一. 唐诗项目介绍
1.1项目背景
爬虫技术一直处于风口浪尖,爬了不该爬的会引来一身官司,爬想爬取的数据又不会轻而易举获得,但是又想来玩玩爬虫技术,怎么办呢?首选古诗文网,因为据了解它是没有设置任何反爬虫机制的,数据都是公开合法的,这里我就选择了唐诗三百首来进行爬虫,你们不好奇哪位唐代诗人写的诗最多吗?你们不好奇诗人们最喜欢用什么词去作诗吗?如果你对唐诗也感兴趣,那就跟我一起开启这个奇妙的诗词探险吧。
1.2项目需求
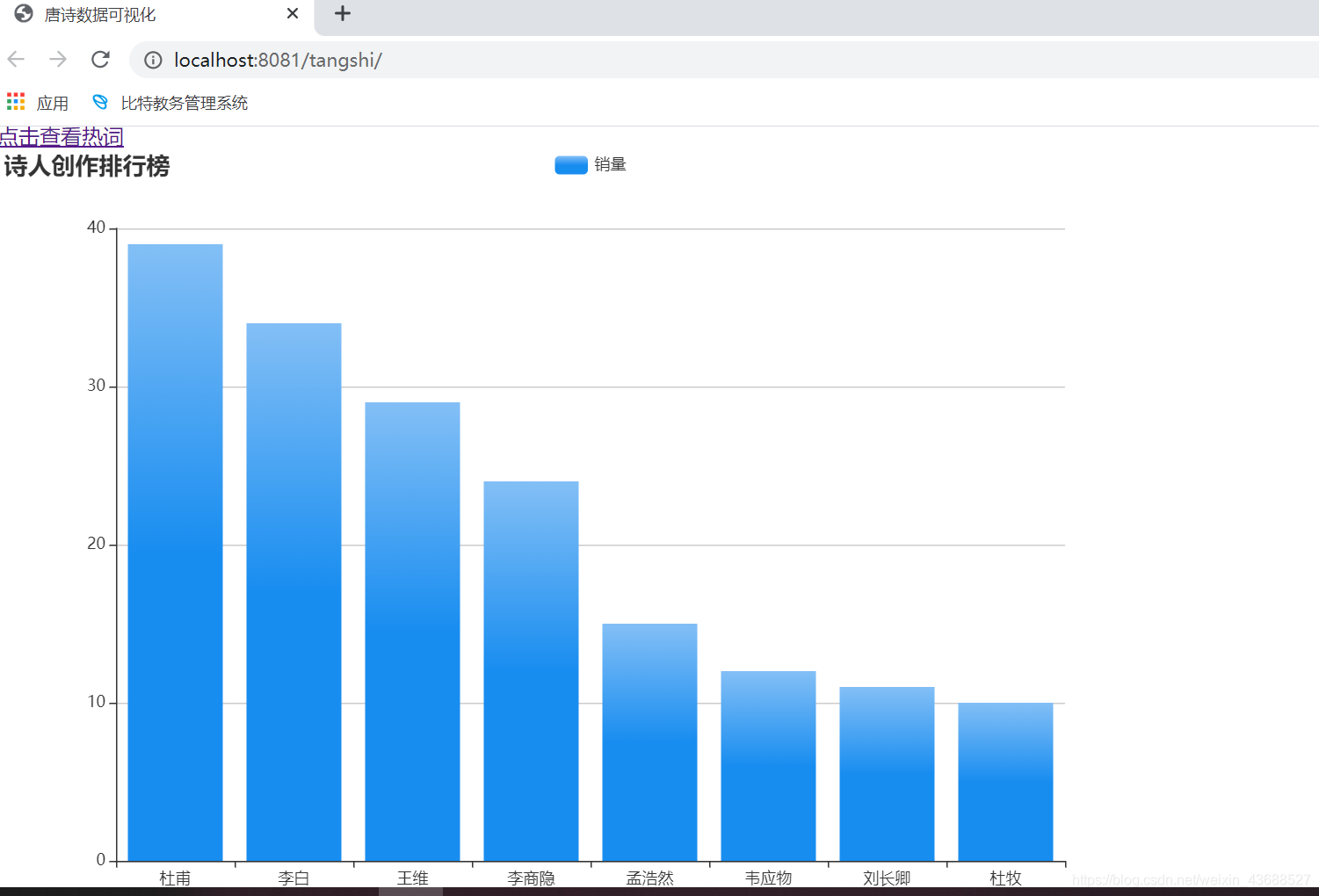
一.用柱状图来展示诗人们的姓名和诗词数量,并按诗词数量降序排序。
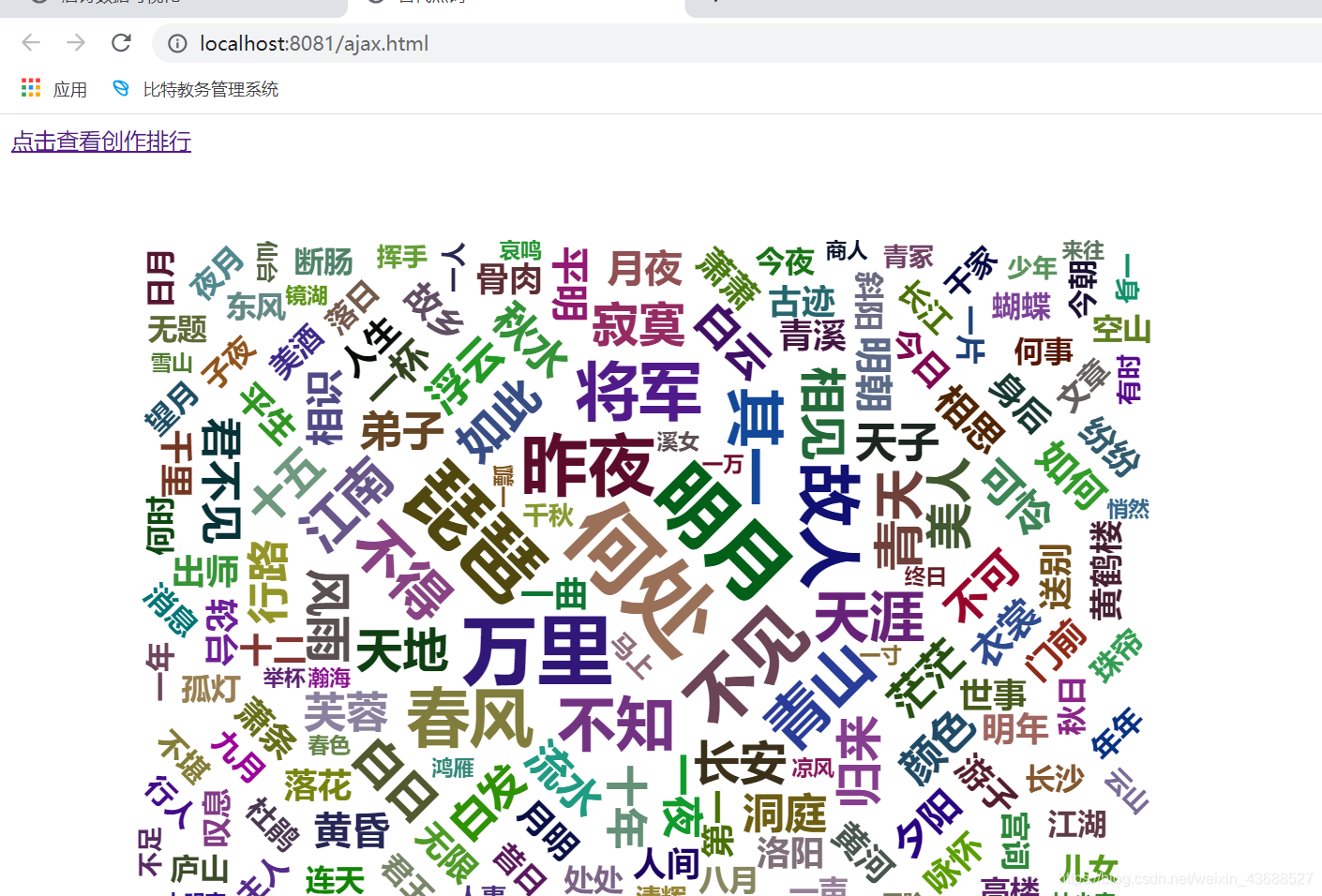
二.用词云来展示词的使用频度,使用最频繁的词应该一眼看出。
1.3项目设计
一.通过爬虫机制把唐诗的数据爬取出来,对它进行解析,将每首诗的数据写入到数据库中。
二.通过发起请求来对数据进行分析筛选,最后渲染成可视化效果。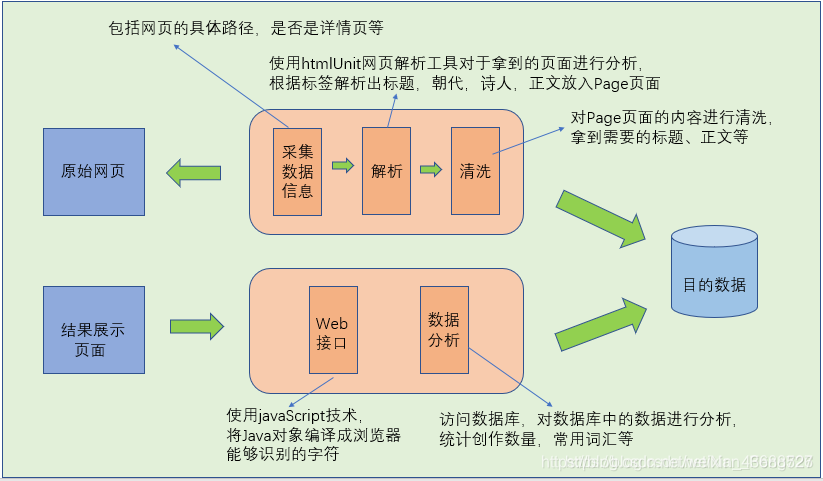
1.4项目工具选择
这是一个Web项目,Java选择用IDEA这个编译器,选择用maven来引进一些需要用到的第三方库,通过tomcat这个Web应用服务器来执行。
二.唐诗数据爬取模块
2.1技术选型环节
2.1.1爬虫技术
我了解到的爬虫技术栈有 HtmlUnit,HttpClient,这里我选择了HtmlUnit这个框架。
- 原因:HttpClient是用来模拟HTTP请求的,用的是socket通信,通过get方法来提交请求,只能获取html静态页面的源码,如果页面中有js部分,则不能获取到js执行后的源码。
HtmlUnit是一款无界面的浏览器程序库,它模拟用户去操作浏览器,允许调用页面,填写表单,点击链接等,还可以执行js,有很多的API用起来也非常方便。
2.1.2分词技术
使用ansj_seg库对古诗的标题和正文进行分词,为词云做准备。这个中文分词器正确率高,不容易出做,分词速度也快,效果也比较高。
2.2项目依赖环节
解析请求html页面
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.36.0</version>
</dependency>
分词
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
2.3预研环节
通过编写一些Demo来熟悉这些技术的使用,看看它展示的效果是否满意。
