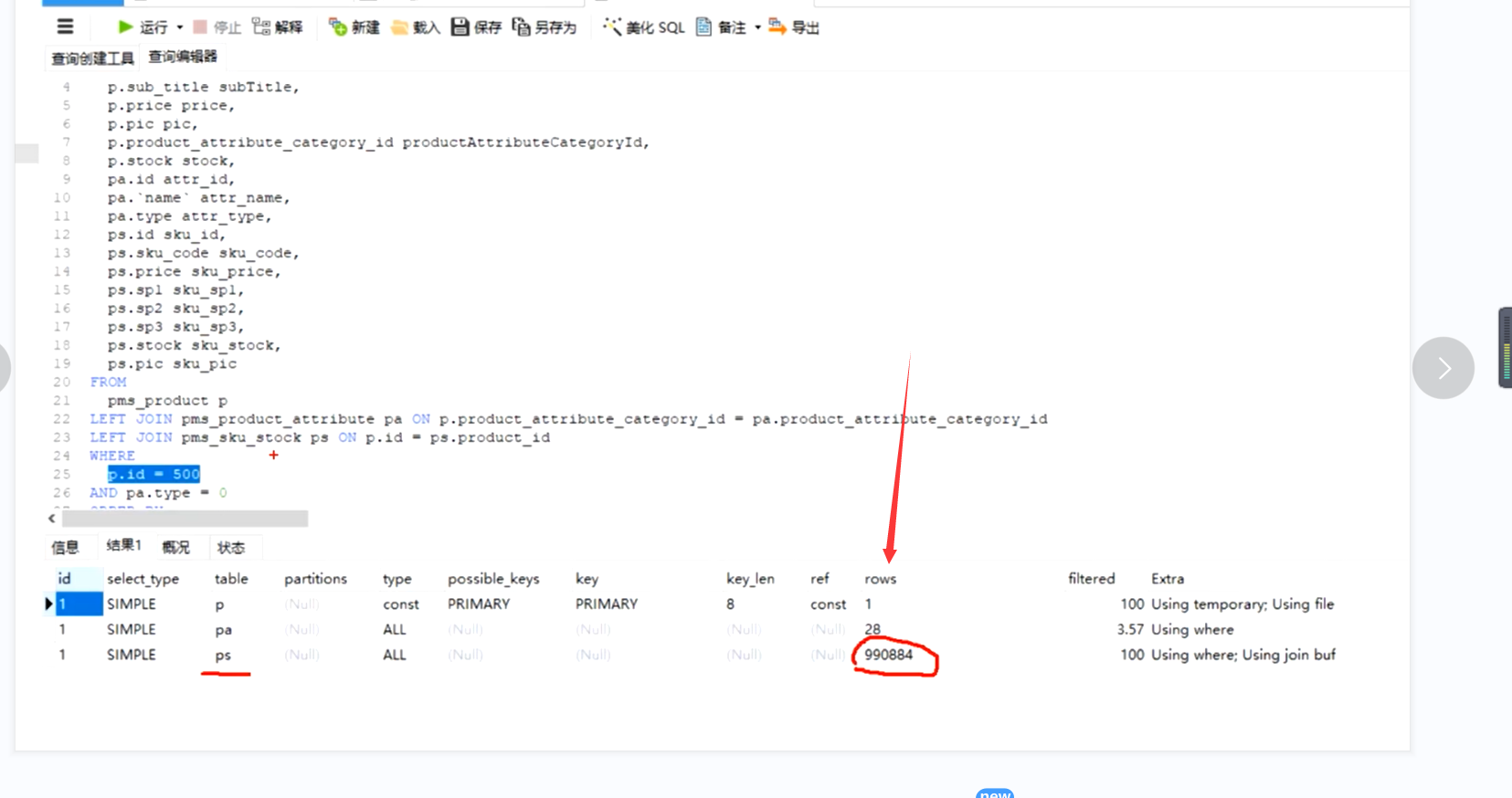
这里查了3个表,此时表中数据量大,并且没有走索引,type为all
我们需要为查询条件添加索引,然后再压测看看我们的执行计划以及压测情况
优先修改扫描行数多的看关联条件尽量不要超过3张表关联
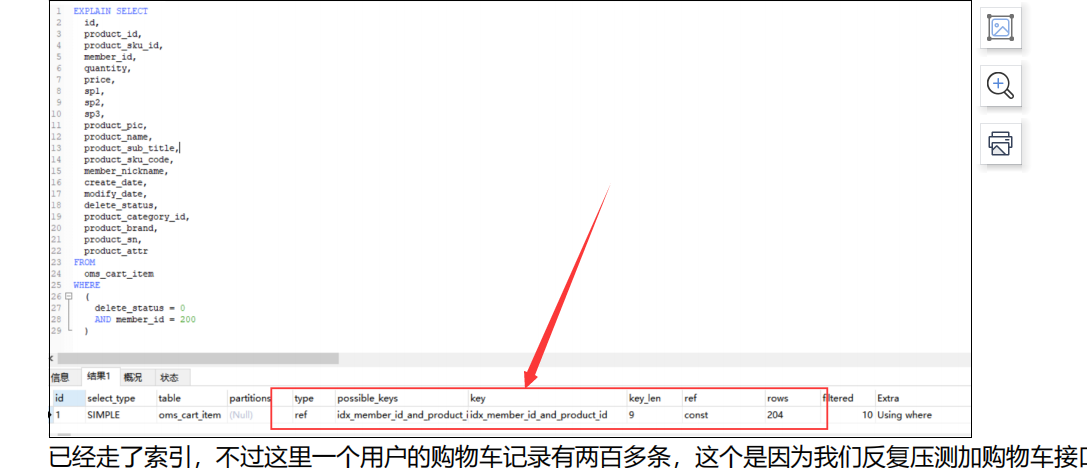
我们添加了索引,此时再用explain查询 可以看到rows明显减少,
然后我们再用jmeter进行压测,看看具体的执行情况
我们压测发现这个表明显需要加索引,我们加了索引 再来压测 看下效果
,我们优化完毕之后 先要看看explain 看看有没有效果
数据量少的表 我们一般不会去做优化 加不加索引无所谓
qps 从10到300. 我们的压测一段时间 至少压测个5分钟 需要平稳.看看他的qps 是否平稳
如果平稳了 基本上问题不大
qps超过了两百多,最高的时候有四五百多,好像优化有效果,继续一直压测下去,会发现qps一直在慢慢往下掉, 这是为什么了?
