本博客主要是摘写洪青阳教授的《语言识别-原理与应用》的笔记,不足之处还请谅解。
语音识别为:根据输入的观察值序列O,找到最可能的词序列W ^ \hat{W}W^。按照贝叶斯准则,识别任务可做如下转化:
W ^ = argmax W P ( W ∣ O ) = arg max P ( W ) P ( O ∣ W ) P ( O ) \hat{W}= {\underset {W}{\operatorname {arg max} }}\,P(W|O)=\arg\,\max\frac{P(W)P(O|W)}{P(O)}W^=WargmaxP(W∣O)=argmaxP(O)P(W)P(O∣W)
其中,P ( O ) P(O)P(O)和识别结果W WW无关,可忽略不急,因此W ^ \hat{W}W^的求解可进一步简化为:
W ^ = arg max W P ( W ) P ( O ∣ W ) \hat{W}={\underset {W}{\operatorname{arg\,max}}}\,P(W)P(O|W)W^=WargmaxP(W)P(O∣W)
要找到最可能的词序列,必须使上式右侧两项的乘积最大。其中,P ( O ∣ W ) P(O|W)P(O∣W)由声学模型决定,P ( W ) P(W)P(W)由语言模型决定。
声学模型就是前面学过的,通过声音进行分析的模型。
语言模型用来表示词序列出现的可能性,用文本数据训练而成,是语音识别系统重要的组成部分,如下图所示。
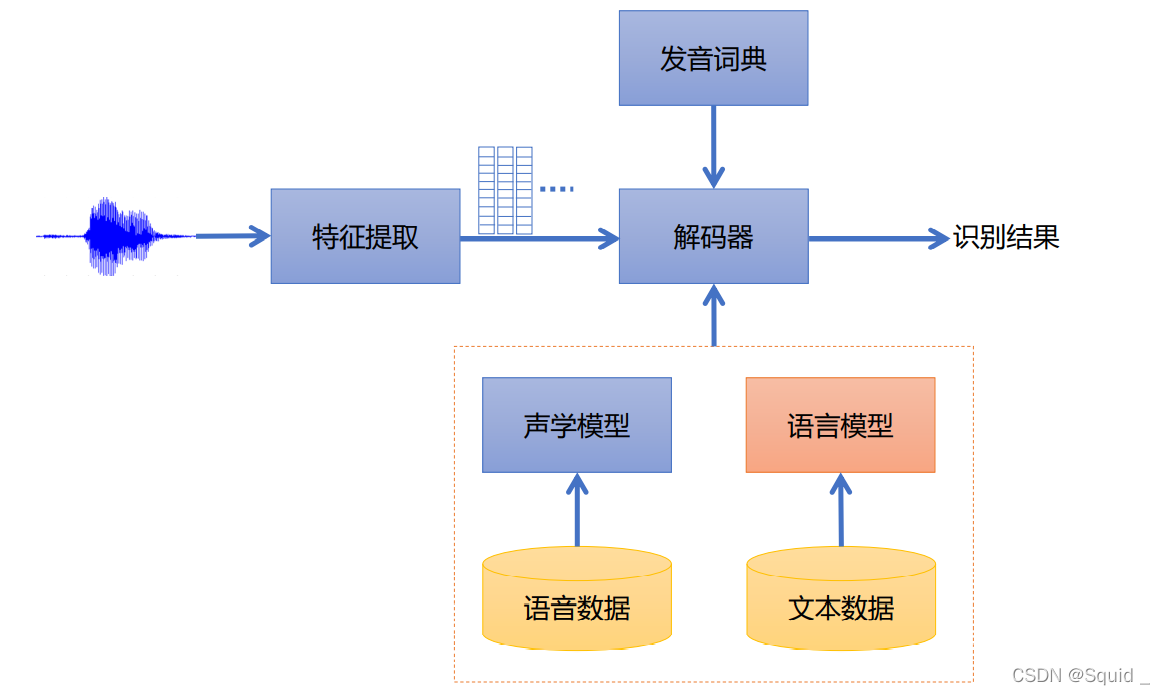
上图即为我们熟知的语音识别框架。
语言模型用来表示词语序列出现的可能性,可以基于语法规则,也可 以基于统计方法。
基于规则的语言模型:来源于语言学家掌握的语言学知识和领域知识,或者根据特定应用设定语法规则,一般仅能约束受限领域内的句子。
统计语言模型:通过对大量文本语料进行处理,获取给定词序列的概率分布,从而能够客观描述隐含的规律,适合于处理大规模真实文本。统计语言模型已被广泛应用于语音识别、机器翻译、文本校对等多个领域。
而要训练一个适用性强的统计语言模型,就需要大量的、不同的、能覆盖用户各种表达方式的文本语料。