2.3.1解析列表页Demo
WebClient client = new WebClient(BrowserVersion.CHROME);
client.getOptions().setJavaScriptEnabled(false);
client.getOptions().setCssEnabled(false);
String baseurl = "https://so.gushiwen.org";
String pathurl = "/gushi/tangshi.aspx";
List<String> detailUrlList = new ArrayList<>();//所有古诗的详情页的url
//列表页的解析
{
String url = baseurl + pathurl;
HtmlPage page = client.getPage(url);//获取诗词页面
List<HtmlElement> divs = page.getBody().getElementsByAttribute("div", "class", "typecont");
for (HtmlElement div : divs) {
List<HtmlElement> as = div.getElementsByTagName("a");
for (HtmlElement a : as) {
String detailUrl = a.getAttribute("href");
detailUrlList.add(baseurl + detailUrl);
}
}
}
2.3.2分词Demo
public static void main(String[] args) {
String sentence="中华人民共和国成立了!中国人民从此站起来了";
List<Term> termlist=NlpAnalysis.parse(sentence).getTerms();
for(Term term:termlist){
System.out.println(term.getNatureStr()+":"+term.getRealName());
}
}
2.4具体开发环节
2.4.1数据库的设计
数据库要存取:自增主键id,标题,朝代,作者,正文,分词,sha-256。
- SHA-256是为了防止下载重复诗词,所以用每首诗的标题和正文去计算SHA-256值。