我们要看他的qps 平均值 还在降低什么原因?? 已经压了快5分钟,这2个java的cpu 起来了,但是Mysql的cpu依然很高, 肯定还有问题 [cpu高为什么高 比如说有慢查询 有比较耗时的sql语句拖慢了查询 或者其他的慢查询sql]
我们看了下mysql机器的cpu,发现已经严重超载了,肯定是有sql执行比较慢了
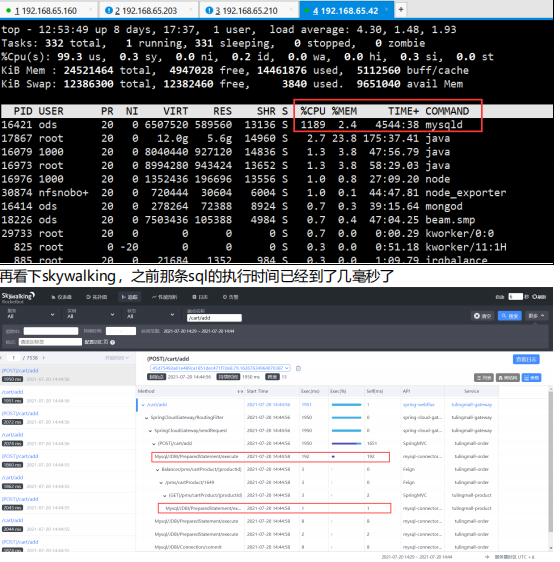
我们继续用sky来定位问题,
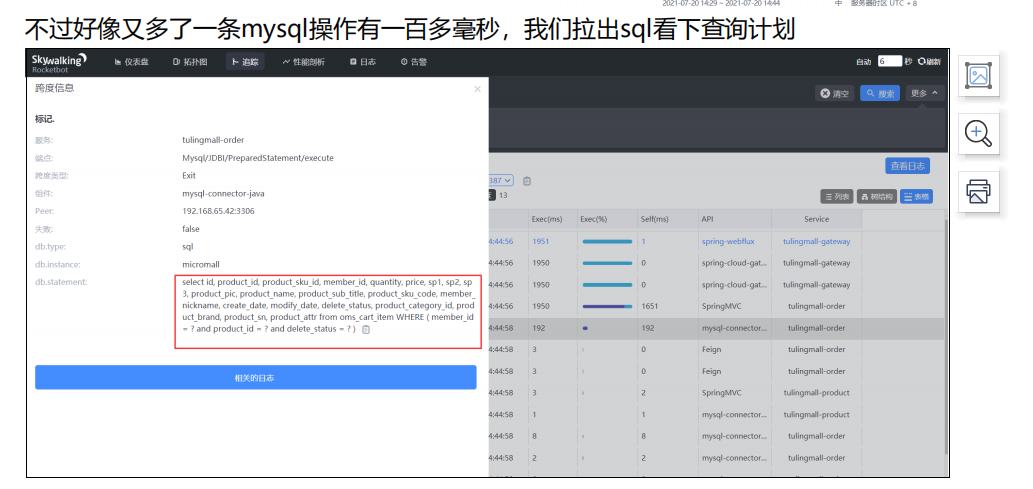
为什么之前这个sql 不慢,现在慢了, 因为随着我们的压测 该表中的数据
会越来越大,我们继续加索引 用explain来查 ,他这个表中有个delete_status只有2个值
0和1 区分度不大 我们就不给他加索引了
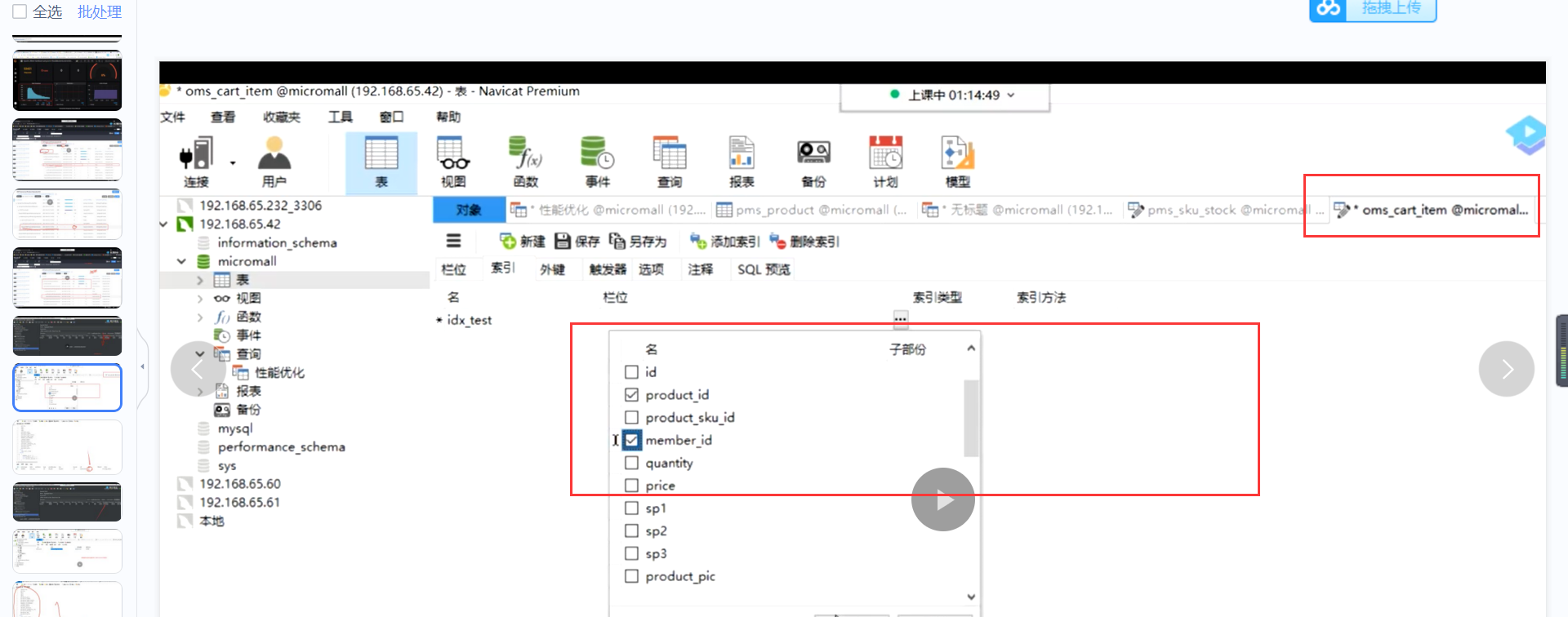
qps平稳时候的平均值, 在我们压测的时候 数据量对我们的影响非常大的,我们说一台机器的qps是多少 一定要讲业务复杂度场景, 数据量
比方说业务简单的和业务复杂的 qps相差几个数量级
包括表中数据 也是
先讲清楚我们的业务复杂度 高频交易 场景 数据量多少 再讲qps
因为 场景 数据量 交易量 的qps 不一样
我们加了索引继续用jmeter进行压测,java,cpu慢慢上来了(扩容解决) 我们就希望这种效果
