一,procise步骤
二,IAR步骤:四个ARM CONTEX A7
1,新建hello word工程,并将代码,并将iar工程复制四份,修改四个工程的 cstartup.s 文件
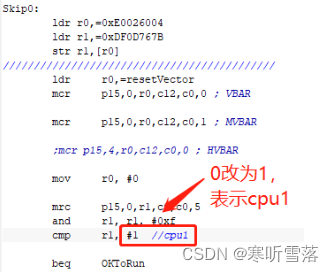
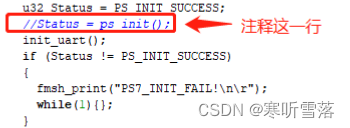
2,修改初始化代码,fsbl 里边已经将 DDR 等硬件初始化好了,注释掉app 中的初始化
代码,避免重复是初始化。
3,修改 icf 文件,四个 app 程序的运行空间不能冲突,分别为如下:
SDK0:
/*-Memory Regions-*/
define symbol __ICFEDIT_region_RAM_start__ = 0x00100000;
define symbol __ICFEDIT_region_RAM_end__ = 0x1FFFFFF;
define symbol __AXI_DDR_START = 0x00100000;
define symbol __AXI_DDR_END = 0x3FFFFFFF;
SDK1:
define symbol __ICFEDIT_region_RAM_start__ = 0x2000000;
define symbol __ICFEDIT_region_RAM_end__ = 0x2FFFFFF;
SDK2:
/*-Memory Regions-*/
define symbol __ICFEDIT_region_RAM_start__ = 0x3000000;
define symbol __ICFEDIT_region_RAM_end__ = 0x3FFFFFF;
SDK3:
define symbol __ICFEDIT_region_RAM_start__ = 0x4000000;
define symbol __ICFEDIT_region_RAM_end__ = 0x4FFFFFF;
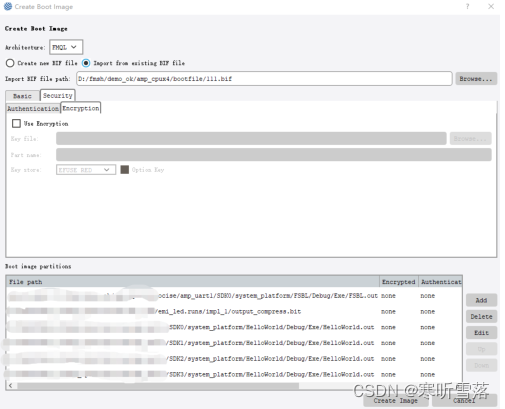
4,打包boot.bin文件,boot.bin 文件由fsbl+bit+app0+app1+app2+app3组成,注意修改destination CPU和cstartup.s文件一致。
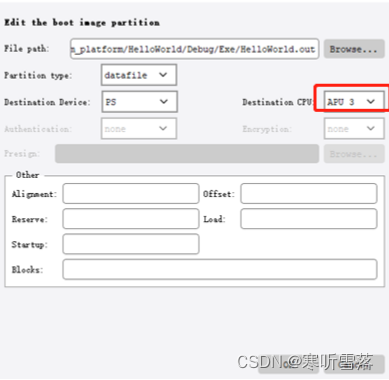
5,测试时需要接上开发板的两个串口,由于测试时两个 cpu 共用一个uart,因此 helloworld
程序中将打印时间设置的不一样以区分确认不同核的代码确实跑起来了。
6,CPU0-CPU1都运行的串口代码
#include <stdio.h>
#include "platform.h"
#include "fmsh_common.h"
#include "ps_init.h"
#include "fmsh_print.h"
#include "fmsh_ps_parameters.h"
int main()
{
init_platform();
/* FMSH_WriteReg(FPS_SLCR_BASEADDR, 0x008, 0xDF0D767BU); //unlock
FMSH_WriteReg(FPS_SLCR_BASEADDR, 0x838, 0xf);
//Open USER_LVL_SHFTR_EN_A and USER_LVL_SHFTR_EN_5
FMSH_WriteReg(FPS_SLCR_BASEADDR, 0x004, 0xDF0D767BU); //lock*/
while(1)
{
fmsh_print("Hello World! cpux\n\r");
delay_ms(100);
}
}三,多核间数据共享IAR代码解析
filetomem:用于将文件拷贝到指定的内存地址处。
amp:将裸机程序所在的内存地址写入指定 CPU 核的程序入口地址寄存器。
app_cpu2.bin:每隔 1 秒产生一次心跳,用于 softuart 监测;接收led 程序发来的信息,实现指定 led 灯的开关;实现串口中断,接收输入串口的信息。
#include <stdio.h>
#include "platform.h"
#include "fmsh_common.h"
#include "ps_init.h"
#include "fmsh_print.h"
#include "intrinsics.h"
#include "cache.h"
//#include "fmsh_ttc_public.h"
#include "fmsh_gic.h"
#include "fmsh_gic_hw.h"
#include "spin_lock.h"
#include "ttc.h"
/* 测试一小部分数据,主要是针对一些共享flag变量的场景,测试时,需要CPU0和CPU1的宏定义同时改为1*/
#define TEST_SEVERAL_VIRIABLES 0
/* 1表示开启更多的调试信息;0表示关闭调试信息 */
#define DEBUG_AMP_INFO 0
#define DEBUG_AMP(flag,...) \
do { \
if(flag) \
fmsh_print(__VA_ARGS__); \