所有的句子都有开始位置和结束位置,分别用<s>和</s>表示,可认为这两个特殊标记是两个词。语言模型刻画词与词之间的组合可能性,通过分词,将句子进一步转换为词与词之间的组合概率关系。
即统计语言模型的目标是计算出给定词序列w 1 , ⋯ , w t − 1 , w t w_1,\cdots,w_{t-1},w_tw1,⋯,wt−1,wt的组合概率:
P ( W ) = P ( w 1 w 2 ⋯ w t − 1 w t ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 w 2 ) ⋯ P ( w t ∣ w 1 w 2 ⋯ w t − 1 ) P(W)=P(w_1w_2\cdots w_{t-1}w_t)\\ =P(w_1)P(w_2|w_1)P(w_3|w_1w_2)\cdots P(w_t|w_1w_2\cdots w_{t-1})P(W)=P(w1w2⋯wt−1wt)=P(w1)P(w2∣w1)P(w3∣w1w2)⋯P(wt∣w1w2⋯wt−1)
其中,条件概率P ( w 1 ) , P ( w 2 ∣ w 1 ) , P ( w 3 ∣ w 1 w 2 ) , ⋯ , P ( w t ∣ w 1 w 2 ⋯ w t − 1 ) P(w_1),P(w_2|w_1),P(w_3|w_1w_2),\cdots,P(w_t|w_1w_2\cdots w_{t-1})P(w1),P(w2∣w1),P(w3∣w1w2),⋯,P(wt∣w1w2⋯wt−1)就是语言模型。
计算所有这些概率值的复杂度较高,特别是长句子的计算量很大,因此需做简化,一般采用最多n个词组合的n-gram模型。
n-gram模型
所谓n-gram模型,表示n个词之间的组合概率模型。在n-gram模型中,每个预测变量w t w_twt之与长度为n-1的上下文:
P ( w t ∣ w 1 ⋯ w t − 1 ) = P ( w t ∣ w t − n + 1 w t − n + 2 ⋯ w t − 1 ) P(w_t|w_1\cdots w_{t-1})=P(w_t|w_{t-n+1}w_{t-n+2}\cdots w_{t-1})P(wt∣w1⋯wt−1)=P(wt∣wt−n+1wt−n+2⋯wt−1)
即n-gram预测的词概率值依赖于前n-1个词,更长距离的上下文依赖被忽略。考虑到计算代价,在实际应用中一般取1 ≤ n ≤ 5 1\leq n \leq 51≤n≤5。
当n=1,2和3时,相应的模型分别成为一元模型、二元模型和三元模型。
一元模型和多元模型有明显的区别,一元模型没有引入“语境”,对句子的约束最小,其中的竞争最多。而多元模型对句子有更好的约束能力,解码效果更好。
但相应地,n越大,语言模型就越大,解码速度也越慢。
而语言模型的概率均从大量文本语料估计得到。针对一元模型,可简单地计算词的出现次数。
假设有1000个句子,其中:
- “我们”出现100次,“明年”出现30次,“日子”出现10次,······
- 总共有21000个词标签,其中包括1000个结束符</s>