mysql cpu下来了 之前是1000%多现在降低到了300%
我们看下mysql 的qps 已经到了14K ,mysql的cpu高,是因为他的qps高 此时已经到了1w多
我们要的就是java的cpu上来,mysql cpu下来 因为只有这样我们将来扩容 加机器才能加的起来
数据库是瓶颈 当然我们数据库可以做读写分离 做1主多从
继续压测 看看这个qps 是不是稳定这个值
要学会分析线上问题分析 我们在说慢查询 的问题
怎么去查询 怎么通过sky来定位问题 这种方法都一样
添加购物车------->压测查询购物车接口,我们继续用
jmeter来压测这个接口之后我们用grafana来观察平均qps以及查看top的命令看各个服务器的cpu情况
观察各个cpu情况.数据库的cpu又高起来了java不是很高
我们看skywalking 是不是又有慢查询

我们可以继续用explain查看发现此时是查找全表的
此时我们要注意索引的顺序,因为我们给表中添加联合索引的时候
要符合最左前缀原则,然后我们加了索引之后继续压测
观察top命令以及qps的变化还有sky的执行情况
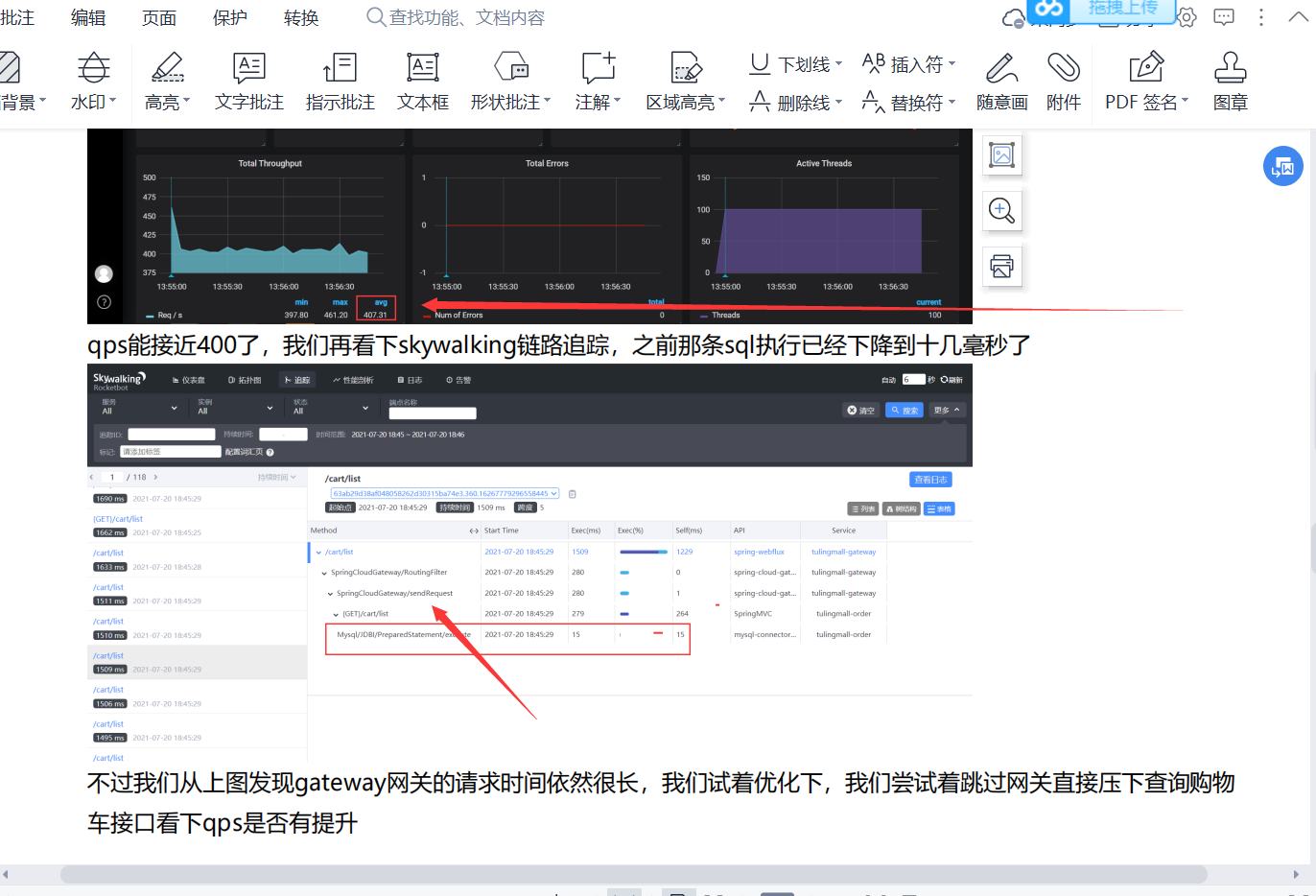
现在qps应该到700算是稳定了继续在skywalking 看交易链路 然后看数据库的cpu我们数据库的cpu 降到100%了,我们java 应用cpu 到400%了 上去了 这不就是我们要的效果么
