之前看过高斯过程(GP),不过当时也没太看懂,最近花时间认真研究了一下,感觉总算是明白咋回事了,本文基于回归问题解释GP模型的思想和方法。文中的想法是自己思考总结得来,并不一定准确,也可能存在错误性。
为什么要用GP?
回顾一下我们之前在解决回归问题时,就拿线性回归举例,我们为了学习映射函数,总是把函数参数化,例如假设
但是有时候我们并不知道数据到底用什么形式的函数去拟合比较好(是1次的,2次的还是10次的?)。这个时候高斯过程(GP)就闪亮登场了,GP说:“我不需要用参数去刻画函数,你就告诉我训练数据是什么,你想要预测哪些数据,我就能给你预测出结果。“这样一来,我们就省去了去选择刻画函数参数的这样一个过程。
GP是怎么来的?
那么GP是怎么做到的呢?我们先来看这样一件有趣的事情:
假设我们的函数定义域和值域都是
然而,事实上虽然很多实际问题(比如房价的预测),它的定义域和值域都是
高斯过程(GP)
下面我们就开始正式的介绍高斯过程(GP),它是怎么得到这个
其中
- 在本次训练中,我们的定义域是
。
- 在这个定义域中,如果
基于核函数是非常接近的,那么你们的输出值也会非常接近。
- 我们是用高斯分布去进行刻画(用高斯的好处,至少有一点条件概率密度函数很好算)。
我们把上面的概率分布展开:
其中
利用高斯分布的性质(通过联合分布计算条件分布),我们可以得到
这样我们计算出了我们希望得到的
- 这一点也是我们上面就说过的,GP是无参的,对于任何一组数据,你不需要知道他的结构是什么,你也不需要去用参数刻画它函数的样子,GP就可以帮你做预测。
- GP它刻画出了函数的概率分布。这个非常有用。回顾之前的线性回归的方法,当你把参数很有信心地给你一个判断。但是,如果你给我一张鸵鸟照片,强迫我说出它是猫还是狗,我就只能信心全无地预测一下。——Yarin Gal。
估计出来后,你的函数就确定了,接下来我拿出任何一个数,你都会“毫无感情的”给我一个预测值。但是GP不一样,当我们知道我们预测函数的不确定度(不确定度很高,这个预测的结果就不可靠)之后,我们能探索最不可能实现高效训练的数据区域。这也是贝叶斯优化背后的主要思想。下面这句话我觉得写得非常贴切:如果你给我几张猫和狗的图片,要我对一张新的猫咪照片分类,我可以
有噪声观测的情况下
在有噪观测的情况下,我们假设观测模型是这样的
核函数参数的影响
那么核函数对GP有什么影响呢,假设我们选择SE核函数:
这个核函数有三个参数,分别是
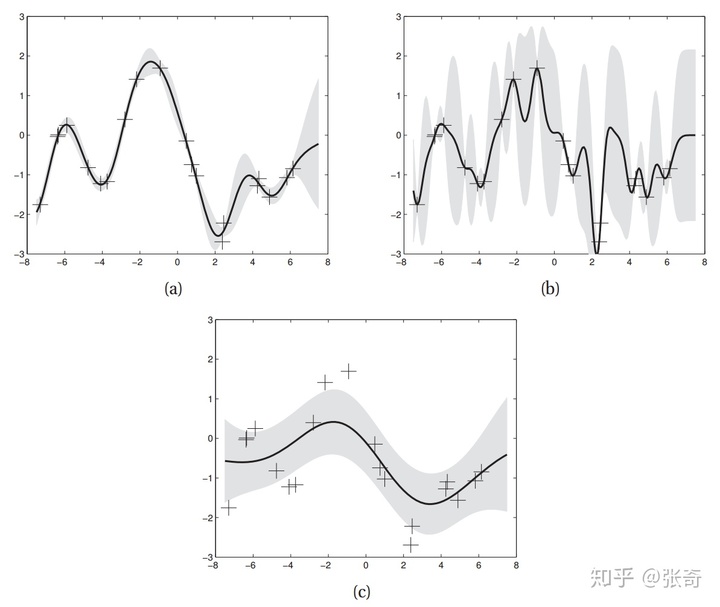
三幅图的超参数
我们可以看到(a)图整体看上去是估计的比较好的,(b)图中,减小了
版权声明:本文为weixin_35521315原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。