CREATE TABLE `tangpoetry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sha256` char(64) NOT NULL,
`dynasty` varchar(10) NOT NULL,
`title` varchar(100) NOT NULL,
`author` varchar(10) NOT NULL,
`content` text NOT NULL,
`words` text NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `sha256` (`sha256`)
) ENGINE=InnoDB AUTO_INCREMENT=703 DEFAULT CHARSET=utf8mb4
2.4.2爬取,解析数据
- 获取列表页解析出每首诗的url
- 解析详情页得出要往数据库中写入的数据(标题,朝代,作者,正文,计算SHA-256,计算分词(切记分词要去除特殊字符,比如符号,null等)需要将分词拼接成字符串格式,方便存储)
2.4.3数据写入到数据库中
- 通过JDBC建立数据库连接,将标题,朝代等信息插入到数据库的表中。
2.4.4验证并优化—多线程
*通过sql语句查看320首诗词数据是否成功写入到数据库中。如果信息无误,则插入成功。
- 单线程版本效率低,每次都是主线程去完成各项任务,在解析详情页的时候每次都是主线程,而总共有320首诗,就要挨个去解析320次,非常耗时。
- 引入多线程版本:让主线程去获取列表页,解析列表页,得出每首诗的url,开启多个线程,去完成列表页解析工作,并将数据写入到数据库中。
问题:1.webclient不是线程安全的,每个线程都得自己建一个webclient对象
2.connection不是线程安全的,需要通过传
datasource这个参数去建立连接。
3.MessageDigest这个计算SHA-256的也不是线程安全的。
多线程每次都要创建320个子线程去执行任务,执行完再销毁,显然有点浪费资源。 - 线程池版本:这里用的是Executors.newFixedThreadPool(30)这个固定数目的线程池,把多线程要处理的那些任务去交给线程池里面的线程去完成,这里我设置的是30个核心线程。
BUG: JVM结束是指所有非后台线程执行结束后才关闭,而线程池一直在主线程中,根本不可能自己关闭,它会不断地去执行任务,重复的死循环,永不停止。
解决办法: 只要等所有子线程都完成任务,就可以手动关闭线程池。 - 如何判断子线程任务是都都结束了呢?