查询购物车接口还有个问题
我们所有的微服务请求都是通过
gateway-------->order--------->db
也就是说所有微服务请求都会经过网关
现在的问题是
jmeter 直接压测 order--------->db qps 800
jmeter 直接压测 gateway-------->order--------->db qps 400
加了网关之后qps掉了一半,我们此时要分析这个原因
一般来说加了网关之后qps会掉5%-20% 但是现在已经降低了一半了
【网关掉了很多资源】怎么排查问题
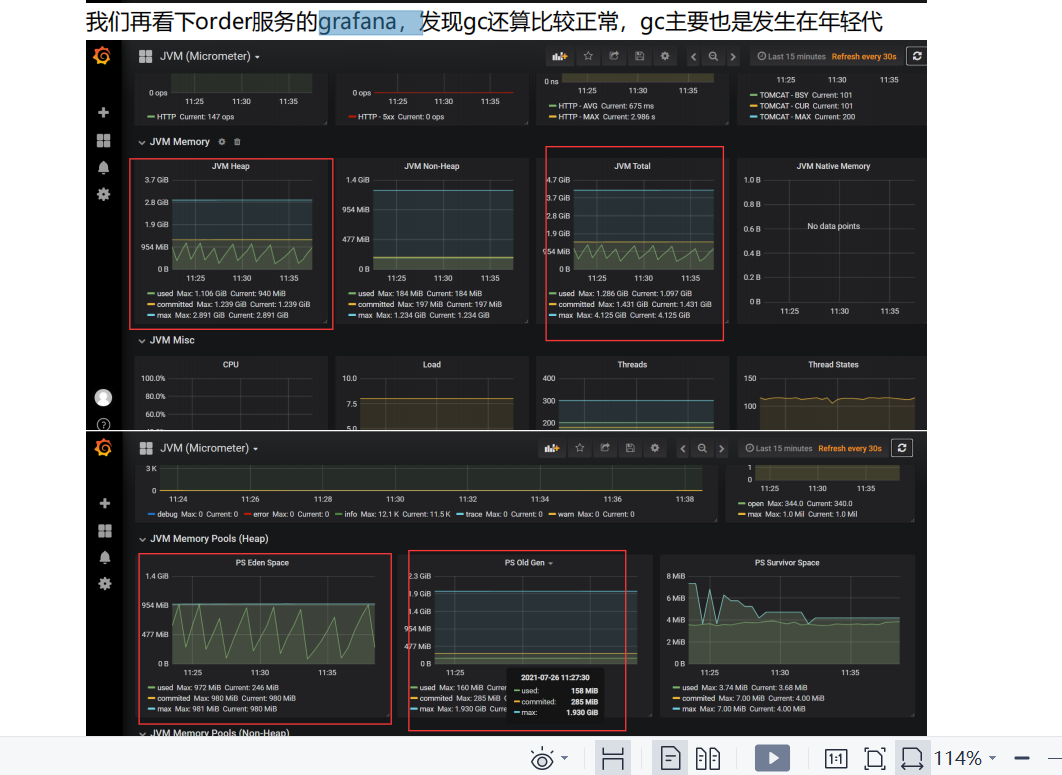
之前一直在分析mysql,我们现在分析是不是jvm的情况 我们要看jvm的监控图 我们要看我们订单服务的jvm 正常不正常
分析order服务的GC情况 以及堆的使用情况
分析gateway服务的GC情况 以及堆的使用情况 {}
用arthas分析jvm的情况,线程 以及Gc的情况
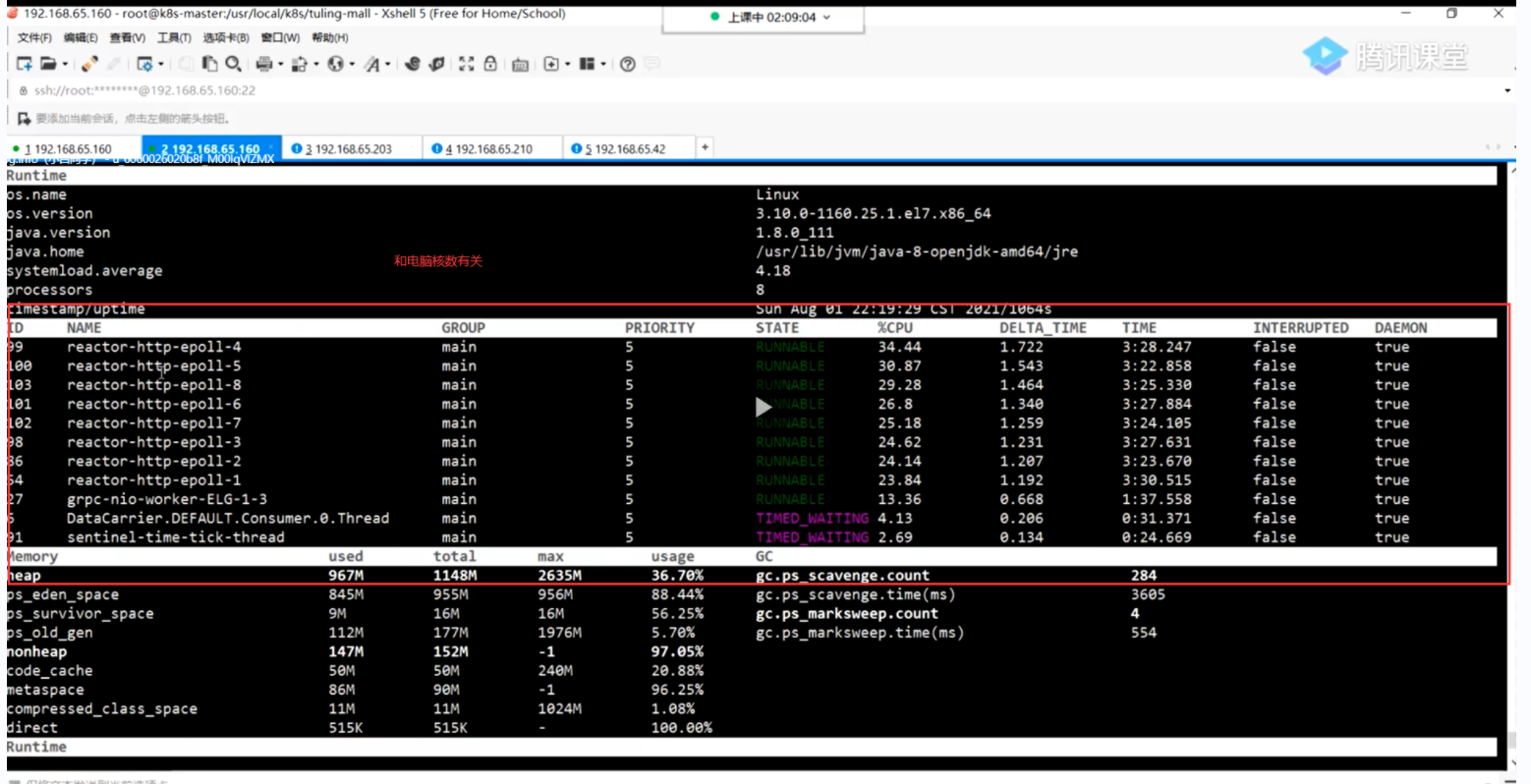
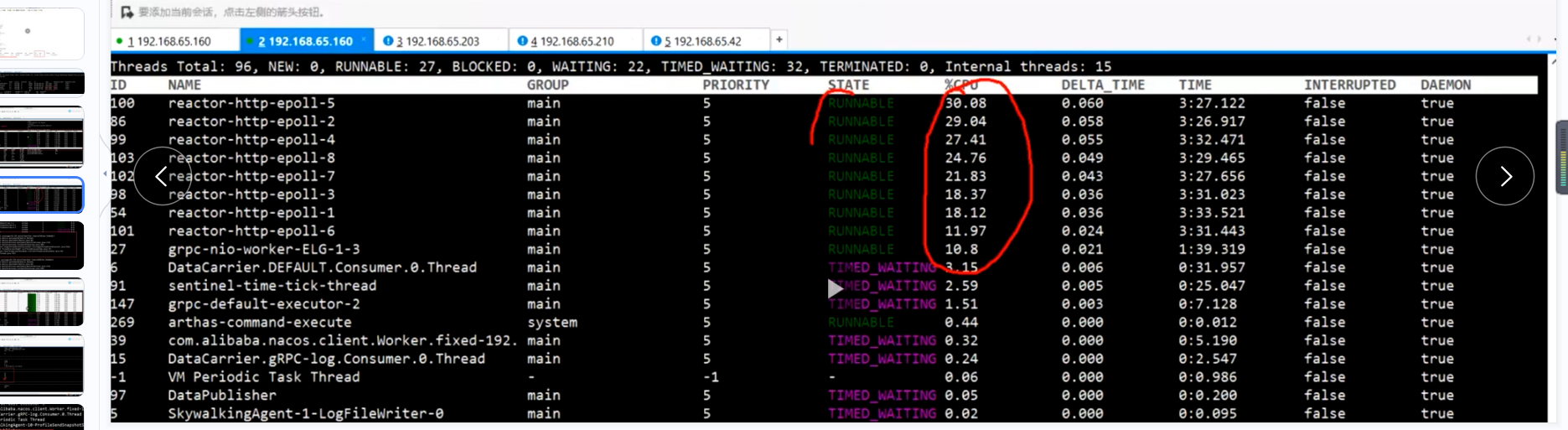
我们首先要分析这些cpu比较高的线程干了什么事情,查看线程的执行情况,gateway底层用的netty,netty默认是开了8个线程
因为和当前系统的核数有关
