“ 我相信有相当大部分人,学习python最初动机,就是做一个网络爬虫,虽然python的主要强项是数据分析方面(至少我是这样认为的),但这并不妨碍它成为目前最主流的网络爬虫编写语言。”
网络爬虫是什么?
——网络上一切看得见的,或看不见的数据,无论是用浏览器还是App或是其他工具打开的,只要是数据,理论上都是通过“数据包”的形式在网络上传播的,爬虫就是用一堆代码,去获取那些数据包,然后把它们解析成我们能看得懂的样子。
好像比较拗口……,再用大白话说一次:爬虫,就是数据获取工具。而且,出于各种原因,大家最好在正式场合不要说“爬虫技术”,而要说“数据获取技术”。
正式开始,先介绍一下python在数据获取方面,我常用的包有哪些:
requests 用于获取页面的原始代码
lxml(etree) 用于对网页标签进行定位,可以解析出需要的数据
bs4(BeautifulSoup) 同上,最早的爬虫包,现在用的少了,但在某些场景还是有它的用处
selenium(webdriver) 模拟浏览器,应付比较多渲染效果、有用户登录或验证码的场景
在掌握了常用的包之后,数据获取的大致流程如下(以获取网站数据举例):
首先了解自己需要的数据是哪些,百度一下这些数据大概都在哪些网站上有,迅速人工浏览一下这些目标网站的首页和内页情况,观察一下页面的复杂程度、是否有大量渲染效果、是否有用户登录、是否需要验证码……等等,然后确定一个最终的目标网站,要求是在拥有我们需要的数据的前提下,数据获取难度相对较小。
用requests(或webdriver)把页面获取下来(如果有渲染、用户登录或验证码,就需要使用相应工具处理后才能获取到),对目标网站的网页代码进行分析,定位出我们需要的数据,并把这些数据用dict类型或list类型组织起来,形成对我们有用的数据包。
把组织好的数据,存到mongoDB或excle、txt文件里面去,方便我们使用。
做完这些,爬虫基本上就做完了。通常一个爬虫代码,只能用于一个网站,我们通常称负责页面解析的代码为“爬虫模板”。网站页面的代码如果发生更新,会导致爬虫模板不能获取到正确的数据,甚至直接报错,需要对爬虫模板进行相应的更新。对于需要持续获取数据的爬虫,这个“博弈”过程会反复出现。
循例,我们还是上一个例子,来简单介绍一下上面的流程:
第一步 确定需求、确定目标网站:
比如,我们需要历史上广州的天气情况数据,我们先百度一下“全国天气历史数据”,我们大概可以找到以下这些网站:
中国天气网:http://www.weather.com.cn/forecast/
IP138天气查询:https://qq.ip138.com/weather/history.htm
天气后报网:http://www.tianqihoubao.com/
……
经过对每个网站进行一些简单的点击,翻看,感觉天气后报网比较适合爬取,就把它确定为目标网站吧。
第二步 直接上代码:
刚开始,我们应该是不知道这个网站是否有什么防爬技术,先用最简单的方法去试试,看能不能work得了
import requestsurl = 'http://www.tianqihoubao.com/lishi/guangzhou/month/201904.html'rs = requests.get(url=url)urlText = rs.textprint(urlText)怀着忐忑的心情运行之,发现输出是这样的:

OK,it works,可以进行下一步工作了(如果没出现这种网页源码,就要尝试一下模拟浏览器了)。
接下来,我们进行页面分析,当我们在浏览器地址栏中输入url地址:
http://www.tianqihoubao.com/lishi/guangzhou.html时,出现以下页面

历史上每个月,是这个页面上的一个链接,如果要获取全部的历史天气记录,我们需要先把这个页面上所有的历史天气链接地址,获取下来,存到一个list类型的变量中。