一元模型的计算如下:
- P(“我们”) = 100/21000
- P(“明年”) = 30/21000
- P(“日子”) = 10/21000
- P(</s>) = 1000/21000
一元模型的示意图如下:

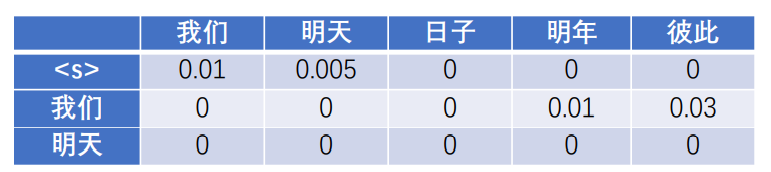
而二元模型的计算如下。假设这1000句语料中出现下面两个词的组合情况如下:
- 10句以“我们”开头,5句以“明天”开头,……
- 2句以“日子”结尾,……
- 1次出现“我们明年”,3次出现“我们彼此”,……
则二元模型计算如下:
- P(“我们”|) = 10/1000
- P(“明天”|) = 5/1000
- P(</s>| “日子”) = 2/10 ,“日子”出现10次
- P(“明年”|“我们”) = 1/100 ,“我们”出现100次
- P(“彼此”|“我们”) = 3/100
得到下表:
所以,二元模型的组合图如下:

三元模型用来表示前后三个词之间的组合可能性,其概率计算公式为
P ( w 3 ∣ w 1 w 2 ) = c o u n t ( w 1 w 2 w 3 ) / c o u n t ( w 1 w 2 ) P(w_3|w_1w_2)=count(w_1w_2w_3)/count(w_1w_2)P(w3∣w1w2)=count(w1w2w3)/count(w1w2)
假设“我们明天”出现2次,“我们 明天 开始”出现1次,则
P ( 开 始 ∣ 我 们 明 天 ) = 1 / 2 P(开始|我们明天)=1/2P(开始∣我们明天)=1/2
当句子只有一个词,例如”是“,其实也表示三个词,即”<s>是</s>“,因此要单独识别"是",也得有这样一个词的句子。
三元模型的概率关系图如下:

评价指标——困惑度
给定句子S,其包含词序列w 1 , w 2 , ⋯ , w T w_1,w_2,\cdots,w_Tw1,w2,⋯,wT,T是句子长度,则困惑度(Perplexity)表示为:
P P L ( W ) = P ( w 1 w 2 ⋯ w T ) − 1 T = 1 P ( w 1 w 2 ⋯ w T ) T PPL(W)=P(w_1w_2\cdots w_T)^{-\frac{1}{T}}=\sqrt[T]{\frac{1}{P(w_1w_2\cdots w_T)}}PPL(W)=P(w1w2⋯wT)−T1=TP(w1w2⋯wT)1
Perplexity又称困惑度(PPL), PPL越小,?(??) 则越大,句子?出现 的概率就越高。
理论上,困惑度越小,语言模型越好,预测能力越强。