在网关中如果是netty 的线程 占用cpu比较高 算是正常因为netty负责干活的
如果不是netty 我们就得分析问题
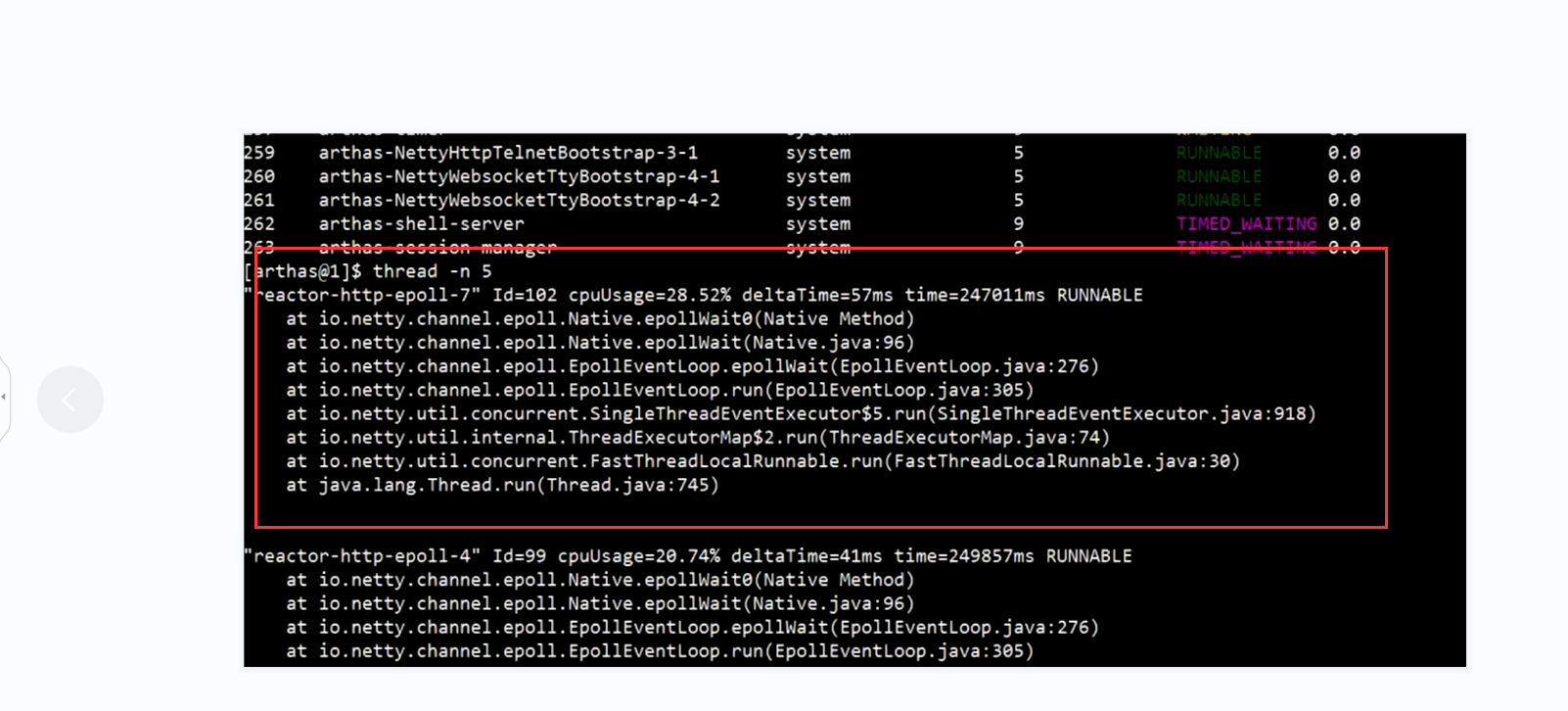
问题1
我们需要手动吧8个线程改成16个线程,改完之后再进行压测 看看线程数从8---》16 看看有没有提高 qps 以及 arthas的情况
分析问题
网关 qps降低一半 可能是netty 的线程数少了
看runable的线程以及waiting的线程数
waiting线程数代表正在等待的线程 这些线程当然越少越好

我们继续进行重新部署进行压测,因为我们改变了线程数
发现似乎qps效果不明显
虽然线程数增加了,但是压测结果并没有显著增加,因为cpu核数只有8个,所以对于gateway这种应用我们机器要 尽量把cpu的配置加大一点,它对cpu的消耗很大,继续查下其它原因
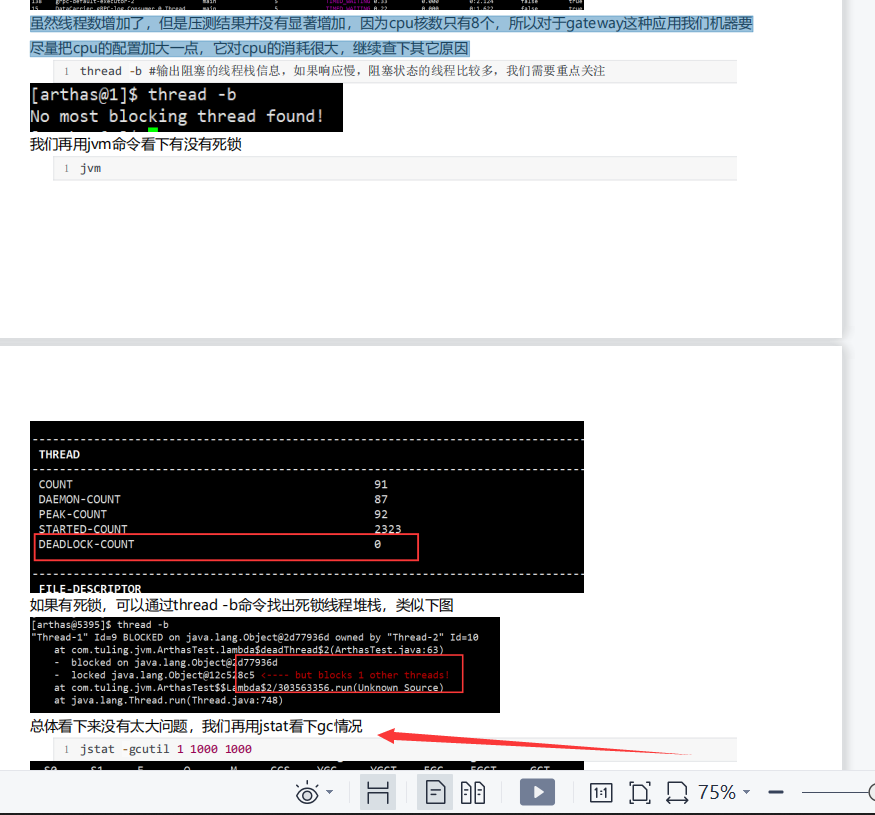
接下来我们看下网关的gc情况
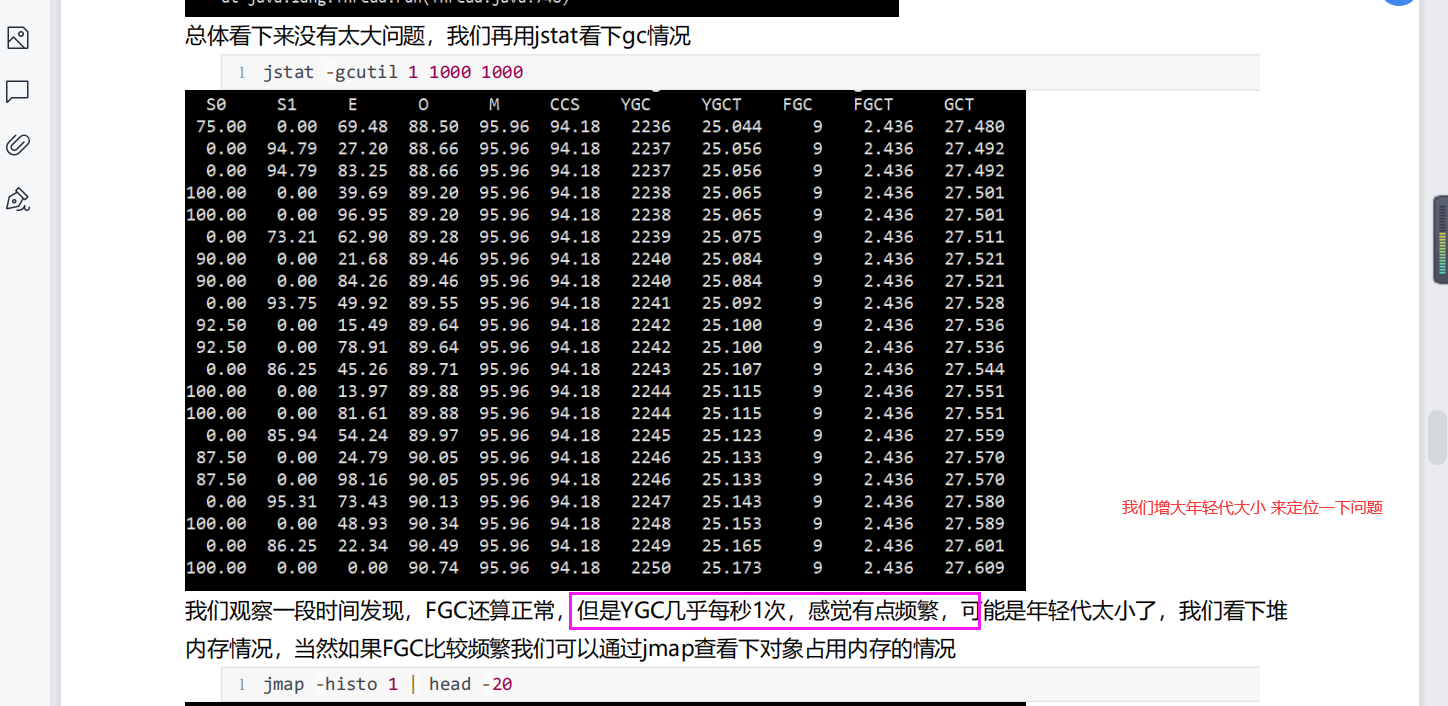
我们可以增加jvm的堆内存以及加大年轻代占比
重新部署我们的服务
继续进行压测 并且观察我们的gc发生的情况以及top各个服务器的情况
发现还是效果不明显 因为网关gateway对cpu性能要求较高,我们此时换一个更高的cpu试试