}while(0)
/* share ddr is at the high ddr address 768MB for some variable usage
*/
#define SHARED_DDR_ADDRESS (0x30000000)
/* ahb sarm(128KB) used for shared flag with device memory*/
#define SHARED_OCM_MEMORY_BASE (0xe1fe0000)
#define SHARED_GIC_SPIN_LOCK (0xe1fe0040)
#define SHARED_TEST_SEMAPHORE (0xe1fe0080)
/* Define a data memory space which is visible to both CPUs, the DDR is okay since a large amount of data could be written. */
#define SHARED_DDR_MEMORY_BASE (0x04000000)
#define SHARED_DDR_MEMORY_SIZE_128KB (0x20000)
#define SHARED_DDR_MEMORY_SIZE_1MB (0x100000)
/* Declare a value stored in OCM space which is visible to both CPUs. */
#define SEMAPHORE_VALUE (*(volatile unsigned long *)(SHARED_OCM_MEMORY_BASE))
#define GIC_SPIN_LOCK ((arch_spinlock_t *)(SHARED_GIC_SPIN_LOCK))
#define TEST_SEMAPHORE_VALUE (*(volatile unsigned long *)(SHARED_TEST_SEMAPHORE))
/* Declare a memory space where both CPUs can store their data sets. */
#define DESTINATION_ARRAY (SHARED_DDR_MEMORY_BASE)
/* Define a data set for CPU0 to operate on. */
static char cpu0_data_128KB[SHARED_DDR_MEMORY_SIZE_128KB];
ttc_user_dev_t ttc0_timer1=
{
.device_id = FPAR_TTCPS_0_DEVICE_ID,
.irq_no = TIMER0_1_INT_ID,
.irq_priority = 0xa8,
.timer_no = timer1,
.ttc_cnt = 0,
.delay_cnt = TTC0_0_FREQ*10, /* 10 Seconds */
.IntcPtr = &IntcInstance,
/* shared spin lock */
.gic_spin_lock = GIC_SPIN_LOCK,
/* cpu0 */
.map_cpu_no = 0x1 << 0
};
/* ttc0的timer1初始化 */
int ttc0_timer1_use_interrupt(void)
{
ttc_user_dev_t *ttc_dev_ptr = &ttc0_timer1;
gic_common_init(ttc_dev_ptr);
FTtcPs_ttc_timer_init(ttc_dev_ptr);
/* 即使某个cpu提前退出锁,产生了中断,中断处理流程里比如读中断号寄存器,
* 写ack寄存器之类的操作和设置对应中断的触发模式寄存器,优先级寄存器并不冲突 ,
* 没有并发即可
*/
FTtcPs_ttc_timer_enable(ttc_dev_ptr, FMSH_set);
return 0;
}
/* large block data for share */
int data_copy_to_cpu1 (u8 *data, u32 size)
{
int index;
volatile char* data_destination = (volatile char *) DESTINATION_ARRAY;
/* Copy the data set to the shared memory destination. */
for (index = 0; index < size; index++)
{
data_destination[index] = data[index];
}
return index;
}
int semaphore_cpu0_init()
{
/* Only CPU0 should be responsible for initializing the semaphore. */
SEMAPHORE_VALUE = 0;
return 0;
}
int semaphore_cpu0_signal()
{
SEMAPHORE_VALUE = 1;
return 0;
}
int semaphore_cpu0_wait()