平滑技术
由于统计语料有限,会存在数据稀疏的情况,这可能导致零概率或估计不准的问题,因此对语料中未出现或少量出现的词序列,需要采用平滑技术进行简介预测。
平滑技术分为三种:
- 折扣法:从已有观察值概率调配一些给未观察值概率,如Good-Turing(古德-图灵)折扣法
- 插值法:将高阶模型和低阶模型做线性组合,如Jelinek-Mercer插值法,也可做非线性组合,如Kneser-Ney插值法。
- 回退法:基于低阶模型估计未观察到的高阶模型,例如Katz回退法。
Good-Turing折扣法
- 设总词数为N NN,平滑前出现1次的词数为N 1 N_1N1,出现c cc次的词数为N c N_cNc。
- 平滑后,概率P ∗ ( 出 现 0 次 的 词 ) = N 1 N P^*(出现0次的词)=\frac{N_1}{N}P∗(出现0次的词)=NN1,出现次数c ∗ = ( c + 1 ) N c + 1 N c c^*=\frac{(c+1)N_{c+1}}{N_c}c∗=Nc(c+1)Nc+1,对应概率为:P G T = c ∗ N P_{GT}=\frac{c^*}{N}PGT=Nc∗。
例子:
分词后句子语料(假设只有2句):
- “我们 明年 会 有 全新 的 开始”
- “我们 彼此 祝福 着 等待 再见 那 一 天”
词频数:“我们”2次,“明年”1次,……,“天”1次
平滑前: N = 16 , N 1 = 14 , N 2 = 1 N = 16, N_1 = 14 , N_2 = 1N=16,N1=14,N2=1
平滑后:N 0 ∗ = N 1 N = 14 16 , N 1 ∗ = ( 1 + 1 ) N 2 N 1 = 2 14 N^*_0=\frac{N_1}{N}=\frac{14}{16},N^*_1=\frac{(1+1)N_2}{N_1}=\frac{2}{14}N0∗=NN1=1614,N1∗=N1(1+1)N2=142
对应的概率为:P 0 ∗ = N 1 N = 14 16 , P 1 ∗ = c 1 ∗ N = 2 14 ∗ 16 P^*_0=\frac{N_1}{N}=\frac{14}{16},P^*_1=\frac{c^*_1}{N}=\frac{2}{14*16}P0∗=NN1=1614,P1∗=Nc1∗=14∗162
Jelinek-Mercer插值法
为了避免出现P ( w ) = 0 P(w)=0P(w)=0或接近于零的情况,可以用三元、二元和一元相对概率做插值。
P ^ ( w t ∣ w t − 2 w t − 1 ) = λ 1 P ( w t ∣ w t − 2 w t − 1 ) + λ 2 P ( w t ∣ w t − 1 ) + λ 3 P ( w t ) \hat{P}(w_t|w_{t-2}w_{t-1})=\lambda_1P(w_t|w_{t-2}w_{t-1})+\lambda_2P(w_t|w_{t-1})+\lambda_3P(w_t)P^(wt∣wt−2wt−1)=λ1P(wt∣wt−2wt−1)+λ2P(wt∣wt−1)+λ3P(wt)
其中λ 1 + λ 2 + λ 3 = 1 \lambda_1+\lambda_2+\lambda_3=1λ1+λ2+λ3=1。
Kneser-Ney插值法
当训练数据非常少的情况下,特别适合采用Kneser-Ney 插值法。Kneser-Ney 是一种非线性插值法,从Absolute discounting(绝对折扣)插值方法演变而来。
Absolute discounting
Absolute discounting方法充分利用高阶和低阶语言模型,把高阶的概率信息分配给低阶的一元模型。例如,针对二元语言模型,Absolute discounting平滑公式表示如下:
P a b s ( w t ∣ w t − 1 ) = m a x ( c ( w t − 1 w t ) − d , 0 ) ∑ w ′ c ( w t − 1 w ′ ) + λ P a b s ( w t ) P_{abs}(w_t|w_{t-1})=\frac{max(c(w_{t-1}w_t)-d,0)}{\sum_{w'}c(w_{t-1}w')}+\lambda P_{abs}(w_t)Pabs(wt∣wt−1)=∑w′c(wt−1w′)max(c(wt−1wt)−d,0)+λPabs(wt)
其中c ( w t − 1 w ′ ) c(w_{t-1}w')c(wt−1w′)表示w t − 1 w ′ w_{t-1}w'wt−1w′的组合次数,w ′ w'w′是任意一个词,d dd是固定的一个折扣值,λ \lambdaλ是一个规整容量。P a b s ( w t ) P_{abs}(w_t)Pabs(wt)是一元模型,按单词出现次数统计。
但P a b s ( w t ) P_{abs}(w_t)Pabs(wt)可能会存在异常偏大现象。比如“杯子”出现频次较高,因此单独的“杯子”按出现次数可能会比 “茶”多,即P a b s ( 杯 子 ) > P a b s ( 茶 ) P_{abs}(杯子) > P_{abs}(茶)Pabs(杯子)>Pabs(茶) ,这样会使Absolute discounting平滑公式因P a b s ( w t ) P_{abs}(w_t)Pabs(wt)值过大出现“喝杯子”比“喝茶”概率高的奇怪现象。