进入容器中看GC,看Gc的触发情况.我们现在已经调大了年轻代大小.younggc 没有呢么频繁了.但是qps 还是这么低
走了网关 和 不走网关 你的qps掉了一半 为什么
但是我们 {加线程 调jvm参数 似乎影响都不大}什么问题可能硬件的cpu 问题.网关掉的比较多的话 搞的好点的cpu 可能是机器硬件问题 网关对cpu要求高
我们换一个好的服务器再试试
我们的服务器的qps 和一下有关系
不同的应用 有的对cpu高 有的对内存要求高
结合你的业务系统 以及对硬件的要求
压测创建订单的接口 我们来压一下创建订单的接口
1. 加购物车 2. 查购物车 3.创建订单
我们继续压测第三个接口,我们整体压测的时候
发现创建订单的qps在150,添加购物车2000 查询购物车800 为什么创建订单只能到100多
我们可以继续用skywalking看看那个环节有什么问题 ,以及用cpu看看情况
我们继续用grafana查看order服务的信息
接着我们可用artha1s观察下order服务中是否有锁等待的情况
以及线程的执行情况 还有gc的情况
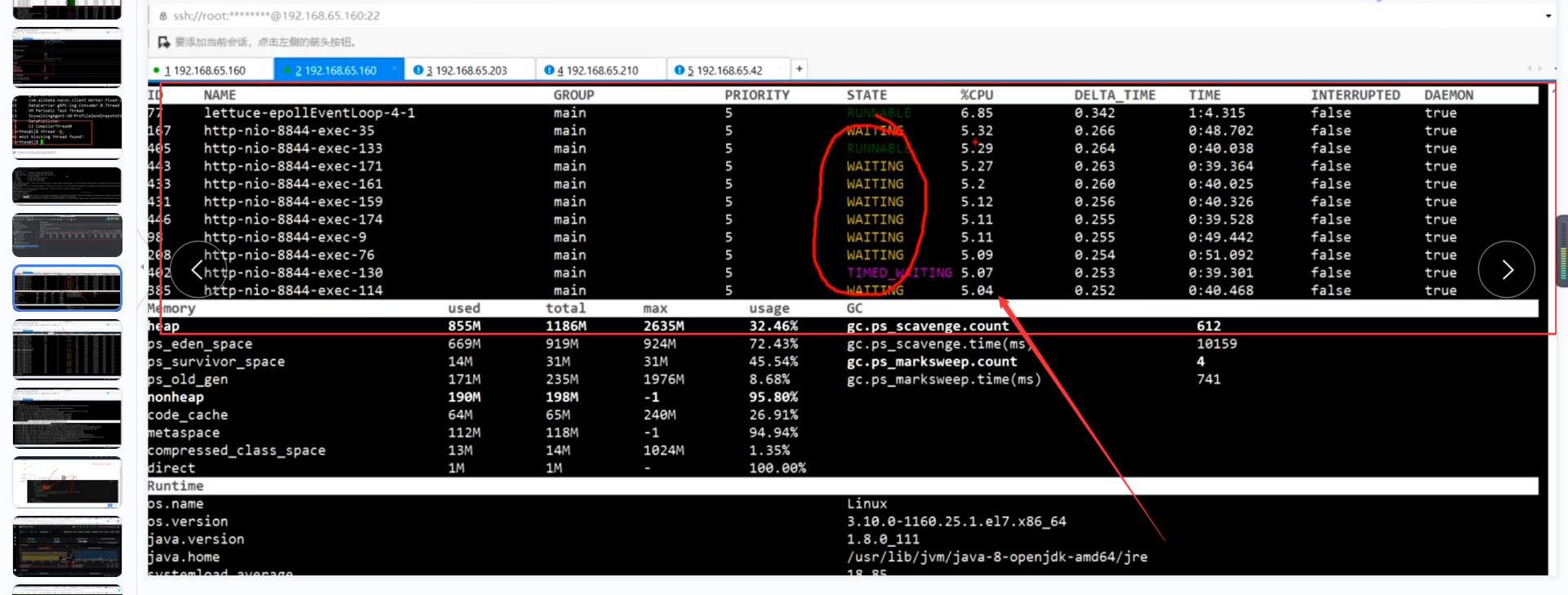
我们发现这些占有cpu的线程有一部分是waiting的
也就是说不干活的状态 我们可以查看他的具体信息
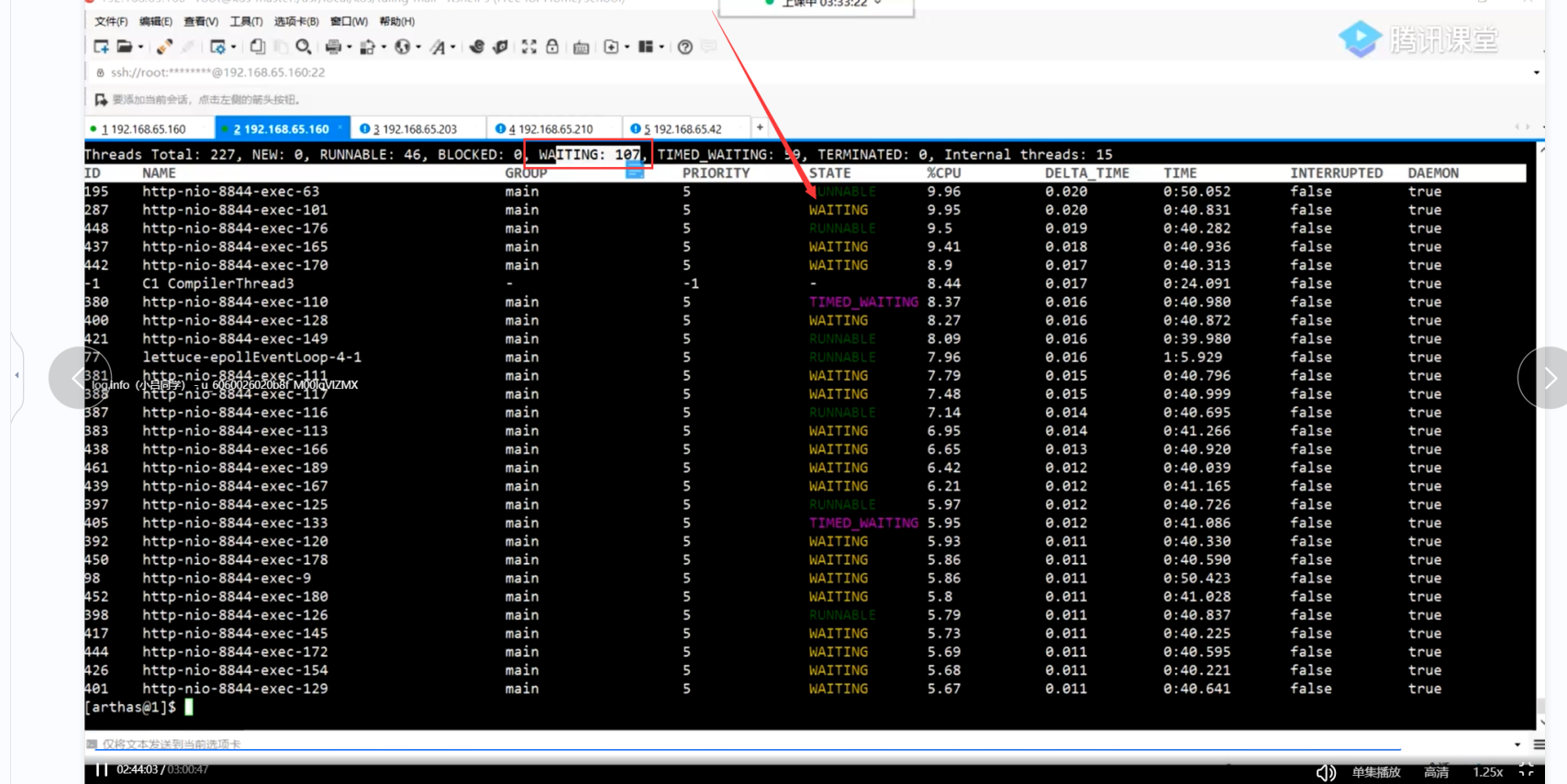
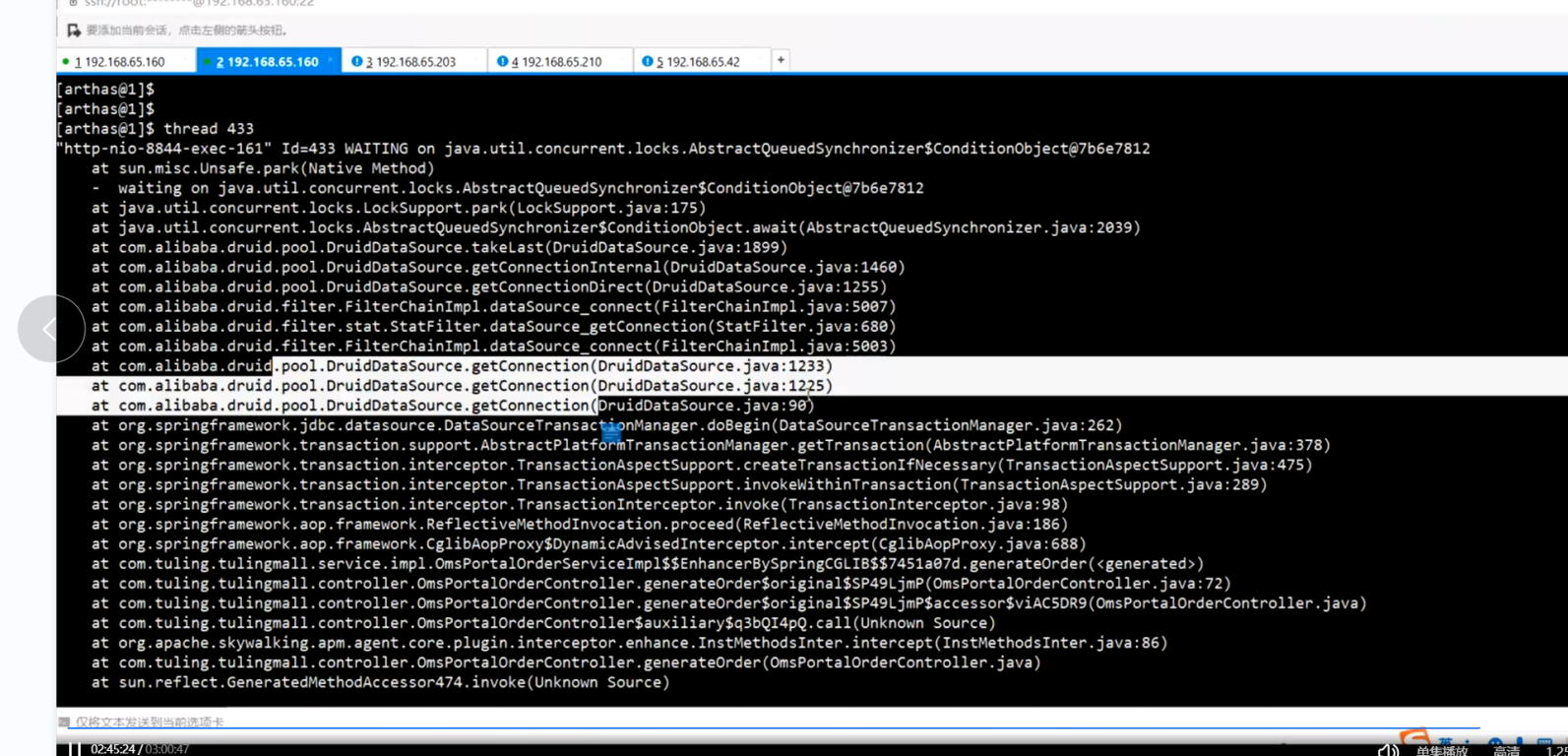