{
while (SEMAPHORE_VALUE == 1);
return 0;
}
// several memory location shared flag variable
void core0_test(volatile unsigned int *flag)
{
/* cortex-A7的scu会窥探store buffer
* armv7 TRM里说multi-core copy架构上not amtomic
* 实际CPU设计实现时muti-core copy是atomic的,armv8已经是
* 在架构上muti-core copy atomic的了,而read-modify-write不是原子的
* 这样同一地址MESI的话应该可以保证多核的一致性,仅考虑单个变量就不需要内存屏障了
* 这个测试例子比较特殊,反汇编看得话,写-读,以及读-写前后都有寄存器依赖,读到的值和要写的值都放到R1寄存器了,
* 所以执行odder应该也是program order
* 请参考配套的文档。
*/
*flag = 0x11111111;
//smp_rmb();
/* 共cpu0和cpu1共享flag变量
*/
while(*flag != 0x22222222);
/* 这里应该是控制依赖的 */
*flag = 0x33333333;
//smp_rmb();
while(*flag != 0x44444444);
/* 和后面的指令隔离 */
// smp_mb();
}
static void init_data_cpu0_pattern(u8 * data, u32 size)
{
u32 i;
if(!data || !size)
return;
/* 初始化数据偏移0x5 */
for(i = 0; i< size; i++)
data[i] = (u8)(i + 0x5);
}
static void dump_cpu0_data(u8 * data, u32 size)
{
u32 i;
for(i = 0; i< size; i++)
{
fmsh_print("%x ", data[i]);
if((i+1)%16 == 0)
fmsh_print("\n\r");
}
fmsh_print("\n\r");
}
static int check_data_cpu1_pattern(u8 * data, u32 size)
{
u32 i;
int failed = 0;
if(!data || !size)
return -1;
for(i = 0; i< size; i++)
if( data[i] != ( (u8)(i+0xa) ) )
{
failed++;
fmsh_print("%d: %x-%x\n\r",i, data[i], (u8)(i+0x5));
}
return failed;
}
/* cpu0和cpu1的这个同名函数是一对测试例程,同时改成main可以进行测试
*/
int global_variable_observation_main()
{
/* fsbl has called ps_init */
init_platform();
invalidate_icache_all();
icache_enable();
/* 使能d-cache时,会设置cpu core的smp bit,默认的DDR页表已经满足shareable,WBWA
* 使能过程中,会无效L1,L2 d-cache。
*/
dcache_enable();
fmsh_print("CPU 0 set the shared global variable...\n\r");
SEMAPHORE_VALUE = 0;
while(1)
{
while(FUartPs_isRxFifoEmpty(&g_UART));
/* 串口终端里按按键c执行全局变量修改,也可以自动发送c字符 */
if(FUartPs_read(&g_UART)=='c')
{
SEMAPHORE_VALUE += 1;
smp_mb();
TEST_SEMAPHORE_VALUE = 1;
}
}
}
/* 本demo是基于scu保证多个cpu core共享内存的一致性,即遵循MESI cache一致性原则
* 没有考虑dma的场景
*/
int main()
{
u32 round = 0;
/* fsbl has called ps_init */
init_platform();
invalidate_icache_all();
icache_enable();
/* 使能d-cache时,会设置cpu core的smp bit,默认的DDR页表已经满足shareable,WBWA
* 使能过程中,会无效L1,L2 d-cache。
*/
dcache_enable();
/* xapp1079的同步变量说明:
* 可以直接修改mmu_table.S对应ahb sram的属性,psoc没有提供API,可以移植过来
* Disable caching on shared OCM data by setting the appropriate TLB
* attributes for the shared data space in OCM.