1.CAS原子类
private static AtomicInteger successCount=new AtomicInteger(0);
private static AtomicInteger failureCount=new AtomicInteger(0);
private static class Job implements Runnable{
private void work() throws IOException, InterruptedException {
Random random=new Random();
int n=random.nextInt(5);
if(n<2){
throw new IOException();
}
Thread.sleep(5);
}
@Override
public void run() {
try{
work();
//successCount++;
successCount.getAndIncrement();
}catch (IOException e){
//failureCount++;
failureCount.getAndIncrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
for(int i=0;i<COUNT;i++){
Thread thread=new Thread(new Job());
thread.start();
}
while(successCount.get()+failureCount.get()!=COUNT){
Thread.sleep(1000);
System.out.println("任务还没完成");
}
System.out.println("任务全部完成");
}
2.CountDownLatch:开始会设定要等待的线程数,主线程阻塞,每执行完一个子线程就调用countDown(),此时计数器-1,直到计时器为0时才将主线程唤醒,不为0 就一直await(),为0说明子线程任务都执行完了,就可以关闭线程池了。
CountDownLatch countDownLatch = new CountDownLatch(detailUrlList.size());//指定countDownLatch要等待的线程数
for (String url : detailUrlList) {
pool.execute(new Job(url,dataSource2,countDownLatch));
}
countDownLatch.await();//如果没处理结束,就等待
pool.shutdown();//最后关闭线程池
}
2.5总结问题
- 在创建数据库的时候,要合理的设计每个字段的类型,不能盲目浪费资源。
- 多线程设计,一定要考虑线程安全问题,不然出大错。
- 学会不断地优化项目。
三.诗词可视化分析模块
3.1技术选型
3.1.1 echarts可视化
echarts是一个开源免费的javascript可视化库,柱状图和词云都是来自于它。而且它是开源的,中文文档,方便上手。
3.1.2 jquery的发起ajax请求
因为echarts的数据是写死的,所以使用jquery来发起ajax请求,用httpservlet来处理请求,返回一个json格式的字符串,等加载成功执行success方法去进行可视化,这样数据就是从请求响应获取的,不再是写死的。
3.1.3 FastJson格式
返回Json格式的第三方库有很多,比如Gson,FastJson等,我选择FastJson主要是因为写起来简单,是阿里巴巴维护的,我这个应用小,也估计碰不到它的BUG。
3.2导入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
3.3代码开发
3.3.1 JDBC建立数据库连接
这里用的是饿汉的设计模式,来进行数据库连接。
3.3.2 整理诗的数量
- 继承HttpServlet,通过doGet方法来处理ajax发起的http请求,用复合查询sql语句就可以搞定,再将数据写入到JSONArray中,返回一个Json格式的字符串。
SELECT author, count(*) AS cnt FROM tangpoetry GROUP BY author HAVING cnt >=? ORDER BY cnt DESC;
- 用@WebServlet(“rank.json”)来配置path路径,就不需要去web.xml去配置servlet了。
- 发起ajax请求,收到响应后去执行success里面的方法,进行柱状图的渲染。
method: "get", // 发起 ajax 请求时,使用什么 http 方法
url: "rank.json?condition=10", // 请求哪个 url
dataType: "json", // 返回的数据当成什么格式解析
success: function (data) { // 成功后,执行什么方法
通过html页面的script标签找到js文件去执行。
3.3.3 整理分词
- 继承HttpServlet,通过doGet方法处理请求,将分词都先放入到list中,再用map来整理每个词出现的次数,最后将Key和Value来放入到JSONArray中,返回一个json格式的字符串。
- 同样用@WebServlet("/words.json")
3.4验证效果