发现获取不到数据库连接了
大量占用cpu的线程在waiting ----------->为什么waiting
找线程id 查看为什么 占用cpu比较高的线程在waiting
waiting 的线程 都在等待
但是大量的tomcat线程在等待
我们需要调整db线程池的大小将 db连接池中连接调大一些
我们可以做优化
我们的微服务cpu,400-500 因为 大量的waitilgn线程他吧cpu 占用了. 他没有干活 他没有干活 他吧cpu占用了
导致我们cpu 现在很高但是没有干活
这里第一点是要提高mysql的数据库可以设置最大连接数量
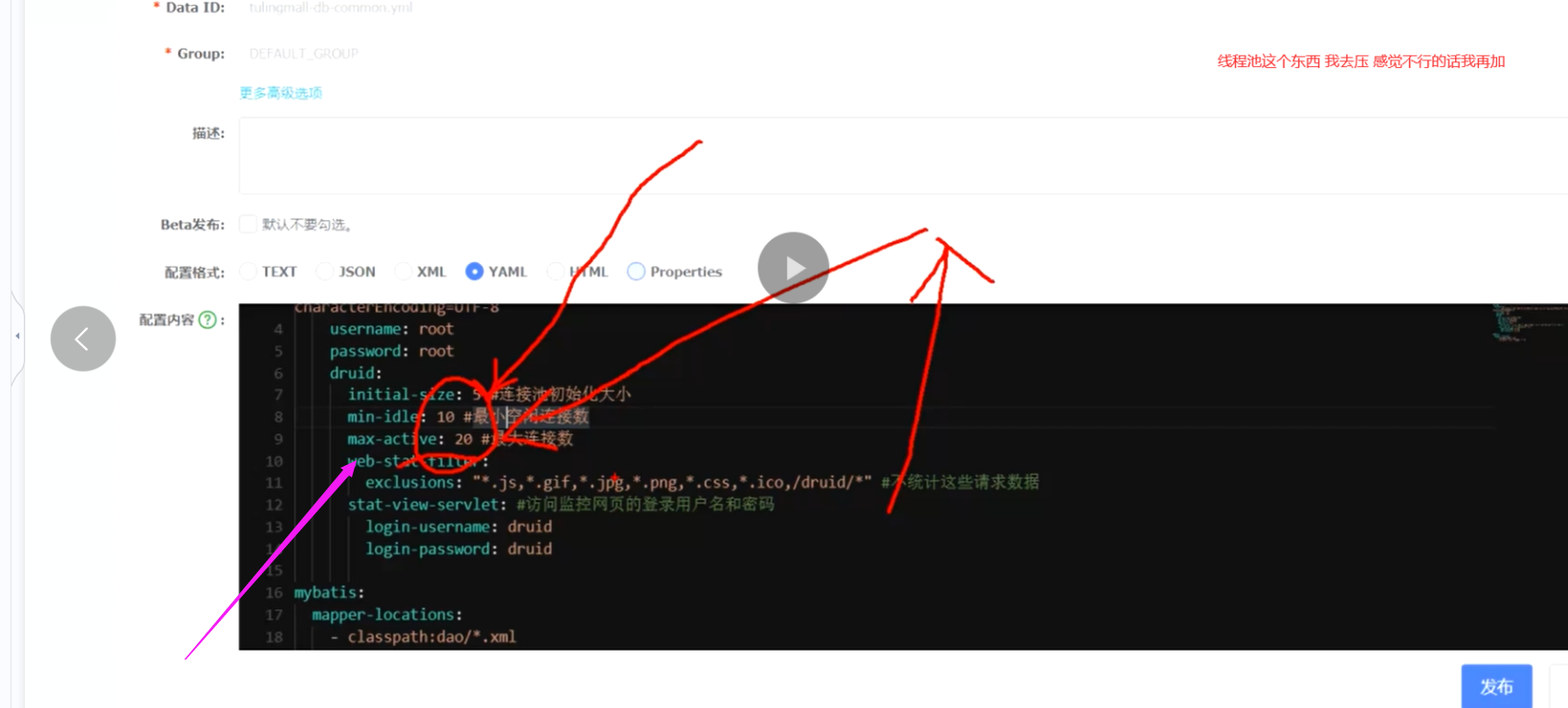
db连接调大了,我们继续压测同时,我们看看arthas 的 [1.cpu 是不是高 2. waiting的线程是不是多]
dashboard
我们可以继续用arthas 查看order服务中详细信息
top 查看cpu 【我们调的连接数 数据库的cpu上来了】 对数据库的压力变大了
web应用cpu没有变化
我们继续用waiting的变少了 runable了变多了
还有大量waiting 的话 就得调大db连接池 再调大没有意义 因为现在Mysql的cpu 600% 已经很高了
thread -b 我们调大了数据库连接池tomcat连接池之后
整体来说waiting和time_waiting 的线程越来越少了