* 可参考ARMV7 TRM文档,《汇总文档\裸跑相关补充文档\arm官方文档\arm_arm_ARMv7-A_ARMv7-R_DDI0406_2007.pdf》
* S=b1 共享
* TEX=b100
* AP=b11 manager不做权限检查
* Domain=b1111
* C=b0
* B=b0
* 页表属性:L1和L2 d-cache设定为non-cacheable,shareable,normal memory
*/
// Xil_SetTlbAttributes(0xE1Fe0000,0x14de2); // S=b1 TEX=b100 AP=b11, Domain=b1111, C=b0, B=b0
/* 保留的示例代码,本demo利用fsbl自动启动两个app,请参考
* 《汇总文档\裸跑相关补充文档\amp\amp_bare_metal_ddr-v1.0.pdf》
*/
#if 0
FMSH_WriteReg(0xE0026008, 0x0, 0xDF0D767B);//解锁 SLCR 寄存器
FMSH_WriteReg(0xE0026440, 0x0, 0x02004100);//写入 Helloword 运行的起始地址到该寄存器中。
FMSH_WriteReg(0xE0026004, 0x0, 0xDF0D767B);//解锁 SLCR 寄存器
asm("sev"); //通过指令唤醒 CPU1。
#endif
fmsh_print("CPU 0 will print after for a little long delay!waiting...\n\r");
init_data_cpu0_pattern((u8 *)cpu0_data_128KB, SHARED_DDR_MEMORY_SIZE_128KB);
/* 这里的同步变量已经改成normal cache-able的属性了
* non-cacheable的normal memory,甚至device memory和normal memory在一起,
* 内存序也不保证的。
*/
semaphore_cpu0_init();
/* 即使某个cpu提前退出锁,产生了中断,中断处理流程里比如读中断号寄存器,
写ack寄存器之类的操作和设置触发,优先级寄存器不冲突 ,没有并发
*/
ttc0_timer1_use_interrupt();
while(1)
{
/* 针对一些地址的单个共享flag变量的场景 */
#if TEST_SEVERAL_VIRIABLES
u32 i;
for(i = 0; i < 0x100000; i +=32)
core0_test((volatile unsigned int *)(SHARED_DDR_ADDRESS + i));
core0_test((volatile unsigned int *)SHARED_DDR_ADDRESS+0x10000);
core0_test((volatile unsigned int *)SHARED_DDR_ADDRESS+0x20000);
core0_test((volatile unsigned int *)SHARED_DDR_ADDRESS+0x30000);
if(round && ((round % 200) == 0) )
fmsh_print("CPU 0 finished %u round\n\r", round);
round++;
/* 连续通信数据区缓冲区测试 */
#else
int fail = 1;
/* 开始测试一段连续数据 */
if(round && ((round % 200) == 0) )
fmsh_print("CPU0: has run %u round start!\n\r", round);
/* cpu0写128KB cpu0 pattern数据到共享数据区 */
data_copy_to_cpu1((u8 *)cpu0_data_128KB, SHARED_DDR_MEMORY_SIZE_128KB);
DEBUG_AMP(DEBUG_AMP_INFO, "CPU0 write 128KB data!\n\r");
//dump_cpu0_data((u8 *)DESTINATION_ARRAY, SHARED_DDR_MEMORY_SIZE_128KB);
/* 在ahb sram里的信号量改成cache-able时,可能normal memory时cpu乱序执行的问题,
* 特别是两片内存地址没有关系的情况,所以应该需要把内存屏障开了比较安全
* 实际上cache一致性的问题在关掉L2 cache后,一致性问题是在共享DDR级别,速度很慢
* 就是状态变到S,或者M变到E,scu需要刷L1 cache到DDR,而不是L2 cache
* 而使能了L2 cache的话,一致性问题是L2 cache,就完全脱离了DDR了
* 另外根据并行编程里的场景,全局变量赋值,其他cpu可能看不到完整的值,
* 另外即使normal memory和device memory的内存不重叠时,也有可能会乱序。
*/
smp_wmb();
/* 通知CPU1校验 */
semaphore_cpu0_signal();
/* 等待CPU1校验结束,并更新1MB数据过来 */
semaphore_cpu0_wait();
DEBUG_AMP(DEBUG_AMP_INFO, "CPU0 will check 1MB data!\n\r");
smp_rmb();
/* 获取了CPU1的通知,cpu0开始检查cpu1写的1MB共享数据 */
fail = check_data_cpu1_pattern((u8 *)DESTINATION_ARRAY, SHARED_DDR_MEMORY_SIZE_1MB);
if(fail)
{
fmsh_print("CPU0 check cpu1 written data failed!\n\r");
break;
}
else
DEBUG_AMP(DEBUG_AMP_INFO, "CPU0 check 1MB ok!\n\r");
if(round && ((round % 200) == 0) )
fmsh_print("CPU0: has run %u round end!\n\r", round);
round++;
#endif
}
}