Kneser-Ney
Kneser-Ney插值法对此做了改进,平滑公式如下:
P K N ( w t ∣ w t − 1 ) = m a x ( c ( w t − 1 w t ) − d , 0 ) ∑ w ′ c ( w t − 1 w ′ ) + λ ∣ { w t − 1 : c ( w t − 1 , w t ) > 0 } ∣ ∣ { w j − 1 : c ( w j − 1 , w j ) > 0 } ∣ P_{KN}(w_t|w_{t-1})=\frac{max(c(w_{t-1}w_t)-d,0)}{\sum_{w'}c(w_{t-1}w')}+\lambda\frac{|\{w_{t-1}:c(w_{t-1},w_t)>0\}|}{|\{w_{j-1}:c(w_{j-1},w_j)>0\}|}PKN(wt∣wt−1)=∑w′c(wt−1w′)max(c(wt−1wt)−d,0)+λ∣{wj−1:c(wj−1,wj)>0}∣∣{wt−1:c(wt−1,wt)>0}∣
其中λ \lambdaλ是规整的常量,d dd是固定的一个折扣值,w j − 1 w j w_{j-1}w_jwj−1wj是任意两个词的组合。第一部分的分母可进一步表示为一元模型统计,因此Kneser-Ney 平滑公式还可简化为:
P K N ( w t ∣ w t − 1 ) = m a x ( c ( w t − 1 w t ) − d , 0 ) c ( w t − 1 ) + λ ∣ { w t − 1 : c ( w t − 1 , w t ) > 0 } ∣ ∣ { w j − 1 : c ( w j − 1 , w j ) > 0 } ∣ P_{KN}(w_t|w_{t-1})=\frac{max(c(w_{t-1}w_t)-d,0)}{c(w_{t-1})}+\lambda\frac{|\{w_{t-1}:c(w_{t-1},w_t)>0\}|}{|\{w_{j-1}:c(w_{j-1},w_j)>0\}|}PKN(wt∣wt−1)=c(wt−1)max(c(wt−1wt)−d,0)+λ∣{wj−1:c(wj−1,wj)>0}∣∣{wt−1:c(wt−1,wt)>0}∣
Katz回退法
采用Katz平滑技术的概率估计公式如下:
P ( w t ∣ w t − 2 w t − 1 ) = { C ( w t − 2 w t − 1 w t ) C ( w t − 2 w t − 1 ) , 当 C > C ′ d C ( w t − 2 w t − 1 w t ) C ( w t − 2 w t − 1 ) , 当 0 < C < C ′ b a c k o f f ( w t − 2 w t − 1 ) P ( w t ∣ w t − 1 ) P(w_t|w_{t-2}w_{t-1})= \begin{cases} \frac{C(w_{t-2}w_{t-1}w_t)}{C(w_{t-2}w_{t-1})}, &当C>C'\\ d\frac{C(w_{t-2}w_{t-1}w_t)}{C(w_{t-2}w_{t-1})}, &当0<C<C'\\ backoff(w_{t-2}w_{t-1})P(w_t|w_{t-1}) \end{cases}P(wt∣wt−2wt−1)=⎩⎪⎨⎪⎧C(wt−2wt−1)C(wt−2wt−1wt),dC(wt−2wt−1)C(wt−2wt−1wt),backoff(wt−2wt−1)P(wt∣wt−1)当C>C′当0<C<C′
其中C CC是C ( w t − 2 w t − 1 w t ) C(w_{t-2}w_{t-1}w_t)C(wt−2wt−1wt)的简写,表示三个词同时出现的次数,C ′ C'C′是一个计数阈值,当C > C ′ C>C'C>C′时,直接采用最大似然方法估计概率;当0 < C < C ′ 0<C<C'0<C<C′时,则采用Good-Turing折扣法,d dd是折扣系数。
b a c k o f f ( w t − 2 w t − 1 ) backoff(w_{t-2}w_{t-1})backoff(wt−2wt−1)是回退权重,回退权重的计算如下:
b a c k o f f ( w t − 2 w t − 1 ) = 1 − ∑ P ( w ∣ w t − 2 w t − 1 ) ∑ P ( w ′ ∣ w t − 2 w t − 1 ) backoff(w_{t-2}w_{t-1})=\frac{1-\sum{P(w|w_{t-2}w_{t-1})}}{\sum{P(w'|w_{t-2}w_{t-1})}}backoff(wt−2wt−1)=∑P(w′∣wt−2wt−1)1−∑P(w∣wt−2wt−1)
其中w ww是在训练语料中w t − 2 w t − 1 w_{t-2}w_{t-1}wt−2wt−1之后出现的词,w ′ w'w′是在训练语料中w t − 2 w t − 1 w_{t-2}w_{t-1}wt−2wt−1之后未出现的词。
采用Katz回退法,训练好的语言模型格式如下:

其中,p r o _ 1 pro\_1pro_1是一元模型(1-grams)单词的对数概率,p r o _ 2 pro\_2pro_2是二元模型(2-gram)的对数概率,p r o _ 3 pro\_3pro_3是三元模型(3-gram)的对数概率。一元模型和二元模型后面分别带有回退权重b a c k _ p r o 1 back\_pro1back_pro1和b a c k _ p r o 2 back\_pro2back_pro2。
如果要得到三个词出现的概率P ( w 3 ∣ w 1 w 2 ) P(w_3|w_1w_2)P(w3∣w1w2),则根据以上的语言模型,其计算如下:

即,如果不存在( w 1 w 2 w 3 ) (w_1w_2w_3)(w1w2w3)的三元模型,则采用回退法,即结合回退权重b a c k _ p r o 2 ( w o r d 1 , w o r d 2 ) back\_pro2(word1,word2)back_pro2(word1,word2)来计算:
b a c k _ p r o 2 ( w o r d 1 , w o r d 2 ) ∗ P ( w o r d 3 ∣ w o r d 2 ) back\_pro2(word1,word2)*P(word3|word2)back_pro2(word1,word2)∗P(word3∣word2)。如”拨打 郑州 局“这样的组合,如果语料库里没有,即没有相应的三元模型,则查找“拨打 郑州”和“郑州 局”的组合概率和回退概率(概率均为对数概率)。假设值如下:

则
P ( 拨 打 , 郑 州 , 局 ) = P ( 局 ∣ 拨 打 , 郑 州 ) = b a c k _ p r o 2 ( 拨 打 , 郑 州 ) ∗ P ( 局 ∣ 郑 州 ) = l n ( e − 0.4072262 ∗ e − 3.012735 ) = − 3.4199612 P(拨打,郑州,局)=P(局|拨打,郑州)=back\_pro2(拨打,郑州)*P(局|郑州)=ln(e^{-0.4072262}*e^{-3.012735})=-3.4199612P(拨打,郑州,局)=P(局∣拨打,郑州)=back_pro2(拨打,郑州)∗P(局∣郑州)=ln(e−0.4072262∗e−3.012735)=−3.4199612
语言模型的训练

SRILM
- SRILM由SRI实验室开发,诞生于1995年,包括最大似然估计和平滑算法。
- SRILM主要有两个工具:ngram-count和ngram,用来估计语言模 型和计算困惑度。
递归神经网络语言模型(RNNLM)
?-gram语言模型一般只能对前3-5个词建模,存在局限性。
针对任意长度的句子,我们可采用递归神经网络(RNN),使用 循环连接对上下文依赖关系进行建模。

这里的RNN模型的内部函数最好另外学习了,能更详细点。