然后,我们点击某一个月的链接,看看内页的情况,出现以下页面
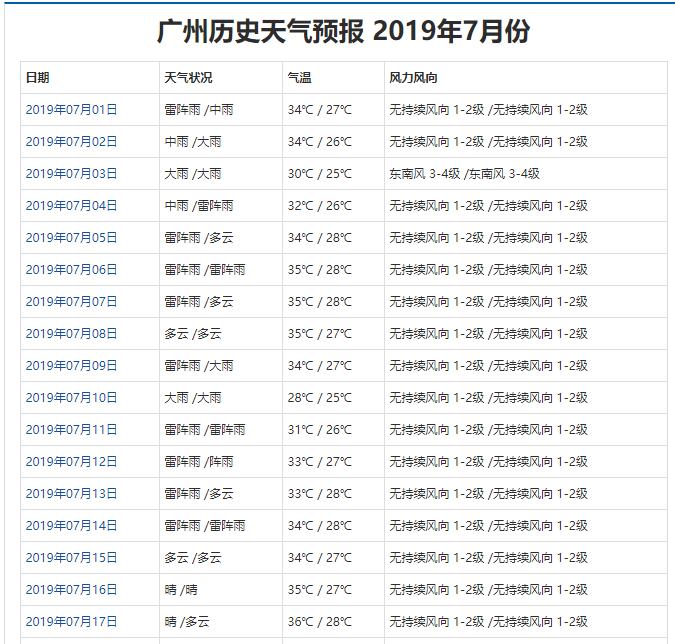
这就是我们要获取的数据了。
在这个页面上,我们按F12(谷歌浏览器),弹出开发者工具,在Elements栏目下,点最左上角的那个小箭头,然后把鼠标移到页面上我们要获取的任意一个数据上面,像这样
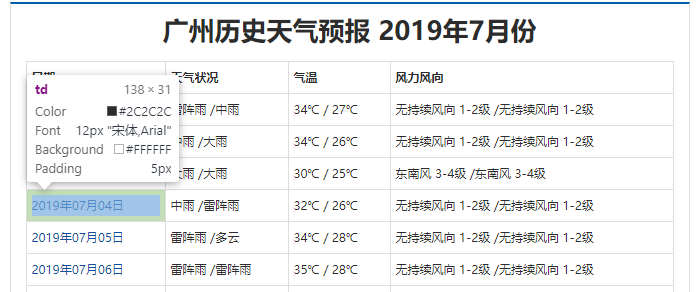
这时,开发者工具的Elements窗口中的内容,就会定位到这个数据元素在页面源代码中的位置,类似这样
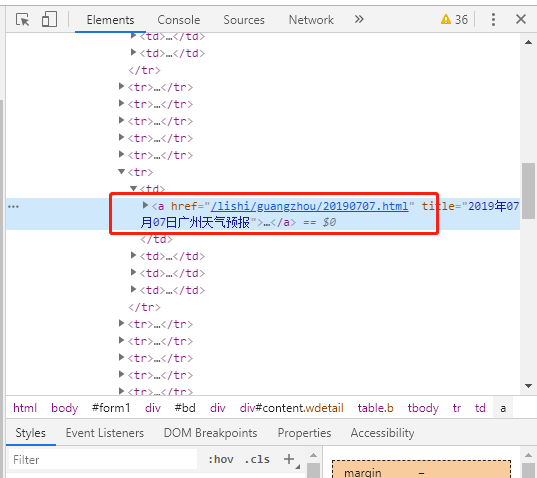
我们发现,这个页面是用table+tr+td的模式排放数据的(这个办法比较老土,居然这个网站还在用O(∩_∩)O),接下来,就可以编写爬虫了。
先去拿每个月的url地址,代码如下:
import requestsfrom lxml import etreeclass My_Spider: def __init__(self): self.base_url = 'http://www.tianqihoubao.com' self.month_home = 'http://www.tianqihoubao.com/lishi/guangzhou.html' def get_month_list(self): rs = requests.get(url=self.month_home) listUrlText = rs.text listUrlTextEtree = etree.HTML(listUrlText) month_list = listUrlTextEtree.xpath("//div[@class='wdetail']/div[@class='box pcity']/ul/li/a/@href") return month_list def get_weather(self): month_list = self.get_month_list() for mon in month_list: month_url = self.base_url + mon print(month_url)if __name__ == '__main__': my_spider = My_Spider() my_spider.get_weather()打印结果如下:
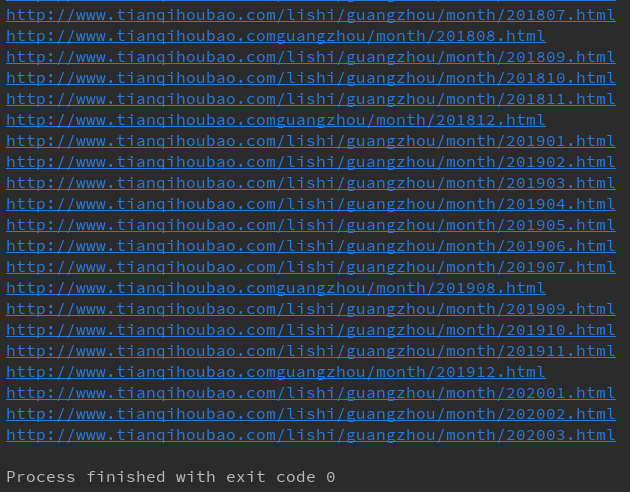
你会发现这些地址有长有短,原因是那些短一些的地址中间少了‘/lishi/’。这种问题,在一些老式的网站上经常出现,要解决它。
完整代码(带详细注释):
# coding:utf-8import requestsfrom lxml import etreeimport pandas as pdclass My_Spider: ''' 定义一个类的初始化函数,在函数中定义两个属性, 1、目标网站的地址,这个在后面有用 2、目标城市的每月天气的地址列表 ''' def __init__(self): self.base_url = 'http://www.tianqihoubao.com' self.month_home = 'http://www.tianqihoubao.com/lishi/guangzhou.html' ''' 定义一个获取目标城市每月天气的地址列表的函数, 返回值是一个list类型的变量,里面是url地址列表(url不完整,将在后面补全) ''' def get_month_list(self): rs = requests.get(url=self.month_home) # 访问url listUrlText = rs.text # 