其实这样就可以了 我们所有的应用都是在忙了 在占用cpu了
接下来我们看看qps的问题 甚至还有点降低了
连接池 线程池,不是越大越好,我们要根据实际情况具体分析
我们就应该换换其他思路 比如说sky 数据库的慢查询
我们说白了 有可能会有慢查询,慢查询我们也可以查
慢查询日志表进行分析定位
慢查询的所有日志可以记录在表中
我们可以看看时间比较长的慢查询,看看他的sql 已经加了索引,并且已经走了索引为什么还慢
因为数据在增长扫描行数会变大,
我们之前说delete_status 不好加索引 因为他区分度不高 要么是0 要么是1
但是我这个场景 我要不要加 此时1 是很多,0 很少
是否要加索引 取决于数据量的分布,比如说 其中一种90% 其中一种是10% 他区分度很明显 呢么就应该加了索引
加了索引之后我们可以继续压测
所以0和1 要不要加索引要看数据量的区分度 如果区分度比较大 可以加索引
如果各自都是50% 加不加索引 意义不大
建索引的时候 考虑联合索引. 但是我们要注意联合索引的顺序 最终将全链路系统中 并发到1s的qps300
就够用了.网关对内存要求不高 对cpu 要求高 我们需要长时间去压测看看有没有内存泄露 之类的问题
吧每一个环节的分析 做到位
版权声明:本文为weixin_43689953原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。