1.环境配置
(1)安装依赖的环境
pip3 install -r requirements.txt(2)通过setup.py安装一些库文件
python setup.py develop(3)下载apex文件
下载apex:https://github.com/NVIDIA/apex
将下载好的文件解压到项目根目录下

cd apex-master
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" .(4)下载pycocotools
这个应该都用下载过了,这里就不介绍了~
2.测试tools/demo.py
环境搭建好后,下载官方的预训练模型(https://github.com/Megvii-BaseDetection/YOLOX)
预训练权重的下载链接,在官方代码的说明中。
这里以yolox_s.pth文件,将权重文件放在根目录下进行测试,这里以控制台命令行形式测试(我也是新生,直接修改demo.py中的参数,然后直接运行,总是报错~)。

python tools/demo.py image -f exps/default/yolox_s.py -c ./yolox_s.pth --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu显示如下就表示测试成功,此时的环境也没什么问题,下来就可以进行训练。

YOLOX的代码中,会新建一个YOLOX_outputs文件夹,在其中的yolox_s/vis_res/,可以看到带有检测效果的图片。
效果图:

3.训练tools/train.py(以VOC2007为例)
VOC2007标准数据集结构:
├── Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
├── ImageSets 包含三个子文件夹 Layout、Main、Segmentation,其中 Main 存放的是分类和检测的数据集分割文件
├── JPEGImages 存放 .jpg 格式的图片文件
├── SegmentationClass 存放按照 class 分割的图片
└── SegmentationObject 存放按照 object 分割的图片
├── Main
│ ├── train.txt 写着用于训练的图片名称, 共 2501 个
│ ├── val.txt 写着用于验证的图片名称,共 2510 个
│ ├── trainval.txt train与val的合集。共 5011 个
│ ├── test.txt 写着用于测试的图片名称,共 4952 个
训练准备
修改exps/example/yolox_voc/yolox_voc_s.py文件内容如下:
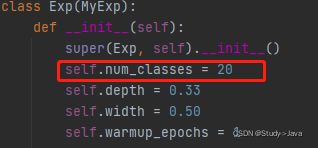
训练:

测试:

如果是自己制作的数据集,还有一些地方需要修改,自行百度。
开始训练:
![]()
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 2 --fp16 -o -c ./yolox_s.pth -d 使用多少张显卡训练
-b 批次大小
-fp16 是否开启半精度训练
-c 权重文件