将获得的数据包变成文本形式的网页源码 listUrlTextEtree = etree.HTML(listUrlText) # 将网页源码文本转换成树形结构,方便xpath定位元素 month_list = listUrlTextEtree.xpath("//div[@class='wdetail']/div[@class='box pcity']/ul/li/a/@href") print(month_list) return month_list ''' 进入每日天气列表,并获取每日天气情况 ''' def get_weather(self): month_list = self.get_month_list() b_str = '/lishi/' # 我们发现获得的地址有些缺少这个字符串 weather_group = [] for mon in month_list: month_url = self.base_url + mon # 组合好url地址 # 将不完整的url地址补全 if b_str not in month_url: month_url = self.base_url + b_str + mon print(month_url) rs = requests.get(url=month_url) # 访问url listUrlText = rs.text # 将获得的数据包变成文本形式的网页源码 listUrlTextEtree = etree.HTML(listUrlText) # 将网页源码文本转换成树形结构,方便xpath定位元素 data_body = listUrlTextEtree.xpath("//table/tr") # 获取需要的大的数据区域 for d_body in data_body[1:]: # 去掉第一行表头 item = {} # 获取每一行、每一格数据,组成dict数据包 item['日期'] = d_body.xpath("./td[1]/a/text()")[0].strip().replace('\r\n', '').replace(' ', '') item['天气状况'] = d_body.xpath("./td[2]/text()")[0].strip().replace('\r\n', '').replace(' ', '') item['温度'] = d_body.xpath("./td[3]/text()")[0].strip().replace('\r\n', '').replace(' ', '') item['风力风向'] = d_body.xpath("./td[4]/text()")[0].strip().replace('\r\n', '').replace(' ', '') print(item) weather_group.append(item) # 将数据包放进list类型的变量中 weather_DF = pd.DataFrame(weather_group) # 将获取到的数据,转成数据表 weather_DF.to_csv('广州历史天气.csv', encoding='utf-8-sig') # 数据持久化,即把数据表存成csv文件if __name__ == '__main__': my_spider = My_Spider() my_spider.get_weather()在爬取过程中,在控制台监控程序运行情况,工作正常:
最后,我们存下来的CSV文件打开看一下,确保数据存储完成。
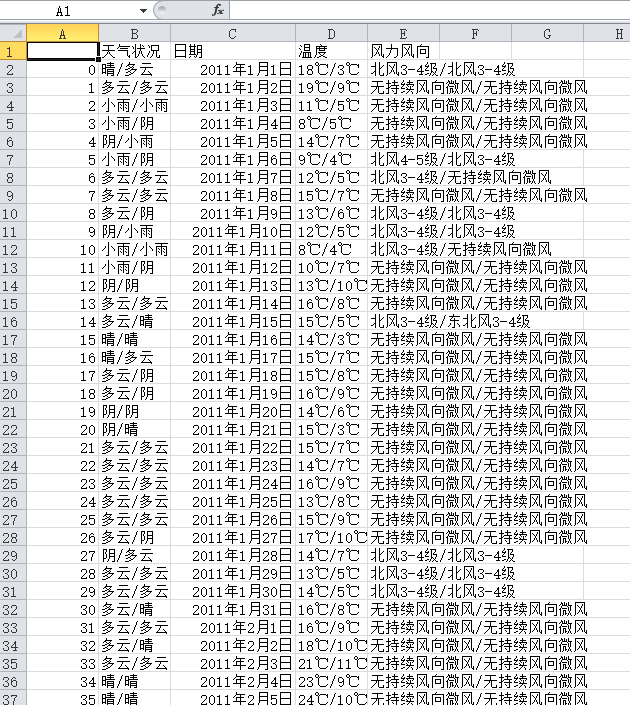
—— 分割线 ——
当然,这是一个比较简单的爬虫,没有复杂的反防爬技术,但制作一个爬虫的基本流程都有了,复杂爬虫只是在每一步上都需要多付出一些劳动而已。
打完收工!看官可满意否?
